I meant this curve of the LR Finder.
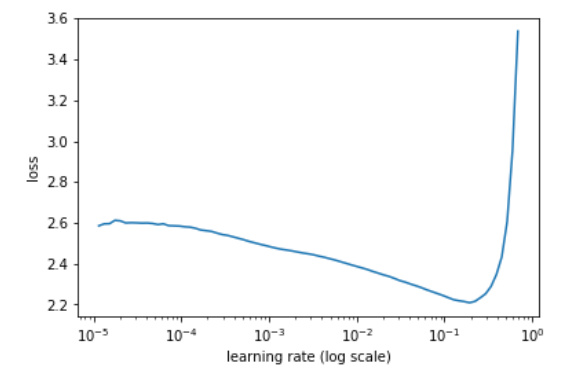
Though looking back at it, the minimum is at 0.2, not 0.3
I haven’t been using data augmentation at all in those experiments, since he doesn’t mention it.
I meant this curve of the LR Finder.
Though looking back at it, the minimum is at 0.2, not 0.3
I haven’t been using data augmentation at all in those experiments, since he doesn’t mention it.
So it seems I finally found the version of resnet-56 used in the tests: it’s indeed the one with the batchnorm immediately after the conv layers and not after the addition of the shortcut. I think the version I was initially using is called preact resnet.
I tried twice and got the 92% accuracy both times with the parameters Leslie indicated in his paper, which with the new use_clr_beta, is done with:
learn.fit(0.8,1,cycle_len=95,wds=1e-4,use_clr_beta=(10,13.68,0.95,0.8))
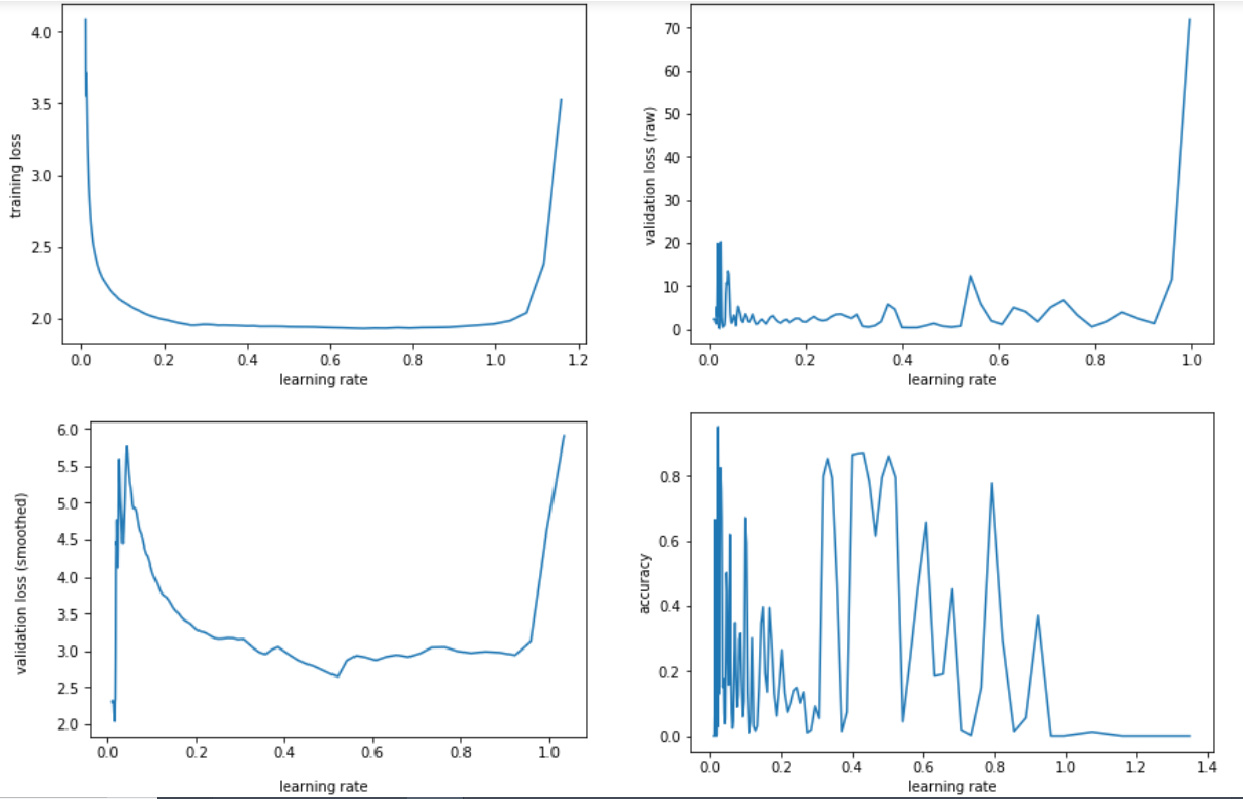
To see how Leslie picked the 0.8, I’ve run the learning rate finder, and a customized version to also track the validation loss and accuracy. Our standard plot is
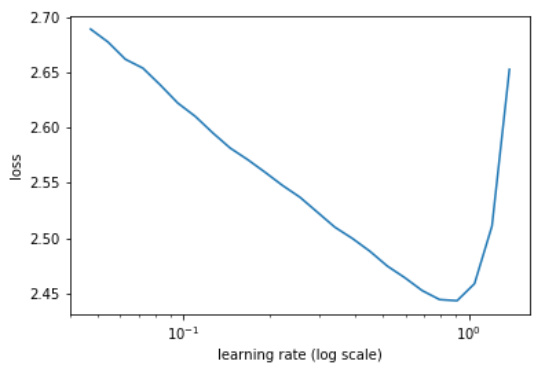
where we can see that 0.8 is the value at the minimum (that or 0.9 which would probably work as well). To add more info I’ve plotted the validation loss, its smoothed version (with the same formulas as the test loss) and the accuracy versus the learning rate
We can clearly see there is something happening between 0.8 and 1, and all the plots seem to be equivalent so the learning rate finder should be good to pick the best value. Good practice would then be to fit for 1 cycle with cyclical LRs and cyclical momentums, and rising the length of the cycle if there is signs of early divergence.
What is amazing during the training is that the model only slightly overfits during the whole period of high learning rate: up until epoch 60-70, the difference between validation loss and test loss is almost constant at 0.2. As a comparison, training with lower learning rates is overfitting starting epoch 20 or so.
I’m trying to see if I can replicate the experiment where the LR could go as high as 3 without diverging but it seems that to go higher than the best value of LR found with the LR finder, one has to be lucky.