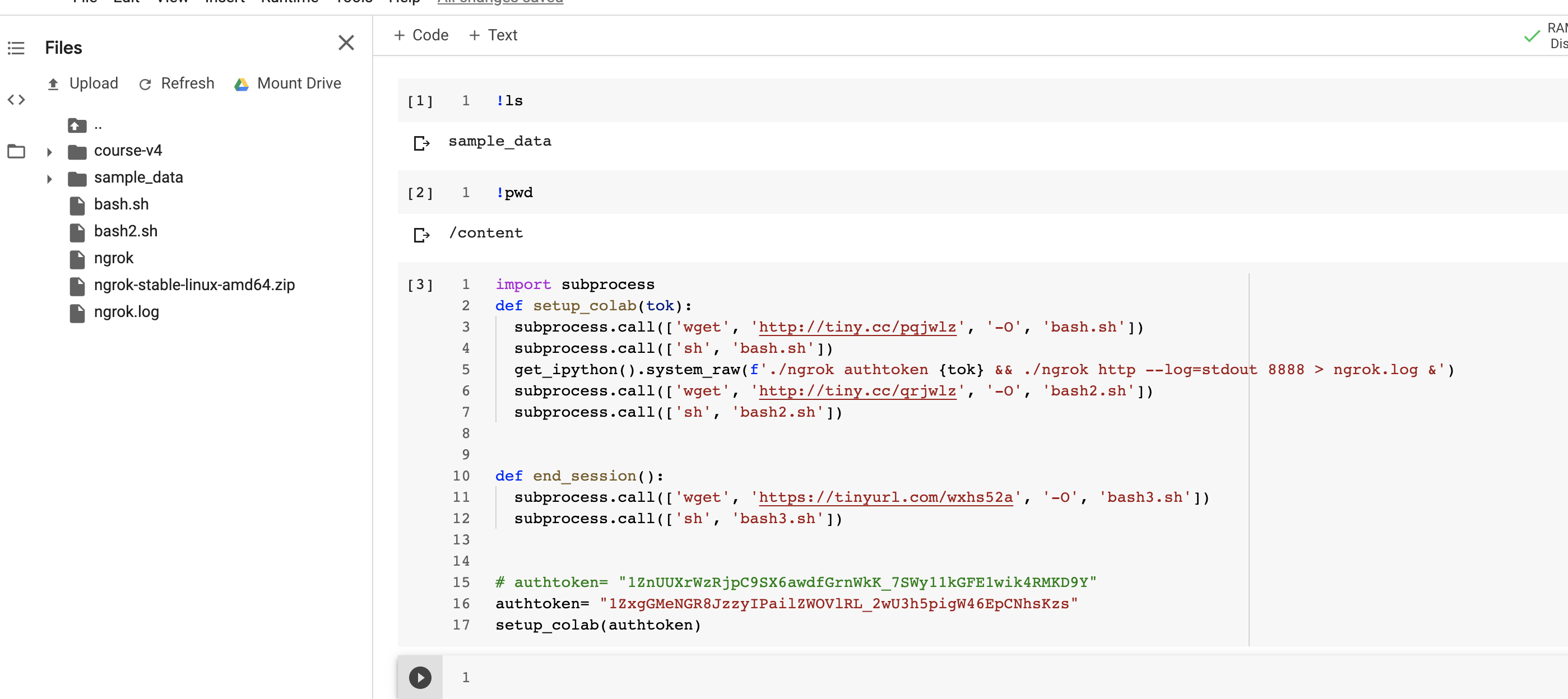
I was able to use this nifty hack until i decided to open it from my drive so i could save stuff (got greedy )
now i can’t get my notebook to run
i tried from /content without mounting my drive as seen in the below picture:
Can anyone recommend the best options for storage on colab/drive?
I’ve got a lot of images, approx 250,000 and looking to increase that number substantially. I’ve got a few questions:
What’s the best fastest way to upload them to google drive? Just upload via web browser, or should I zip upload and then unzip with python once it’s copied?
Is there a performance hit compared to using local storage? My model is currently running on a work machine, where it’s on an SSD, but it’s a non work project so I need to move it.
Is there any advantage to moving the files locally to colab when training my model, i.e. to /content or elsewhere, somewhere other than drive
Well, I’ve done some experiments and I think I’ve answered my own question. Using training data straight from drive is horrendously slow. So the best option seems to be, zip it up, copy to drive and then use the following to copy from drive, unzip and then delete the zip. For about 25k images (1GB zipped), it takes about 20 seconds which is tolerable (So i’m looking at about 3 minutes for my full dataset).
Done anyone know how to increase the size of the shared memory on colab i.e. the volume /dev/shm? Though they’ve upped it to about 5GB, I’m doing something fairly intensive and it’s bombing out with the following error. Jeremy previously had a script to do it, but it seems to have gone:
RuntimeError: DataLoader worker (pid 137) is killed by signal: Bus
Thanks @gamo I think I tried this (saw from your previous post), but I was getting an issue with the second regex. I’ll give it another shot though Strangely my error seems to be intermittent.
Another tip for others using colab, my model training was approx 3x slower than the work machine which has similar GPUs so I figured out that it’s basically down to the measly CPU spec that colab provides. However I managed to make it about 50% quicker by changing the Runtime shape to High-RAM, not only does this increase the RAM, but it doubles the CPU. Obviously this only works for Colab Pro though.
@gamo So is the /dev/shm mount RAM? If so, might it be more efficient to put my data on there? I’ve just tried it and my epoch time has gone down from about 7 minutes to just under 6 - though it’s hard get an accurate baseline due to the performance inconsistency I’ve been seeing on colab.
shm stands for “shared memory”. It is used to pass data between programs.
tmpfs is temporary volatile storage, also known as a ramdisk.
If I where to guess, in this case, it is used to pass data (batches) between the python part and cuda part (gpu) of the trainer.
If you put your unprepared training data on the shm you take up memory that should be used when sharing data.
The speedup you see can be due to that the training data does not need to be read from disk, which would make preprocessing faster. If you want to do it without speed or storage penalties you should resize the shm to training data size + gpu ram size or create another separate tmpfs for the training data.
@wittmannf IIRC that’s supposed to happen (notice you don’t have a Resize anywhere in there, it’s supposed to show how dblock.summary() can be used for debugging)
# Load the Drive helper and mount
from google.colab import drive
# This will prompt for authorization.
drive.mount('/content/drive')
%cd '/content/drive/My Drive/dhoa.github.io'
!git config --global user.email "dienhoa.t@gmail.com"
!git config --global user.name "dienhoa"
!git add .
!git commit -m "first commit"
!git push origin master
I think I forgot step to put my passord.
I was annoyed when colab lost the session during training and I had to start from scratch. Therefore I extended the SaveModel Callback to not only save the best model after each epoch but also tar and copy it to my gdrive (or any other bucket-store).
In case someone hast faced simliar problems I share the code snippet:
 (got greedy
(got greedy  )
)
 Strangely my error seems to be intermittent.
Strangely my error seems to be intermittent.
 (notice you don’t have a Resize anywhere in there, it’s supposed to show how dblock.summary() can be used for debugging)
(notice you don’t have a Resize anywhere in there, it’s supposed to show how dblock.summary() can be used for debugging)