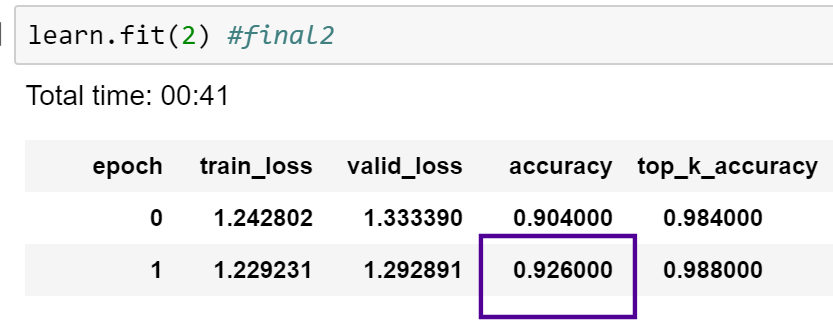
I spent the weekend working on trying to beat the highest accuracy I could find (97% & 96%) on the NIH malaria dataset…
and along the way came up with a ‘new’ (to my knowledge) data augmentation that helped me get to 98% on the malaria dataset.
My intuition behind this ‘progressive sprinkles’ augmentation was b/c cutmix simply wouldn’t work for the malaria dataset. If you clipped the clean half of an infected cell, and showed that, there is nothing the CNN could learn from to tell it that it was infected. Therefore it was pointless to use that or RICAP as they would mislead it.
I tried with mixup and got reasonable results, but not SOTA, and also tried with the usual transforms (flips, etc). The argument against mixup is that it can create artifacts in some places where things overlap that are not present in either photo…however, both mixup and cutmix outperform the older standard cutout.
Cutout, in its original form of a single big block blacked out, could seriously also ruin an image by cutting out the infected part of a cell and give the same result (telling the CNN this visibly clean cell was infected).
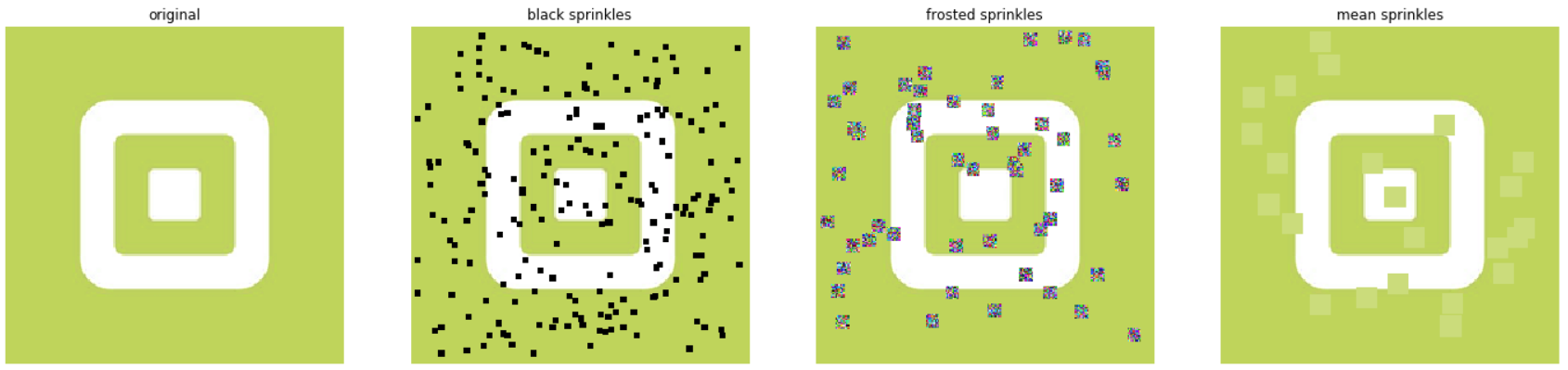
Take a look at cutout in it’s normal form…a big black box (middle, cutmi and mixup also shown on each siide as comparison):

However, if you take a random grid/series of small squares, and randomly sprinkle those on the image, and slowly increase their probability and sizes, then you can force the CNN to look more completely at the entire image for classification clues, while at the same time, in most cases, avoid blocking out enough data that would block it from truly learning.
Like this:

(And if you don’t know, cutout is already a transform in fastai! With tunable sizes/probability,etc.)
Here’s how it looks of course without sprinkles:

I then combined the concept of curriculum learning from the dropout paper where they showed starting with no dropout and increasing it on a slow gradient produced more robust CNN’s then just keeping dropout fixed or ‘stepping’ it in large increases.
Thus, I started with no sprinkles and then slowly increased probability, frequency, and size as training progressed of the sprinkles.
The result was the best I was able to get after two days of working on it - 98% (repeatedly), and higher than the original malaria paper with a custom built CNN (96%), and several other articles (96 in custom Keras and 97%…with fastai!).

I did the progression by hand so I’m going to next write up a callback that will help automate it across training runs and post that out if anyone is interested. I’d like to test this new sprinkle augmentation on ImageNette as well to see how it compares vs cutmix, ricap, etc.
My other idea is possibly changing from black cutouts to partially see-through (i.e. reduced opacity) and see if that helps as it would allow for another aspect of learning (less clear, but structure would still show to some degree).
Anyway, I was happy to be able to take an idea and run it through it’s paces and have it perform nicely at least on this data set. And thanks to @sgugger and @xnutsive for putting cutout in as an augmentation!
 As in, using noise instead of a constant black or dataset mean value.
As in, using noise instead of a constant black or dataset mean value.