Great Job!! Does it also show your private leaderboard score? Ideally that is the score you’ll want to be looking at since the final score for Kaggle comps is based on the private leaderboard.
1 Like
Yes. You can see the private scores too. Check it in My Submissions Tab.
1 Like
I have a .93000 private score.
3 Likes
Thanks for the heads up on finding the private score under My Submissions. Mine is horrible (.57), so I think I did something wrong when I generated predictions on the second half of the test images. Off to check!
Yep I think its prob an issue with the test id names and/or sorting issues. Believe it or not even a kaggle master that had gold medal ranking on public LB dropped 900 ranking spots on private lb because of this and it was easy to go undetected because the files corresponding to the public lb sorting was correct!
2 Likes
Ha – I guess I’m in good company LOL
I think it had something to do with the way I constructed my submission file – the predictions were okay in the pandas data frame.
Another valuable lesson learned 
1 Like
Ouch, I don’t understand how that happened though? So the public LB has a defined number of records and the private one uses the rest. How does one do well and one do horrendously? Aren’t they using the same underlying model?
Do you have any rule of thumbs on when the larger number models (34 vs 50 vs 101), and the architectures (resnet vs resnext vs vgg) are better or do you just try all of the models available and see which one does the best.
1 Like
Okay, the problem WAS how I constructed my submission file – .9283 for the private LB now 
Back to the salt mines now to refine . . .
1 Like
Sadly no I don’t. I’d like to find some!
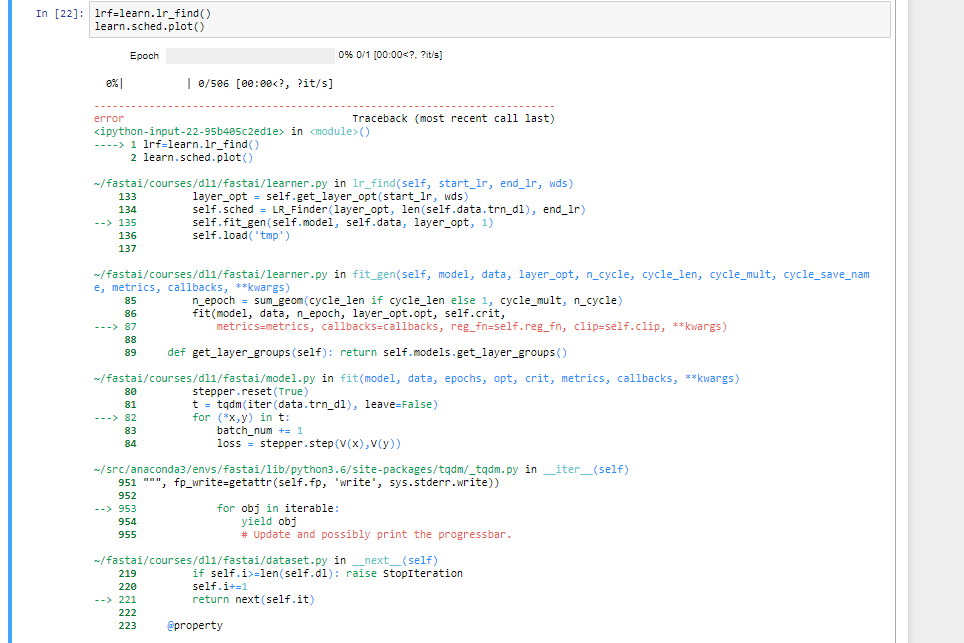
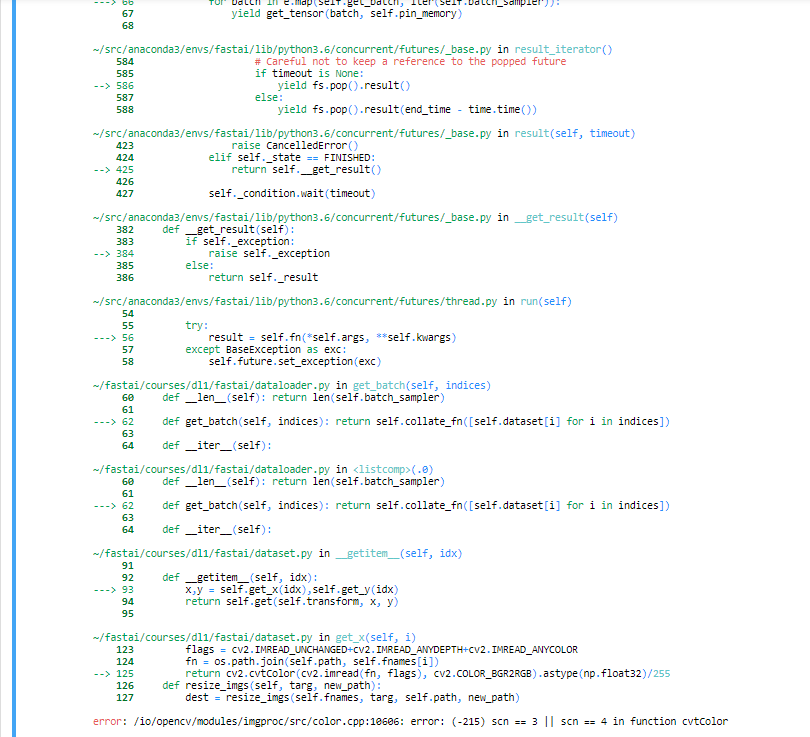
