@immarried so try using the new location. It works a little better for me, but stills shut off after some time. I have created another instance for normal vm. I think i am going to use the normal one for my projects and maybe for regular stuff or go back to pre-emptied when doing lesson nbs. Yes, they are expensive, but remember you have the $300 credit. The normal is awesome so far, you enter with only one try and doesn’t disconnect!
2 Likes
Can anyone share how to upload a large dataset to GCP and set path to it in Lesson 1? I have been using a small dataset uploading it through Jupiter notebook, but now want to try to train on my large dataset.
The link is outdated. I think the new link is this https://course.fast.ai/start_gcp.html#step-4-access-fastai-materials-and-update-packages
I noticed in the command line instructions the option -L 8080:localhost:8080 which kinda pipes the output to my local machine at port 8080. So to access the notebook you would need to type in the browser “localhost:8080” or whatever port number you chose.
Has anyone had their quota increase request refused immediately after it being placed?
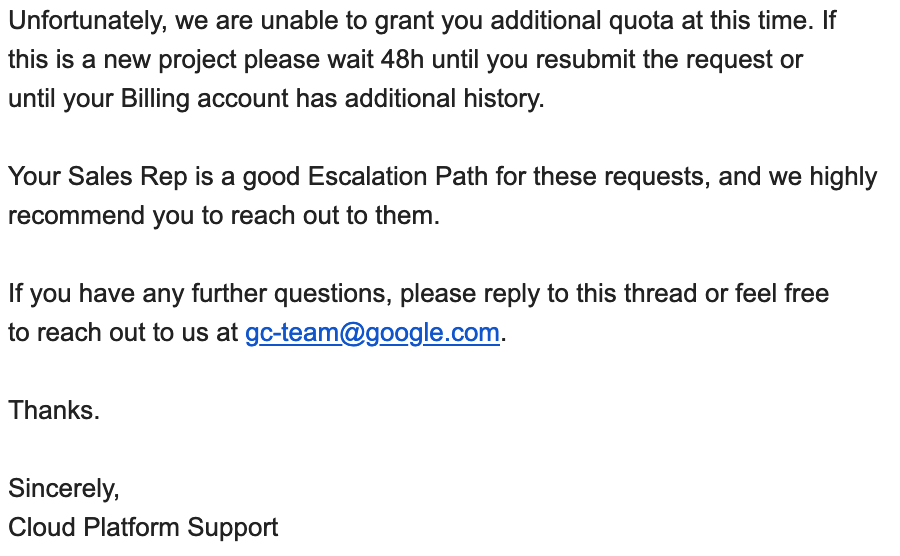
I wrote back immediately asking what the reason was, and the explanation was because of “insufficient service usage history”, and that it would be good if I contacted the “Sales Team”. This has never happened the few times I applied for a quota increase in the past.
Yes the same thing happened to me. Anybody has a solution for this ?
I tried it again with another new account and it’s worked. The only reason I can think of is that the First Name and Last Name I used were more plausible this time round.
1 Like
I am trying to set up GCP and have encountered the same error as @AndreaPi and @J.J - Disk size: ‘200 GB’ is larger than image size: ‘50 GB’
I have set my GPU quota and am actually able to create an identical instance following GCP documentation, but the Console does not offer the preemptible option.
https://cloud.google.com/ai-platform/deep-learning-vm/docs/pytorch_start_instance
Any ideas?
Hello there, I have been trying to solve this error for the past 8 hours with no luck (including solutions here and on stack overflow). anybody have any ideas?
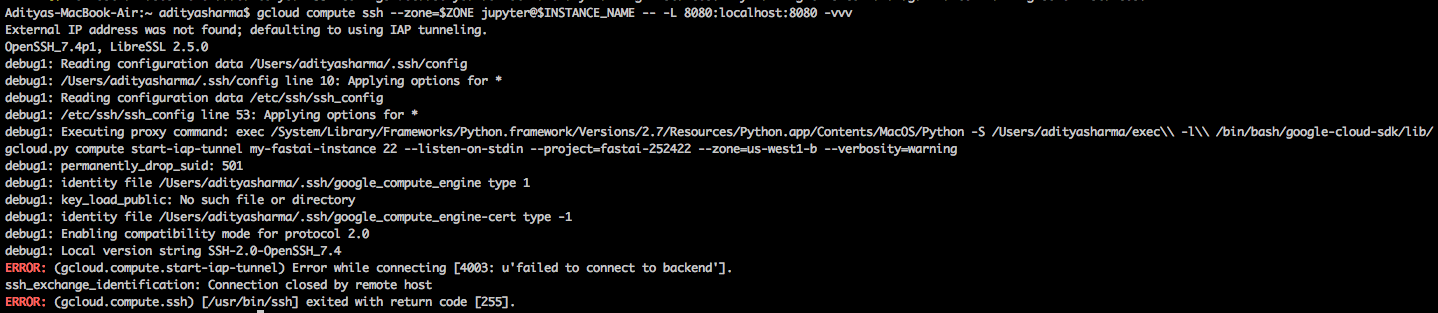
Hey @cheye, I think I ended up just ignoring the warning and haven’t had any problems.
