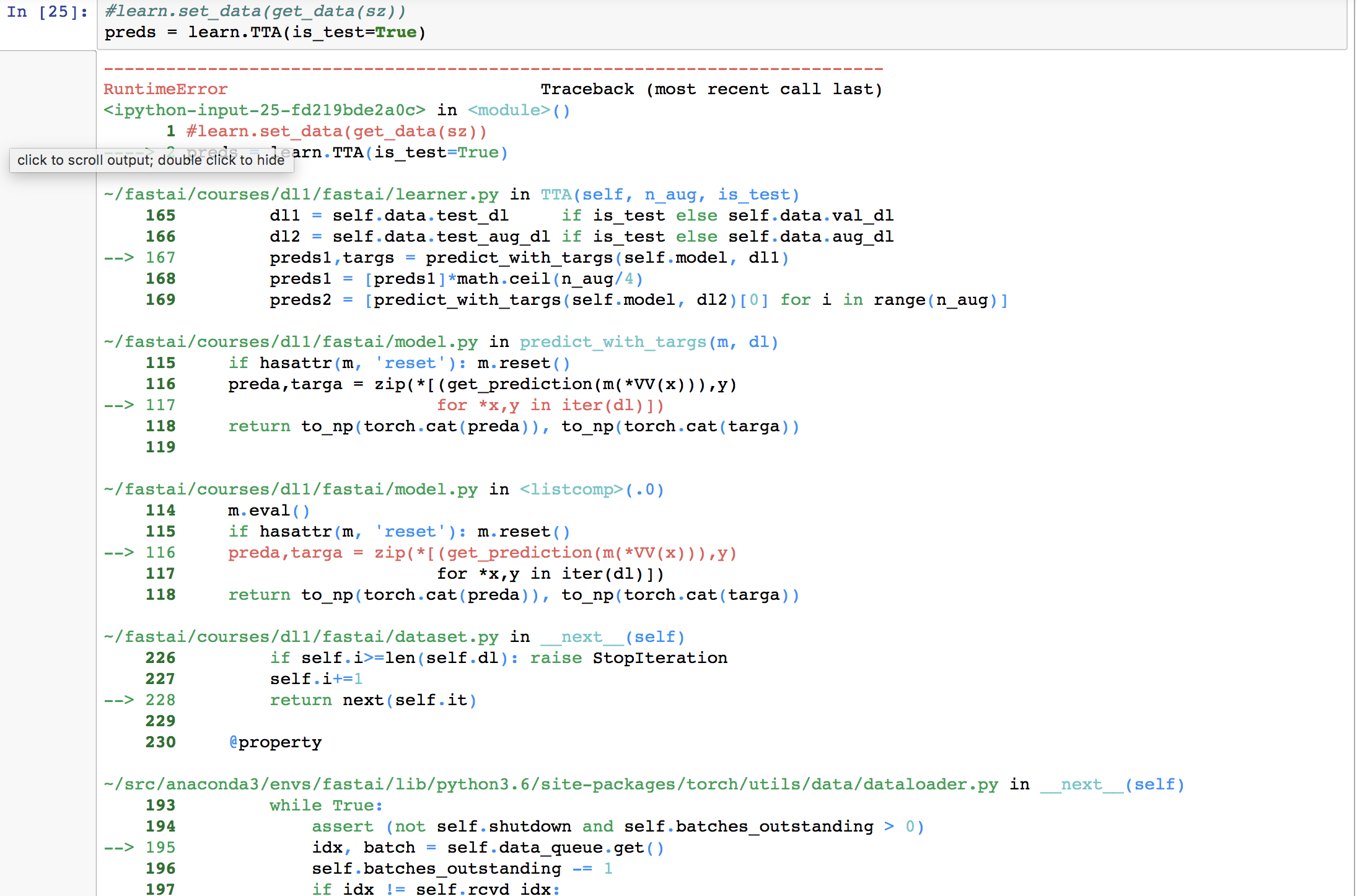
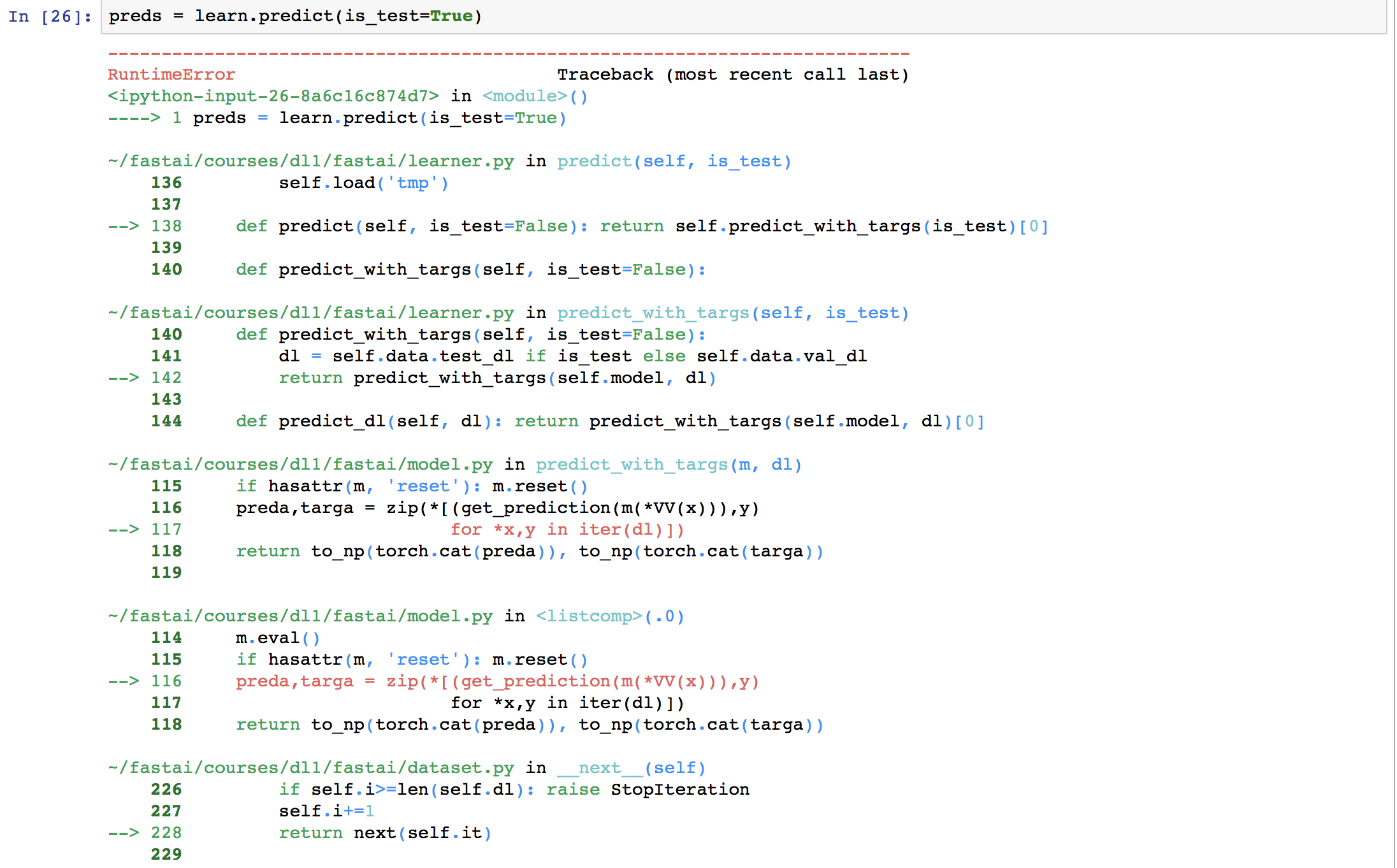
Do you have the latest code from fastai repo? I would suggest doing a git pull, and see if it goes away. Jeremy seemed to mention that he got rid of the Opencv library which is in your error.
I’m on the latest code. BTW, Jeremy brought back opencv ![]()
I’ll try to restart AWS and see if that helps. I had previously tried restarting kernel.
1 Like

That is great. Glad it worked.
