Thank you Kevin for the kind words. Also thanks for the tip on the threshold. I’ll try my hand at 0.2 and opt_th.
James, when I went through the opt_th function it seems to return 1 threshold. Could you please explain how it can return threshold per label? Do we use a optimizer?
Also the f2 function itself applies a constant threshold between 0.17 and 0.24 and returns the max. Does this mean different thresholds were applied to different batches?
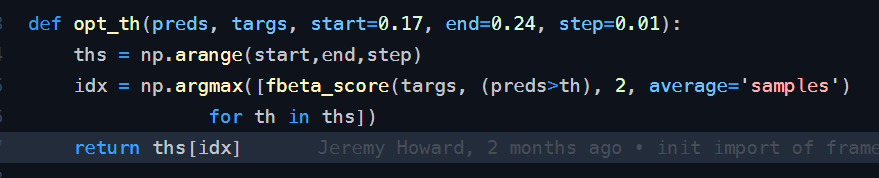
@jeremy In the source code, the lower and upper bounds are set as 0.17 and 0.24 with step = 0.01 (ie 8 steps in total). Is it a rule of thumb? Or, do we need to reset the lower and upper bounds depending on the number of variables?
For this challenge,17 possible tags: agriculture, artisinal_mine, bare_ground, blooming, blow_down, clear, cloudy, conventional_mine, cultivation, habitation, haze, partly_cloudy, primary, road, selective_logging, slash_burn, water. 4 of them are under a weather group (ie clear, cloudy, partly_cloudy and haze) which should be mutually exclusive and included in every prediction. Should we treat the weather group and non-weather group separately?
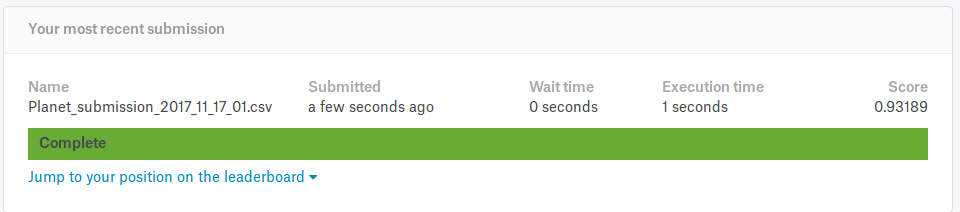
Got my F2 score up to 0.93189 on tonight’s run. Biggest change was removing my validation set and also running longer after unfrozen. I’ll get my code uploaded on github and share the link here.
9 Likes
This question may be asked somewhere - can someone explain on an abstract level what does f2 and opt_th metrics does?
Putting my code from 0.93189 here instead of a git repo. Hopefully this will help somebody else. Big thanks to @jeremy for giving most of this in his lesson2 notebook and @Deb for the code to generate the result. Hopefully this can help somebody else like those helped me.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.conv_learner import *
PATH = 'data/planet/'
f_model = resnet34
sz = 256
ls {PATH}
sample_submission_v2.csv e[0me[01;34mtest-jpg-additionale[0m/ e[01;34mtrain-jpge[0m/
e[01;34mtest-jpge[0m/ test_v2_file_mapping.csv train_v2.csv
label_csv = f'{PATH}train_v2.csv'
n = len(list(open(label_csv)))-1
val_idxs = get_cv_idxs(n)
val_idxs
array([21694, 11665, 24256, ..., 37194, 16850, 6265])
tfms = tfms_from_model(f_model, sz, aug_tfms=transforms_top_down, max_zoom=1.05)
data = ImageClassifierData.from_csv(PATH, 'train-jpg', csv_fname=PATH+"train_v2.csv", tfms=tfms, suffix='.jpg', val_idxs=[0], test_name='test')
from planet import f2, opt_th
metrics = [f2]
learn = ConvLearner.pretrained(f_model, data, metrics=metrics)
lrf = learn.lr_find()
A Jupyter Widget
[ 0. 0.20286 0.59473 0.5 ]
learn.sched.plot()
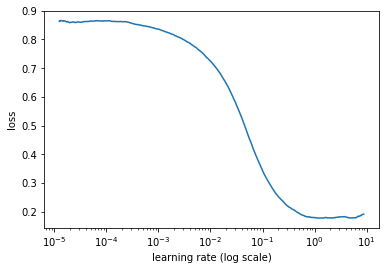 file:///home/kbird/Downloads/output_11_0.png
file:///home/kbird/Downloads/output_11_0.png
lr = 0.2
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
A Jupyter Widget
[ 0. 0.13108 0.14225 0.90909]
[ 1. 0.1249 0.18688 0.90909]
[ 2. 0.12106 0.11869 0.90909]
[ 3. 0.12115 0.14411 0.90909]
[ 4. 0.12178 0.12196 0.90909]
[ 5. 0.11593 0.09995 0.90909]
[ 6. 0.11825 0.12991 0.90909]
lrs = np.array([lr/9,lr/3,lr])
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
A Jupyter Widget
[ 0. 0.09976 0.05 0.90909]
[ 1. 0.09637 0.09861 0.90909]
[ 2. 0.0889 0.09173 0.90909]
[ 3. 0.09258 0.09754 0.90909]
[ 4. 0.08856 0.04493 0.90909]
[ 5. 0.08623 0.05523 0.90909]
[ 6. 0.08202 0.07054 0.90909]
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
A Jupyter Widget
[ 0. 0.08519 0.06086 0.90909]
[ 1. 0.08793 0.05491 0.90909]
[ 2. 0.0809 0.06352 0.90909]
[ 3. 0.08955 0.04287 0.90909]
[ 4. 0.0846 0.06043 0.90909]
[ 5. 0.07966 0.0425 0.90909]
[ 6. 0.07602 0.04492 0.90909]
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
A Jupyter Widget
[ 0. 0.10397 0.08797 0.92806]
[ 1. 0.09979 0.08633 0.92947]
[ 2. 0.09399 0.0818 0.93373]
[ 3. 0.09681 0.08443 0.9314 ]
[ 4. 0.0903 0.08165 0.93406]
[ 5. 0.08989 0.07917 0.93562]
[ 6. 0.08248 0.07885 0.93595]
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
A Jupyter Widget
