It seems that google has change the html for the google images page! This results in that the code presented in lesson 2 (bear classifier) for retrieving image urls from google images is not working anymore… I got around this problem by a slight modification of the JavaScript code
function imurl(el) { let a = el.getAttribute(“data-iurl”); if (a == null) { return el.getAttribute(“src”); } else { return a; } };
urls = Array.from(document.querySelectorAll(‘.rg_i’)).map(el=>(imurl(el))); window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(‘\n’)));
Also has anyone else noticed some problems with the ImageCleaner? It seems like it’s not writing all the file-paths it should to the csv file (deleting images that should not be deleted).
I just used an image downloader from the chrome store. However, I still hope there will be a person comes here to give us a new code. ImageCleaner does not work for colab.
EDIT: the code above had an error in that the new line ‘\n’ was escaped so the join was just adding “/n” instead of creating a new line. The correct code is below:
I’ve left my original problems below, just in case anyone finds sed useful. But its now solved.
I then have two problems: Chrome is blocking the pop up window for saving so I can’t specify a file name. It just downloads the file as “download” into my Downloads folder.
Secondly the “download” file has literal '\n’s in it - not new lines. So it isn’t read as a CSV with many lines - just as one really long line.
I use Linux and got around this with the following:
sed -'s/\\n/\n/g' download > newfilename.txt
This turned my one line download file into a newfilename.txt file with a new line for each url. There is good documentation for sed if you type info sed into the terminal.
This is a bit clunky by by coming up with an alias I can at least rename and reformat the url file in a short line of code in my terminal.
If anyone else has a more elegant solution I’d love to hear it!
ohhh, the quotation marks got messed up! Thanks for telling.
I then have two problems: Chrome is blocking the pop up window for saving so I can’t specify a file name. It just downloads the file as “download” into my Downloads folder.
Hmm, It could be that you just have to rename the file with eg .txt at the end, so it knows which filetype to cast to it.
I don’t belive it’s necessary to do the ‘\n’ fix you propose. This is because the image_downloader function split the links on the ‘\n’ anyway, so it doesn’t matter that it’s not shown as a newline
I still can’t get your javascript to work in my console. BUT - I’ve figured out what was wrong in my javascript code. I had ‘//n’ which was escaping the /n hence getting the entire file on one line. (I did try adding .txt and .csv extensions to the file name originally). Hey-ho - at least I’ve learnt about sed and got a bit better at noticing/using the escape character!
It worked in mine, when i changed all the quotation marks. I wanted to edit in your code in my first post, but i can’t figure out how… the edit button seems to have disappeared.
Hey-ho - at least I’ve learnt about sed and got a bit better at noticing/using the escape character!
That’s the spirit! Every day we get a little bit better!
If you click on the link you sent, is the image showing? Because it does for me. If the image is showing the image_downloader function should have no problem retriving the images for you.
For last two days i was looking into alternative method
method 2:
finally I got https://serpapi.com/
But it was headache because it contains JSON Object finally i made a python script to make a url_file.csv
Edit:
Thanks For getting my attention , Sorry buddy! There is a big mistakes on my side Downloaded csv File contains Whitespaces
So, Existing method works Fine (what they taught on fast ai)
Yes you are right, that is what I meant It’s hard for me to tell why it fails… Could you provide a little more information, like what the URLs you’re feeding it looks like?
I checked the problem, it originates from this line and it seems download_images method reads CSV file, splits it with “\n” to read line by line, but does not filter empty strings in the string array.
urls = open(urls).read().strip().split("\n")[:max_pics]
Changing this to filtering as below will fix this issue. urls = list(filter(None, open(urls).read().strip().split("\n")))[:max_pics]
I will create a PR from my fork where I already fixed.
