thank buddy,it’s a great help.I just cann’t get the urls file,it’s always 0 byte.your answer fix my problem,thank you so much.
I’m not familiar with javascript, could you please tell me more about your thought about fixing this problem,thank you again
That javacript snippet is looking for any html element that have the css class “.tx8vtf”. In my experiments, the image elements from google images have that css class. I check this by using the google chrome plugin SelectorGadget https://selectorgadget.com/ which highlights all elements on the page which have the css selector you are looking for. Check out the video on their page for more info.
After you determine you have the right css selector (.tx8vtf in my example), the javascript code finds all of them and extracts the url that you can then use to download the images.
If the count of urls is 0, then experiment with changing the css class you use to select the images.
Hope this helps.
Hello,
You can all follow this tutorial on how to download your image data sets from Bing.
I compiled into a script with slight modification where you can use it as follow:
$ python download_images.py -q “serach query” -o <dest_dir> -m <result_size> -g <group_by> -k <bing_API_KEY>
from requests import exceptions
import argparse
import requests
import cv2
import os
ap = argparse.ArgumentParser()
ap.add_argument("-q", "--query", required=True,
help="search query to search Bing Image API for")
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
ap.add_argument("-m", "--max", required=True,
help="maximum number of results")
ap.add_argument("-g", "--group", required=True,
help="group number of results")
ap.add_argument("-k", "--apikey", required=True,
help="bing api key")
args = vars(ap.parse_args())
API_KEY = args['apikey']
MAX_RESULTS = int(args['max'])
GROUP_SIZE = int(args['group'])
URL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search"
EXCEPTIONS = set([IOError, FileNotFoundError,
exceptions.RequestException, exceptions.HTTPError,
exceptions.ConnectionError, exceptions.Timeout])
term = args["query"]
headers = {"Ocp-Apim-Subscription-Key" : API_KEY}
params = {"q": term, "offset": 0, "count": GROUP_SIZE}
print("[INFO] searching Bing API for '{}'".format(term))
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS)
print("[INFO] {} total results for '{}'".format(estNumResults,
term))
total = 0
for offset in range(0, estNumResults, GROUP_SIZE):
print("[INFO] making request for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
params["offset"] = offset
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
print("[INFO] saving images for group {}-{} of {}...".format(
offset, offset + GROUP_SIZE, estNumResults))
for v in results["value"]:
try:
print("[INFO] fetching: {}".format(v["contentUrl"]))
r = requests.get(v["contentUrl"], timeout=30)
ext = v["contentUrl"][v["contentUrl"].rfind("."):]
p = os.path.sep.join([args["output"], "{}{}".format(
str(total).zfill(8), ext)])
f = open(p, "wb")
f.write(r.content)
f.close()
except Exception as e:
if type(e) in EXCEPTIONS:
print("[INFO] skipping: {}".format(v["contentUrl"]))
continue
image = cv2.imread(p)
if image is None:
print("[INFO] deleting: {}".format(p))
os.remove(p)
continue
total += 1
2 Likes
how may i import your version of fastai with the fix?
You got that right! I just did a read_csv to see for myself. Interestingly enough read_csv removes these blank lines by default. The image is a result of changing skip_blank_lines to False.

1 Like
Thanks Buddy, it helped me as well, I am new to programming do I need to type in wget -i urls in lesson 2 notebook after above script or somewhere else. Please help.
Hey guys,
I encountered similar challenges downloading images from Google search, but I found a way to make it work, sharing below.
Once you scroll down to the end of the page, you can paste this function into console and run saveToCSV('fileName.csv').
saveToCSV = (fileName) => {
// Run this after scrolling to the bottom
const urls = Array.from(document.querySelectorAll('.rg_i'))
.map(el => el.hasAttribute('data-src') ?
el.getAttribute('data-src') : el.getAttribute('data-iurl'));
// Filter urls that might be null
const filteredUrls = urls.filter(u => u !== null);
console.log(`Saving ${filteredUrls.length} urls`);
// Save Blob to File Name
const pom = document.createElement('a');
const blob = new Blob([filteredUrls.join('\n')], {
type: 'text/csv;charset=utf-8;'
});
const url = URL.createObjectURL(blob);
pom.href = url;
pom.setAttribute('download', fileName ? fileName : 'download.csv');
pom.click();
}
This will also attempt to remove the null links retrieved. I have tested this in the latest version of Chrome. I hope this helps.
