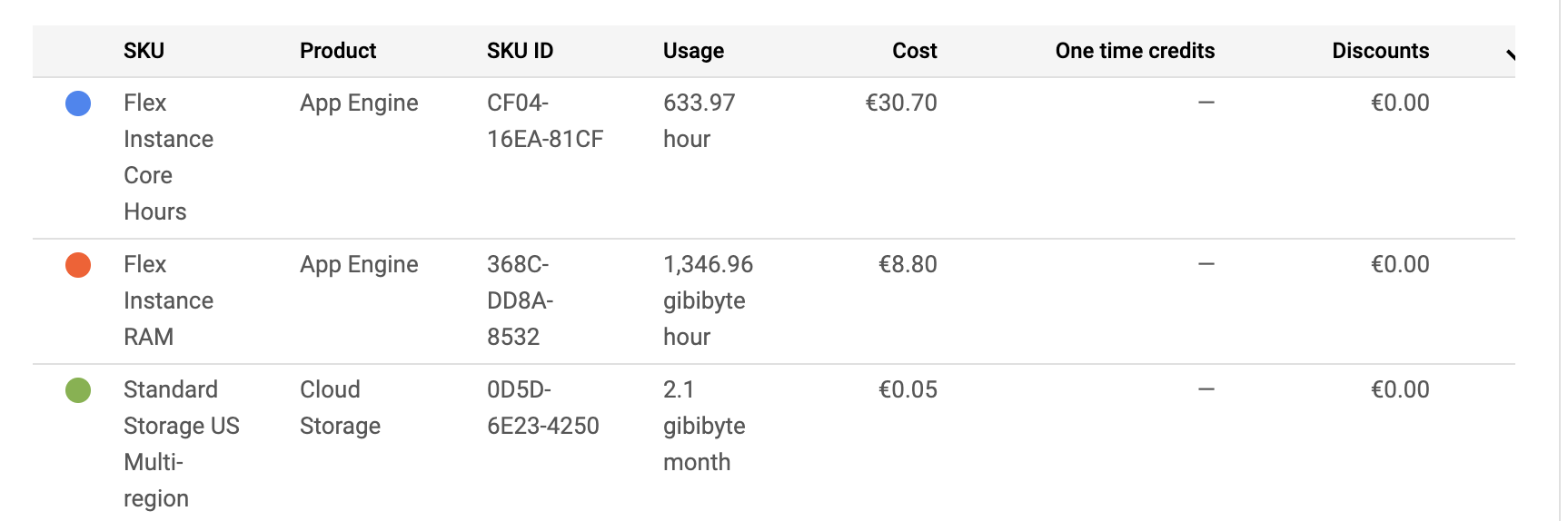
I just deployed a basic fastai web-app on Google App Engine (source code on github), and it’s costing me ~10$/day. This seems a lot to me and I wonder how I could reduce the bill… In particular, I’m pretty sure that I have almost zero human traffic on my web app, so I don’t understand why it would cost so much.
I tried looking at Google’s cost dashboards, but it’s very hard to get details on what is causing exactly the cost to be this high:
Does someone have any tip for reducing the cost of a deployment on Google? In particular, is there any recommended app.yaml that should be used (the one in fastai’s tutorial gave me an “memory error”, maybe because I’m using fastai v2)?
ERROR: (gcloud.compute.ssh) Could not fetch resource:
- Invalid value '“name_of_your_fastai_instance”'. Values must match the following regular expression: '[a-z](?:[-a-z0-9]{0,61}[a-z0-9])?|[1-9][0-9]{0,19}'
This shows up every time I run: gcloud compute ssh --zone=$ZONE jupyter@$INSTANCE_NAME -- -L 8080:localhost:8080
Hi all!
Excited to start my first real Deep Learning course. Recently, I set up my GCP server and connected using Windows Ubuntu to access the Jupyter notebook. Everything worked fine.
But this week I noticed that the default configurations do not work anymore. This might be due to GCP new changes in zones and available machine types.
When I run gcloud compute instances create with defaults, I get the error: Machine type with name 'n2d-highmem-8' does not exist in zone 'us-west1-b'
So I changed my zone to us-central1-f export ZONE="us-central1-f"
Now I get the second error: [n2d-highmem-8, nvidia-tesla-p100] features are not compatible for creating instance.
Changing nvidia-tesla-p100 to nvidia-tesla-t4 does not solve the problem: [n2d-highmem-8, nvidia-tesla-t4] features are not compatible for creating instance.
So I removed the accelerator altogether and now it works.
Hello @priyank7, I think we spoke in Slack on Sunday?
Anyway, I initially ran into the same issues as you did. Eventually I worked through it using GCP documentation that lists what combination of zone, number of GPUs and Machine types are allowed together.
Also, an easier way to get started if you are okay with using Jupyter Lab, is the following:
Go to Navigation -> AI Platforms -> Notebooks, and create a notebook instance. The process is intuitive and guided, using GCP’s GUI.