Is anybody able to reproduce their experiment results? I’m using torch.cuda.manual_seed(42) to ensure I get the same results across runs however I’m unable to do so.
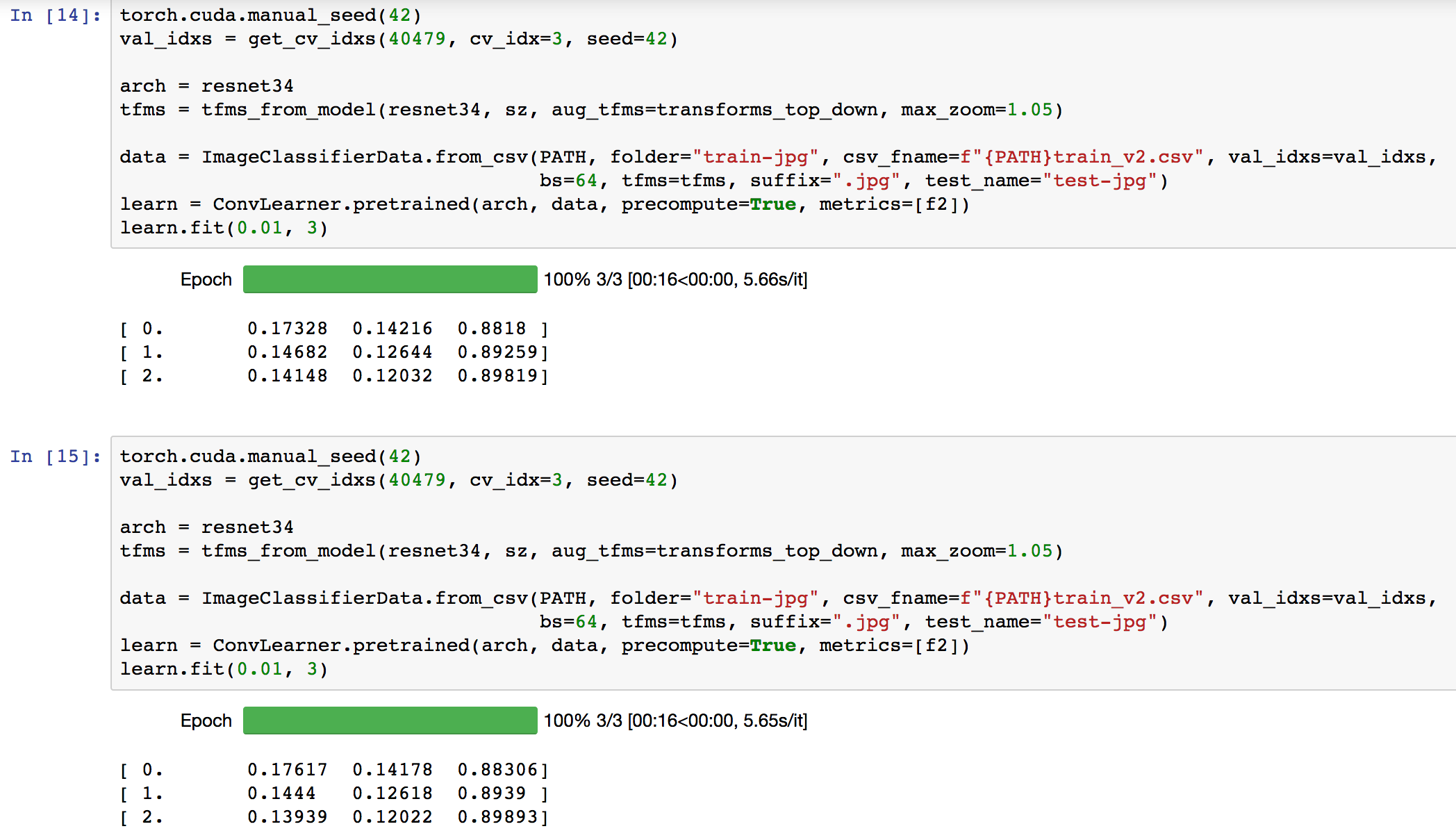
Edit: I tried torch.cuda.seed() too. Not reproducible! 
learner.bn_freeze(False)?
It works like unfreezing of the layers?(Batch Norms)
1 Like
Made a rookie error in my previous submission. I forgot to train on complete data to make my submission. When I made this change, my score improved from 0.92990 (133) → 0.93095 (105). Not bad for a single resnet34 model which we learnt in the class.
Just mentioning the mistake here so that it might help someone ![]()
4 Likes
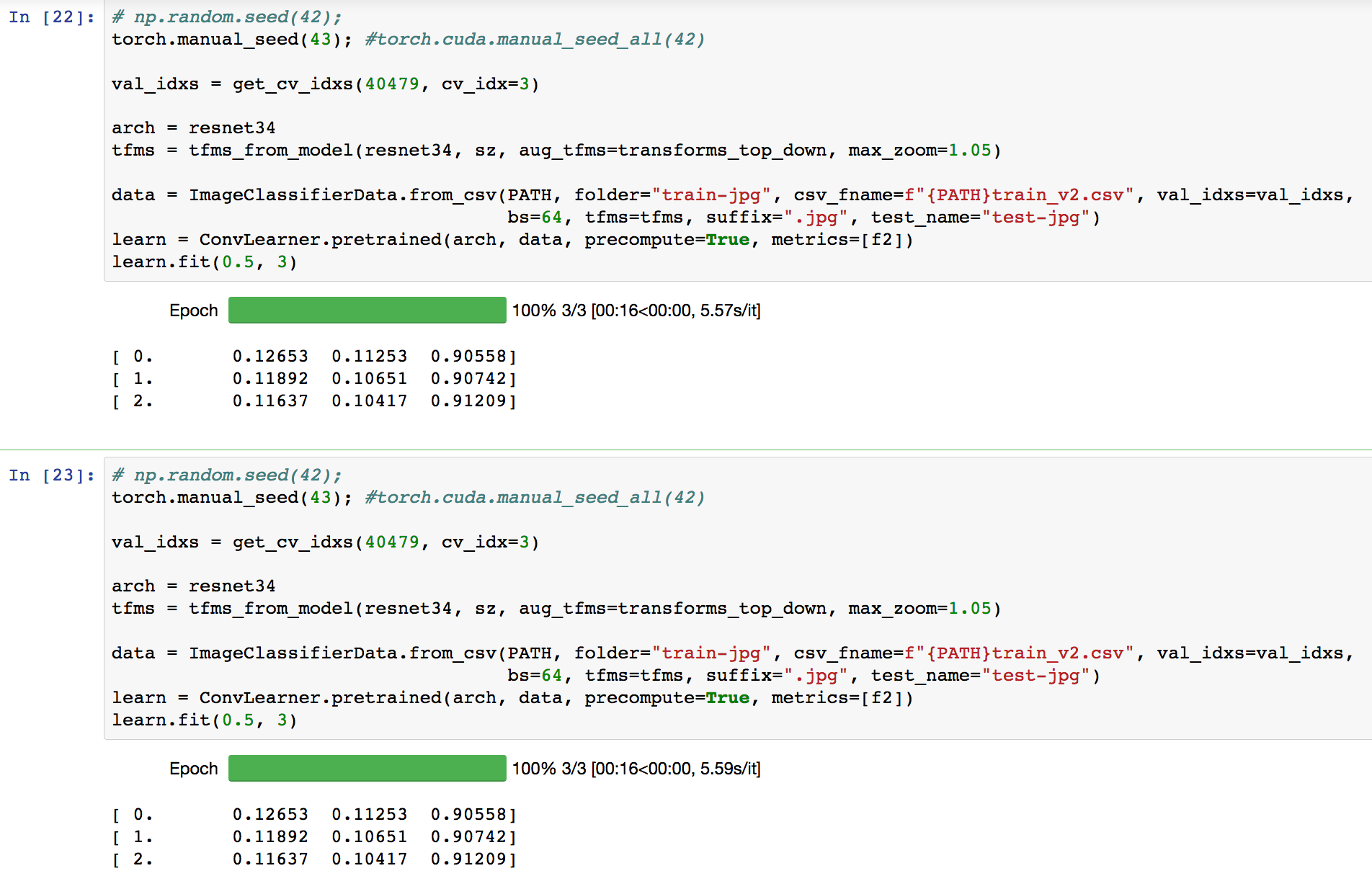
Personally, I don’t generally use a random seed, since I quite like to see what amount of natural variation there is. But I believe this should do it:
np.random.seed(args.manualSeed)
torch.manual_seed(args.manualSeed)
torch.cuda.manual_seed_all(args.manualSeed)
8 Likes
4 Likes
Hi, did you guys rename the additional test set files? I think I am getting errors because of this.
I moved the images in test-jpg-additional/ into test-jpg/ and everything works smoothly from then onwards. In total, ensure you have 61191 images in test-jpg/ folder.
3 Likes
@nafiz, no, I didn’t rename, nor did I combine the two test sets (I’m running on Crestle with simlinks). I predict the two sets separately, and then combine them to submit, but the first time I did this something weird happened with the second test set and all my predictions were wrong. So you do need to be careful.
I’m thinking I just should have combined the two test sets as @binga did, the time I saved by not doing I have then wasted x100 in wrangling the two separate test sets!