Hello all,
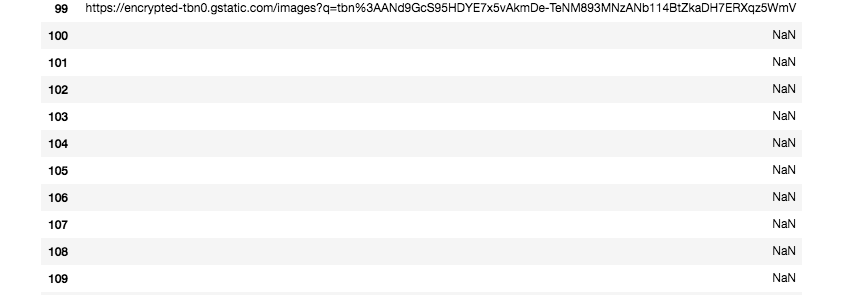
So the first 20 images in images.google.com have data urls. So, even if I save these data urls to my csv, download_images() is not able to download it and giving me an error. Since the first 20 images are the most accurate images it would be great to have them in the dataset. How to solve this?
This is the csv file:
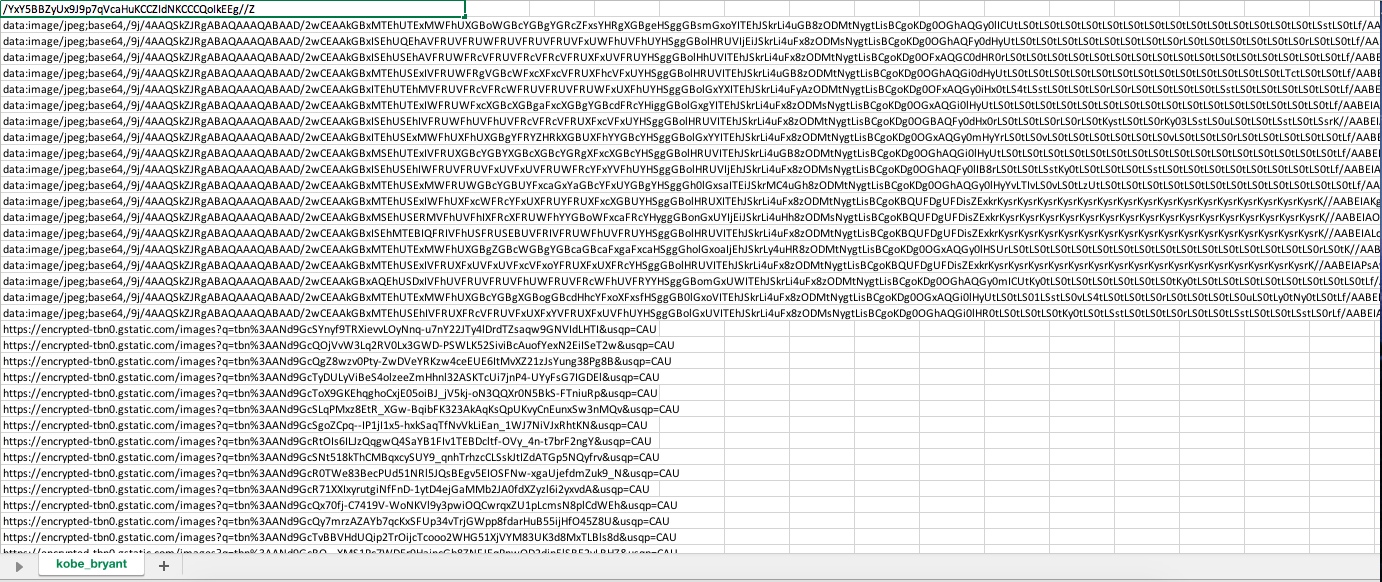
This is the error by download_images()
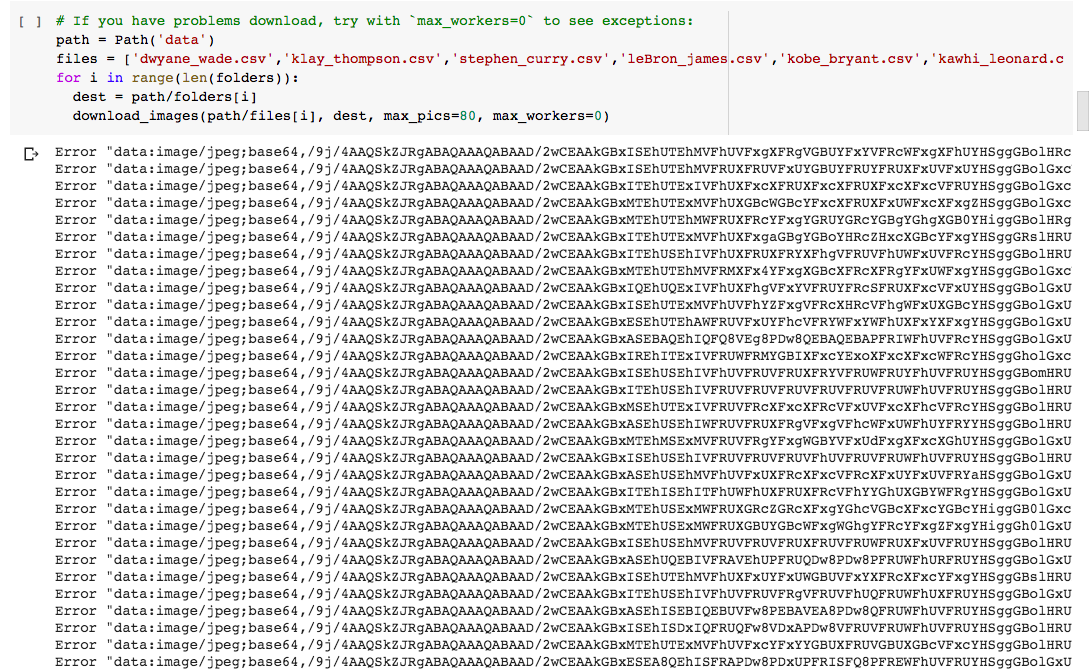
I’m really stuck trying to get URLs from the google image page.
1.) The actual image is an embedded one, no source.
2.) The “src” attribute in the caption is 99% a reference to a full web page from which the image was taken, not an actual image. When I try uploading the image all I get is a placeholder icon.
Don’t really know where to go from here, or how anyone else has made this work?! What am I missing?
Hi!
I created an example notebook that download images from duckduckgo  Try it!
Try it!
link: https://github.com/Adrianbakke/Extract-images-ddg
2 Likes
Thanks - duckduckgo is much more friendly than google images
When using the java code from the lesson2_download.ipynb, I get the following error. The issue seems to be with the window.open command. I’m using chrome on a Mac, and I am not sure what the issue is or how to fix it  Any advice?
Any advice?

This is really cool. Thank you.
possibly a pop-up blocker or an ad blocker? they do say to make sure you’ve disabled them.
in case it helps anyone else, i was having a completely different problem downloading urls because i’ve only got access to a tablet where i am so i couldn’t pop open a javascript console.
i knocked up a quick notebook, it scrapes the urls from google, downloads them, auto-deletes anything corrupt which won’t open, lets you delete anything you decide doesn’t belong and zips it up.
the image cleaner is very slow with lots of images but it’s still far less painful than trying to do it on my tablet. YMMV.
https://colab.research.google.com/drive/1F9YpbiQAAThlk09BjN_r7XSNQSMJ98Xd?usp=sharing
feel free to help yourself to any part of that which may be useful to you.