[ 0. 0.103 0.08786 0.92851]
[ 1. 0.09859 0.08687 0.92739]
[ 2. 0.09324 0.08264 0.93274]
[ 3. 0.09789 0.08442 0.93277]
[ 4. 0.09211 0.08204 0.93359]
[ 5. 0.08822 0.07928 0.9367 ]
[ 6. 0.08377 0.07902 0.93662]
learn.save(f'{sz}_NoValidation')
learn.sched.plot_loss()
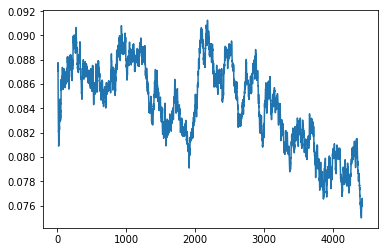 file:///home/kbird/Downloads/output_20_0.png
file:///home/kbird/Downloads/output_20_0.png
import resource
rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
resource.setrlimit(resource.RLIMIT_NOFILE, (2048, rlimit[1]))
tta = learn.TTA(is_test=True)
test_fnames = data.test_ds.fnames
for i in range(len(test_fnames)):
test_fnames[i] = test_fnames[i].split("/")[1].split(".")[0]
classes = np.array(data.classes, dtype=str)
res = [" ".join(classes[np.where(pp > 0.2)]) for pp in tta[0]]
submission = pd.DataFrame(data=res)
submission.columns = ["tags"]
submission.insert(0, 'image_name', test_fnames)
submission.to_csv(PATH+"Planet_submission_2017_11_17_01.csv", index=False)
22 Likes
Hi Deb, I haven’t really tested the opt_th function myself, but I saw fastai had provided it and I remembered in this comp there were even kernel’s created that had functions for finding the opt threshold per label. The general idea is that it should loop through a range of thresholds, in this case the defaults provided are 0.17 - 0.24 with a step size of .01 but you could change those parameters to any numbers you wanted, and then it returns the threshold that generated the max f2 score.
Anyway it looks like Kevin managed to get a pretty amazing score just by using a fixed threshold of 0.2 which is sort of the “sweet spot” for this competition although with a little thresh optimization it could probably wiggle a bit higher.
1 Like
I’m going a different route currently, but I might come back to the th_opt and see if there is a better threshold to be using than 0.20. That is 100% just from what you recommended initially.
Thanks James for the clarification.
It’s just something that worked well for me in this particular competition. (Note it’s in planet.py, which is just for this competition dataset).
3 Likes
Do you think it makes sense to fine-tune it further using 0.001 steps once you have it narrowed down more? I’m thinking at some point it probably doesn’t, but I haven’t really messed with this value yet.
No not really.
2 Likes
I tried to use resnext101_64 on this and actually got a worse result which was surprising. It took much longer to run and the losses seemed to be heading in the correct direction. Going to try some of the higher resnets now.
Edit: I Just remembered I reduced the LR for resnext101_64 so I am going to try fitting it a while longer and see if I can get a better score. I’ll keep everybody updated.
1 Like
@Others,
how quickly are your networks training?
I’m running both the dog breeds and planet simultaneously. And I see the planet model trains around 1.5 it/s. Do you see similar speeds?
Edit: I’m using a p2.xlarge instance, fyi.

1.37 it/s currently. I’m on my own machine using a 1080 Ti.
Mine is around 1.5 it/s when I set precompute=False.
However, when I further do learn.unfreeze(), it drops to 1.04 it/s.
I wanted to make a submission by EOD and mostly likely I might not be able to!
@binga Your times look typical for me for the planets models, about the same as I’m getting on both Crestle for planet and AWS for dog breeds (I’m trying to multi-task lol)
1 Like
FYI I never managed to get anything bigger than Resnet50 to train well on this dataset. If you manage to do so, please let us know how! 
(In hindsight, I wish I’d spent more time trying to get them working…)
1 Like
Made my first submission for the Planet Amazon Challenge, and the result was . . . . .
0.93156
which would have put me 83rd on the public leaderboard.
I’ll take it for a first try
9 Likes
Made my first sub!
0.92990. Would have been 133rd on public leaderboard. Will try improving this in coming days.
Off to bed now, after a long day of catching-up! It’s 3AM here. 
8 Likes