The above process will ALSO create a VM Instance in Google Cloud Compute, which you can later SSH into if you want to use Jupyter Notebook instead of Jupyter Lab.
Now I use Jupyter Lab for most of what I do, but switch over to Notebook when I run into incompatibilities (like when I want to use ImageCleaner). It’s a nice way to get to know GCP with training wheels.
I managed to create an instance US-central1-f or something like that, suggested by other in this forum. Thanks. By that is not N2D-highmem-8. n1-standard-1 (1 vCPU, 3.75 GB memory)
I tried it out with lesson-one pet nb, but it was very slow. The memory is not enough to run the one cycle fit, even after I lower the batch size. My theory is that people are using the resources for the crisis, especially for preemptible instance. I would love to hear someone share their successful story, experience or advice. Thanks.
@priyank7
Is your setup working?
I use gcloud compute list machine-types list and gcloud compute accelerator-types list
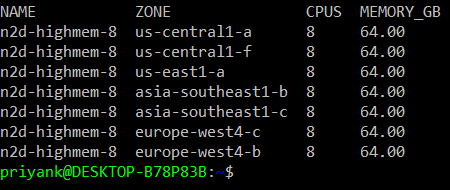
I found a list of zones for n2d-highmem-8
US-central1-a. east1-a. asia-south east1-b,c, europe-west4cb, all are exclusive from the list of zones for Tesla P100 accelerator. I may try and see the change of availability in different times. Other than that. Any other suggestions? What can be other alternatives?
Hi Everyone I am running into the same issue as above my @priyank7. I couldn’t spin up the instance with the following problem [n2d-highmem-8, nvidia-tesla-p100] features are not compatible for creating instance. Also, I found this on GCP’s documentation for Machine Types - Caution: N2D machine types do not support GPUs, sole tenant nodes, or nested virtualization. Is there something that has changed in 2020. Can anyone direct me to a link that has worked in spinning up the instance on GCP. I appreciate it. Thanks.
Thank you for your suggestions Wesley! Of course, I checked the link that you have provided. But my question is: What combination will allow n2d-highmem-8 to work with Tesla P100?
I am using Jupyter Notebook instead of Jupyter Lab and no, we did not speak on Slack
As of now, I haven’t been able to find a solution and I am running the instance without any accelerator (us-central1-f). Looking at the time it takes for me and for the instructor (from the video clips), I would say there is not much difference but maybe a drop of 10-20% in computation power without an accelerator.
New Question
Is an n1-highmem-8 with an nvidia-tesla-p100 sufficent for this course? If not then I think Google Compute Platform is no longer a viable option for fast.ai
If this is the case then I’d advise it be removed from the list of possible cloud providers to save new students the trouble of figuring this out on their own. Any pointers of next steps or obvious things I’m overlooking would be very much appreciated.
You are right Mikey. I spun up mine with n1-highmen-8 instead of n2d-highmem-8 and the rest of the configuration is the same. I have been through the notebook of lesson 1 and the setup is working fast enough for now.
Hey, I am also facing the same problem but when I try to increase the quota for all region my request keeps on getting denied. I have upgraded my account but still I am getting this error - “Unfortunately, we are unable to grant you additional quota at this time. If
this is a new project please wait 48h until you resubmit the request or
until your Billing account has additional history. Your Sales Rep is a good Escalation Path for these requests, and we highly recommend you to reach out to them.” in the email response for quota increase request.
Did you face the same problem and was it solved by waiting 48 hours?
It’s seeming like the solution here is to use the n1-highmen-8 instances instead of n2d-highmem-8. It turns out the n2d instances don’t work as described in the docs. (As many of us have discovered!)
I had taken a break from using my GCP instance for a while - it was a n2d-highmem-8. I’m able to connect and get to Jupyter, but in every notebook, the kernel won’t connect. Any ideas on if this is related to the same issues? I setup a new instance using n1-highmem-8 and the issue persists. Any suggestions?
I would just like to point out to anybody trying to setup google cloud platform for the first deep learning course, there’s been a minor update in the setup.
The setup page suggests we update fast.ai on the GCP server with this command.
Hi, everyone. I am facing some issue about compute engine on GCP.
All of my vm are not able to start due to “does not have enough resources available to fulfill the request”.
I have made a snapshot of my storage and use it to create a new instance but the same error occur.
People suggest that it is a temporary issue and the situation will return to normal after several hours.
However, I am not able to connect ant compute engine for at least a week.
Could someone suggest a solution for me? Thanks.
The same happens with me, what drives me crazy is that Google Colab, a FREE service, still offers free GPU computing, altough for long trainings it’s not an optimal solution.
If it can help, on LInux, you can use the following command in order to know which zone has GPU accelerators avialable (at least in theory):
gcloud compute accelerator-types list | grep europe | grep p100
this will find all europe zones with nvidia p100 gpus.
I was just able to run an instance in zone europe-west4-b using a v100 and a t4 gpu.