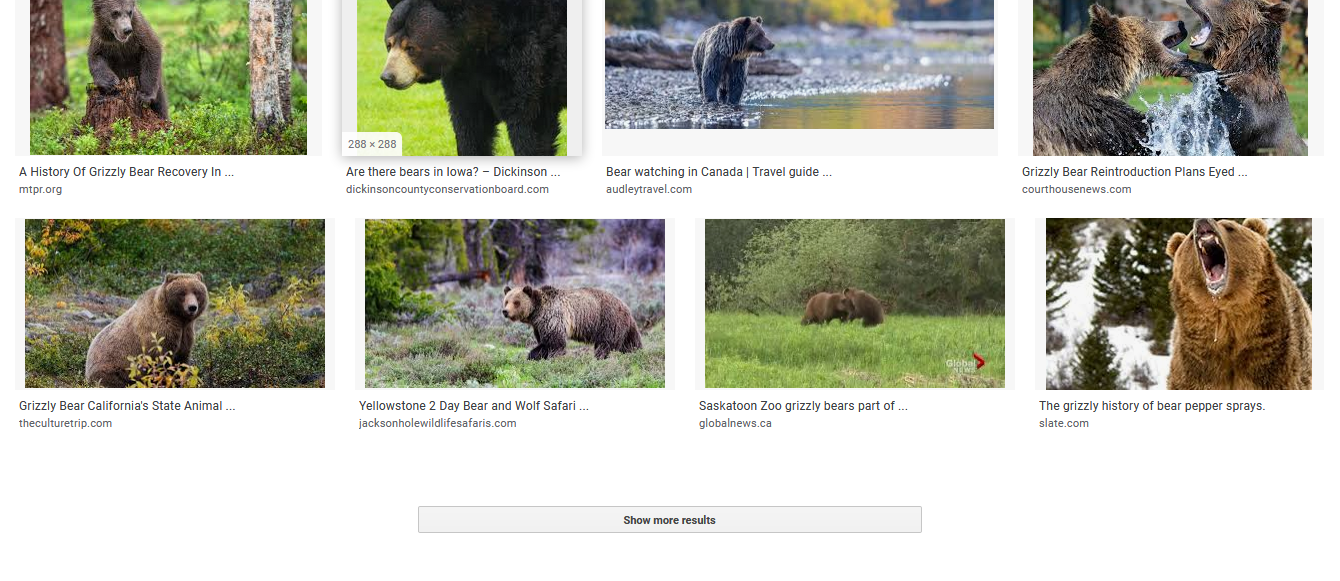
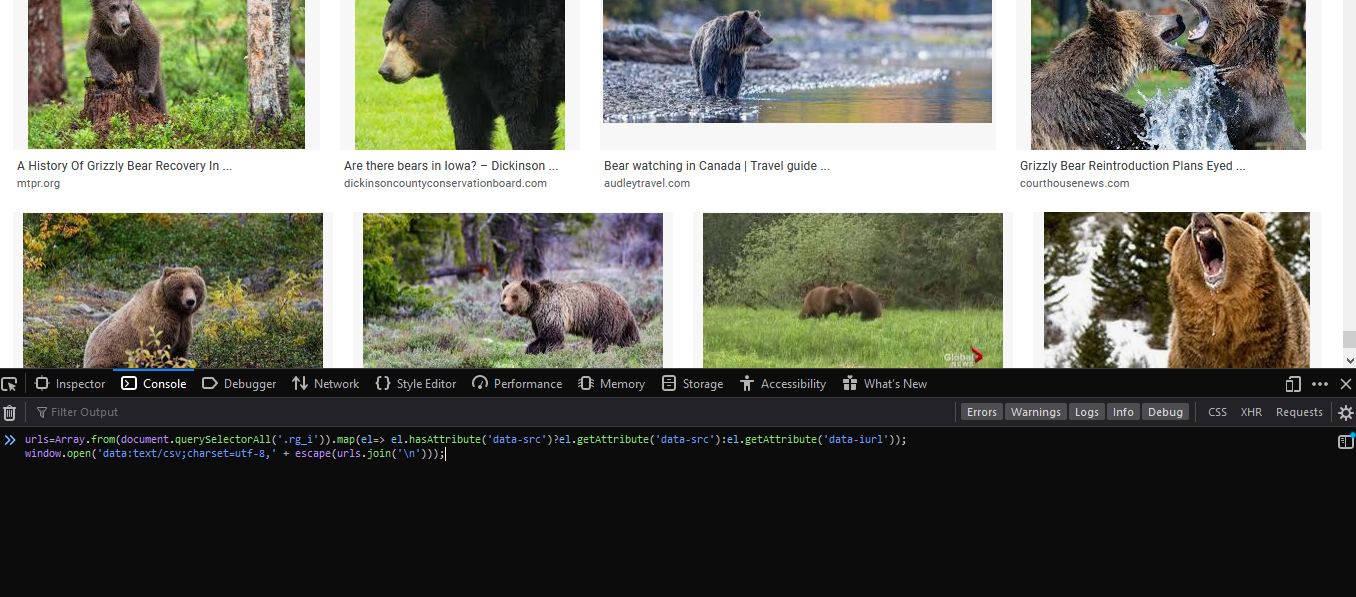
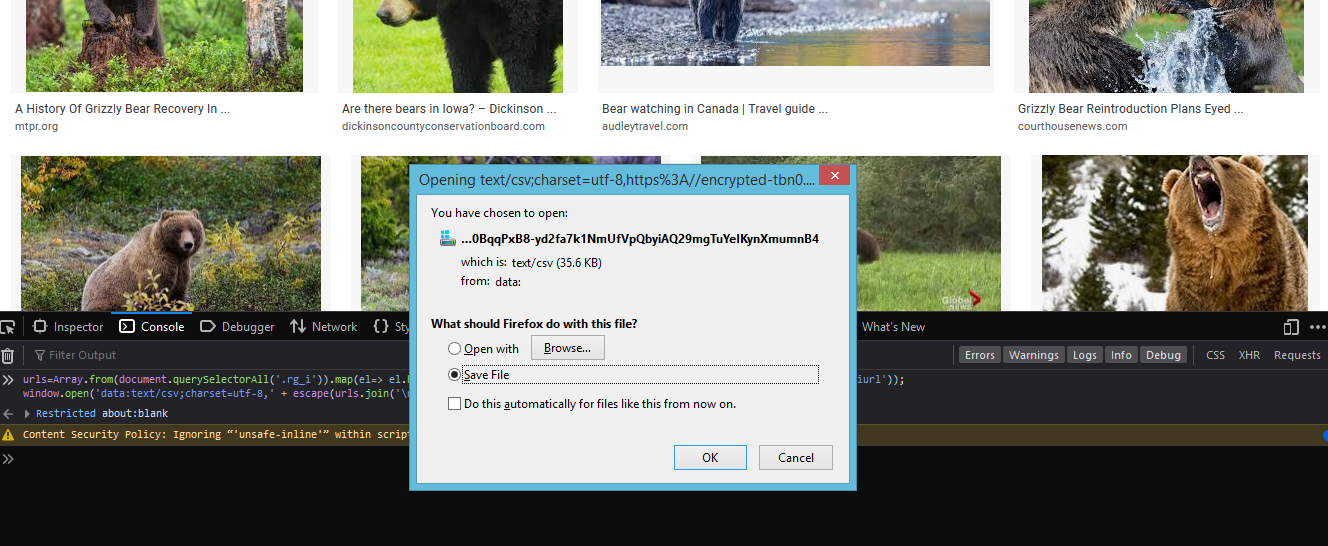
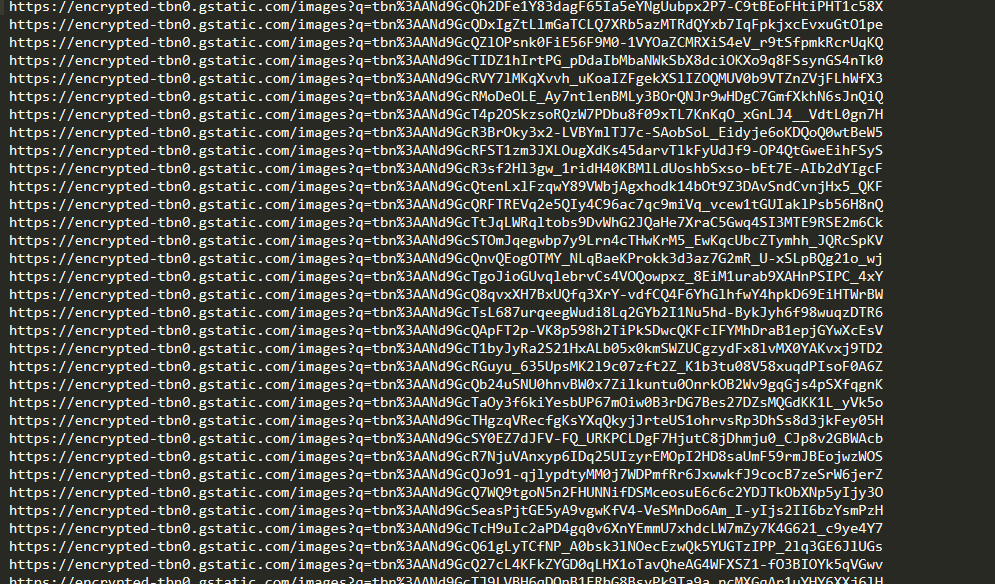

 It’s hard for me to tell why it fails… Could you provide a little more information, like what the URLs you’re feeding it looks like?
It’s hard for me to tell why it fails… Could you provide a little more information, like what the URLs you’re feeding it looks like?