After moving the additional test files to the test-jpg folder, I was getting this error
----> 1 tta= learn.TTA(is_test=True)
RuntimeError: received 0 items of ancdata
I saw that there is an issue already here regarding this -
From there I tried to use the hack of using -
import resource
rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
resource.setrlimit(resource.RLIMIT_NOFILE, (2048, rlimit[1]))
But still it is showing the following errors-
> ----> 1 tta= learn.TTA(is_test=True)
> 2 classes = np.array(data.classes, dtype=str)
> 3 res = [" ".join(classes[np.where(pp > 0.2)]) for pp in tta[0]]
> 4 test_fnames = [os.path.basename(f).split(".")[0] for f in data.test_ds.fnames]
> 5 test_df = pd.DataFrame(res, index=test_fnames, columns=['tags'])
>
> ~/fast_ai_fellowship/fastai/courses/dl1/fastai/learner.py in TTA(self, n_aug, is_test)
> 167 preds1,targs = predict_with_targs(self.model, dl1)
> 168 preds1 = [preds1]*math.ceil(n_aug/4)
> --> 169 preds2 = [predict_with_targs(self.model, dl2)[0] for i in tqdm(range(n_aug), leave=False)]
> 170 return np.stack(preds1+preds2).mean(0), targs
> 171
>
> ~/fast_ai_fellowship/fastai/courses/dl1/fastai/learner.py in <listcomp>(.0)
> 167 preds1,targs = predict_with_targs(self.model, dl1)
> 168 preds1 = [preds1]*math.ceil(n_aug/4)
> --> 169 preds2 = [predict_with_targs(self.model, dl2)[0] for i in tqdm(range(n_aug), leave=False)]
> 170 return np.stack(preds1+preds2).mean(0), targs
> 171
>
> ~/fast_ai_fellowship/fastai/courses/dl1/fastai/model.py in predict_with_targs(m, dl)
> 115 if hasattr(m, 'reset'): m.reset()
> 116 res = []
> --> 117 for *x,y in iter(dl): res.append([get_prediction(m(*VV(x))),y])
> 118 preda,targa = zip(*res)
> 119 return to_np(torch.cat(preda)), to_np(torch.cat(targa))
>
> ~/fast_ai_fellowship/fastai/courses/dl1/fastai/dataset.py in __next__(self)
> 219 if self.i>=len(self.dl): raise StopIteration
> 220 self.i+=1
> --> 221 return next(self.it)
> 222
> 223 @property
>
> ~/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py in __next__(self)
> 199 self.reorder_dict[idx] = batch
> 200 continue
> --> 201 return self._process_next_batch(batch)
> 202
> 203 next = __next__ # Python 2 compatibility
>
> ~/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py in _process_next_batch(self, batch)
> 219 self._put_indices()
> 220 if isinstance(batch, ExceptionWrapper):
> --> 221 raise batch.exc_type(batch.exc_msg)
> 222 return batch
> 223
>
> AttributeError: Traceback (most recent call last):
> File "/home/nafizh/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 40, in _worker_loop
> samples = collate_fn([dataset[i] for i in batch_indices])
> File "/home/nafizh/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 40, in <listcomp>
> samples = collate_fn([dataset[i] for i in batch_indices])
> File "/home/nafizh/fast_ai_fellowship/fastai/courses/dl1/fastai/dataset.py", line 94, in __getitem__
> return self.get(self.transform, x, y)
> File "/home/nafizh/fast_ai_fellowship/fastai/courses/dl1/fastai/dataset.py", line 99, in get
> return (x,y) if tfm is None else tfm(x,y)
> File "/home/nafizh/fast_ai_fellowship/fastai/courses/dl1/fastai/transforms.py", line 466, in __call__
> def __call__(self, im, y=None): return compose(im, y, self.tfms)
> File "/home/nafizh/fast_ai_fellowship/fastai/courses/dl1/fastai/transforms.py", line 447, in compose
> im, y =fn(im, y)
> File "/home/nafizh/fast_ai_fellowship/fastai/courses/dl1/fastai/transforms.py", line 231, in __call__
> x,y = ((self.transform(x),y) if self.tfm_y==TfmType.NO
> File "/home/nafizh/fast_ai_fellowship/fastai/courses/dl1/fastai/transforms.py", line 239, in transform
> x = self.do_transform(x)
> File "/home/nafizh/fast_ai_fellowship/fastai/courses/dl1/fastai/transforms.py", line 403, in do_transform
> if self.rp: x = rotate_cv(x, self.rdeg, mode=self.mode)
> AttributeError: 'RandomRotateXY' object has no attribute 'mode'
I have the latest code from the fast-ai repo. Any suggestions on this?