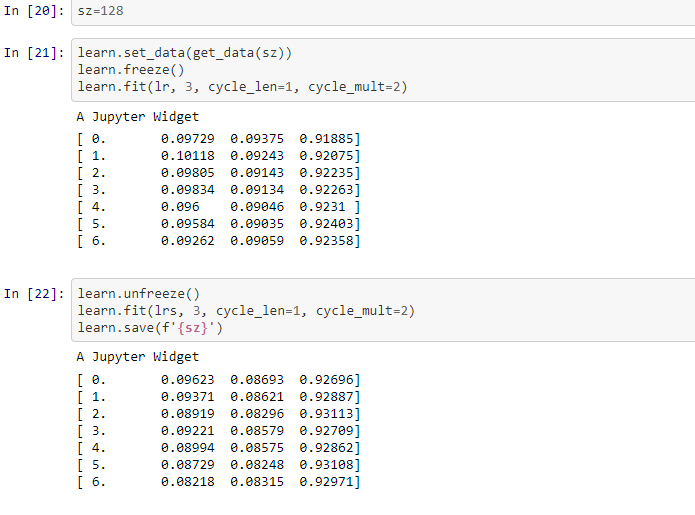
We resized images in lesson 2 notebook while size was 64:
data = data.resize(int(sz*1.3), 'tmp')
But for size 128, 258 we are providing the new set of data and not resizing for them. Any insight on this?
I was just about to ask the same question.
We do …
img_sz = 64
data = get_data(arch, img_sz, val_idxs)
data = data.resize(int(img_sz * 1.3), 'tmp') # this creates /tmp/83
… and then resize to 128 and then to 256.
BUT, if you look in the file system, you’ll only see a tmp/83 folder with your resized images from the above line of code. It seems that when we resize to 128 we are resizing the previously downsized images we saved as 64x64 images … and also when we resize to 256, that we are again resizing from the 64x64 images.
Is that right?
If it is, for some reason, it feels wrong to be building bigger images from previously downsized images instead of using the original sizes to do the 128 and 256 sized images.
Actually looking again, that’s not what we’re doing - we’re creating the dataset again from scratch, not using the resized images. So I think it’s fine.
1 Like
Ok … that makes sense looking at the code again.
I take it then that the call to resize to 128 and 256 acts against the original sized images in this case.
If on the otherhand we didn’t make another call to get_data(), we would have upscaled the 64x64 images to 128 and 256.
1 Like
Exactly right.


What is the total number of items in your test folder?
Test count mismatch:
I’ve 40669 images:
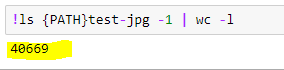
While I try to submit Kaggle says:

@vikbehal For this competition, there is an additional test set folder test-jpg-additional.tar.7z one option is to consolidate the images from both test set folders into one folder. You can refer to the data at the kaggle competition website for details.
4 Likes
@binga, in your code you have data augmentation + precompute=true… so tfms is ignored, isn’t it? (don’t know if its what you intended).
I have been able to “reproduce your reproducibility”  , but only if precompute= true. With precompute = false not getting same results, even if I paste all three lines of seed code before beginning of each line of code.
, but only if precompute= true. With precompute = false not getting same results, even if I paste all three lines of seed code before beginning of each line of code.
¿Have you managed to achieve reproducibility with precompute=false?
P3 instance did not work for me. I think it is CUDA version issue. Let me know if you get it to work.
That’s weird. My knowledge is limited but shouldn’t p2 or p3 if use fastai ami, should run without any issue.
Jeremy said that fast.ai ami supports p2 instances only…(if i can remember)
Yes, with data augmentation + precompute = True, tfms is ignored. And, I think I didn’t intend to do it. However, as I think twice, maybe I wanted to start with a couple of epochs only training the final layer and then turn off precompute, start augmentations and tweak initial layers. Damn! I missed this point while I built my network. These models always teach us something more and we keep trying 
However, let me try again with precompute=False and get back to you.
@uvs The ami wouldn’t work with P3 since P3 instances with Volta GPUs need CUDA 9 and the AMI that @jeremy built for us contains CUDA 8 IIRC.
Edit: Striking off incorrect details.
1 Like
Our AMI does use CUDA 9, but I believe p3 requires a separate AMI. However, you can easily create your own, by using the Amazon deep learning AMI, installing anaconda, cloning fastai repo, and doing conda env update.
3 Likes
Oops, didn’t realize that ! Apologies.
I am getting an error when I do the prediction on the test set. Pls help as to how to address. I had two test folders - test-jpg and test-jpg-additional. I copied all images from test-jpg-additional into test-jpg so that the total number of images are in test-jpg. This error started coming post that.