Though I didn’t encounter the other issue you mention, of not being able to create a preemptible option… So I’m not sure what to do about that.
Did you ever resolve this? Am having the same problem
Hi guys,
I am just starting learning fastai and I wanted to say big thank you for all your hard work preparing the docs! I have not dug that deep, but everything I see now is truly inspiring!
I have set up GCP instance and there is constantly a small problem that either it just does not start the instance, or it stops the instance after like 15~20 minutes.
Are there any tips on how to work around that? Or is the only solution to just move away from preemptible ones?
Thanks,
Tony
I might be having the same problems as @forest_man . the instance starts but the console shows “Booting from Hard Disk 0…” and then nothing else, which I think means it’s not booting at all. I tried with a 200GB and 50GB boot disk size, thinking that maybe it would make a difference, but it did not.
I simply followed the instructions on the page start_gcp.html on the fastai course web site.
I ended up using AWS instead… and while the AWS instance was loading up I thought, maybe a new version of something is causing this… and I thought it could be the version of the compute image… after looking around I found the previous version and this one loaded fine…
So here is what worked for me:
export IMAGE=pytorch-latest-gpu-20200128
export ZONE="us-west1-b"
export INSTANCE_NAME="my-fastai-instance"
export INSTANCE_TYPE="n1-highmem-8"
gcloud compute instances create $INSTANCE_NAME \
--zone=$ZONE \
--image=$IMAGE \
--image-project=deeplearning-platform-release \
--maintenance-policy=TERMINATE \
--accelerator="type=nvidia-tesla-p100,count=1" \
--machine-type=$INSTANCE_TYPE \
--boot-disk-size=200GB \
--metadata="install-nvidia-driver=True" \
--preemptible
The latest version (pytorch-latest-gpu-20200226) is not working it seems…
1 Like
Hi Roy,
Thanks for suggestion!
I have been trying to make it working, but I am getting the following error:
ERROR: (gcloud.compute.instances.create) Could not fetch resource:
- The resource ‘projects/deeplearning-platform-release/global/images/family/pytorch-latest-gpu-20200128’ was not found
I have checked this page: https://cloud.google.com/ai-platform/deep-learning-vm/docs/images
and the only PyTorch images offered are:
pytorch-latest-gpu
pytorch-latest-cpu
Cheers,
Tony
Hello Tony,
This is because this image is deprecated and because the page you looked at only lists the families, not the images themselves. They seem to deprecate old images as soon as a new image is available. To see all images, I used this command:
gcloud compute images list \
--project deeplearning-platform-release \
--no-standard-images \
--show-deprecated \
--filter family=pytorch-latest-gpu
You will see the latest image that is not deprecated (which fails to boot) and the older deprecated versions, including the one that worked for me: pytorch-latest-gpu-20200128
It’s weird that it wont allow you to start a new instance with that image since that worked for me yesterday. I just tried creating a new instance and it worked fine. I think you must have used the wrong command. If you copy and paste what I wrote in my original post, it should work.
From the error message that you posted, it sounds like you used --image-family=pytorch-latest-gpu-20200128 when you should have used: --image=pytorch-latest-gpu-20200128.
The difference is that the instructions shows how to create an instance from the latest version of a family of images, where my instructions shows how to create an instance from a specific image.
Let me know if you have any questions.
Christian
Preemptibles got pretty unusable few months ago 
Is there a way to quickly switch between CPU and GPU (and preferably GPU types) in GCP?
I don’t need GPU all the time and some times k80 would be enough for experimentation.
I agree with @Blanche about preemptibles. I tried and they would get shutdown within minutes of starting them. Not very useful…
@Blanche I do not think there’s a way to switch a running instance from CPU to GPU. What you need is to start a new instance.
Christian
Well you can unmount disk and then mount to another instance  I just don’t know any quick way to do that, I’ve already did it but it involved recreating disc from snapshot and if we could unmount and remount to another instance disks without too much hassle that would result in running much more on cheaper instances (like CPU for data exploration, cheap GPU for early testing etc)
I just don’t know any quick way to do that, I’ve already did it but it involved recreating disc from snapshot and if we could unmount and remount to another instance disks without too much hassle that would result in running much more on cheaper instances (like CPU for data exploration, cheap GPU for early testing etc)
If you create the instances in the same zone, you can shutdown the old instance and then attach the same disk to the new instance. One way is like this:
gcloud compute instances attach-disk [INSTANCE_NAME] /
--disk [DISK_NAME]
More details: https://cloud.google.com/compute/docs/disks/add-persistent-disk
1 Like
I’ve found something even more interesting. In alpha we can get disks that can be attached in read/write mode to multiple instances without having to attach/detach. https://cloud.google.com/sdk/gcloud/reference/alpha/compute/disks/create#--multi-writer Looks really promising, I may actually try it this week.
@forest_man A new version of the image under pytorch-latest-gpu family was released today. I tested it and it booted just fine. I used the instructions from the GCP setup instructions as-is this time.
The new version is pytorch-latest-gpu-20200306 but you do not need to specify that if you use the --family option.
Christian