Thanks you so much @KevinB. Will try this!
Thank you everyone. My score is .93067. I did pretty much what @KevinB did except that I ran once for the frozen model and once for unfrozen one! i.e. (3,1,2) equation which run 7 epochs!
Jeremy style version for preparing submission file:
fnames = [file.split(‘/’)[1].split(‘.’)[0] for file in data.test_ds.fnames]
classes = np.array(data.classes, dtype=str)
result = [" ".join(classes[np.where(pp>0.2)]) for pp in tta_test[0]]subm = np.stack([fnames, result], axis=1)
submission_file_name = “planet_rnet34_256.csv”
np.savetxt(submission_file_name, subm, fmt=“%s,%s”, header=‘image_name,tags’, comments=“”)from IPython.display import FileLink
FileLink(submission_file_name)
Thank you all. I made my first submission and scored 0.93170 on public leaderboard and 0.92998 in private leaderboard.
please add test files from additional folder.
I used p3 before. It was a bit faster but cost 3 times more. Remember to “stop” it after use.
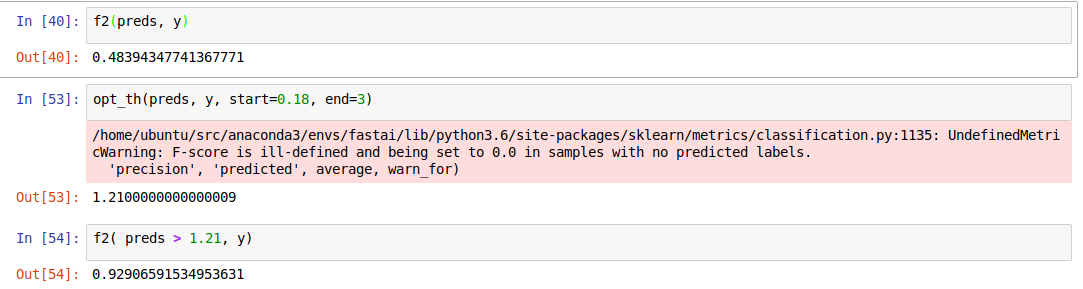
Hi all, Finally managed to get submission for this in kaggle using the tips and tricks shared here. One thing I am trying to find better explanation for when I find probability threshold using the opt_th() provided on the validation dataset. I get a threshold of 0.165 and my results on submission are slightly lower than the threshold of 0.2 that was suggested as default. Trying to figure out how the threshold of 0.2 was arrived at.
It was something folks in the comp discussed on the kaggle forum - just some trial and error really…
Thanks Jeremy. So I did more training with even larger LR for earlier layers (assuming the images are way different than imagenet and wanted to experiment beyond provided suggestions):
lrs = np.array([lr/4,lr/2,lr])
th = opt_th(val_prob, y, start=0.14, end=0.30, step=0.005)
This time I ended up with th of 0.195, private score stayed the same: 0.93007. Love the idea of empirically deriving the threshold from validation data, kind of like performing probability calibration using hold out data.
I have a number of questions. I didn’t see these answered anywhere else but sorry if I missed it!
-
@jeremy mentioned in class that because ImageNet was trained on, for example, sz=299 images, if we unfreeze the layers and train them with a different size like sz=64, it will clobber the ImageNet weights and ruin the earlier layers. But it seems like in the lesson 2 notebook, that’s exactly what he does. After he trains the last layers, he then unfreezes and trains the whole thing. Why doesn’t that clobber the earlier weights since the training is happening with a different size image?
-
Why do we sometimes use sz=224 and sometimes use sz=299? Is it about which size that particular architecture was trained on? So resnet34 requires sz=224 and resnext50 requires sz=299? (By “required” I mean that sz should be used to avoid clobbering the earlier weights if you unfreeze all layers.)
-
What is the point of changing the size of the images, freezing the layer, training, unfreezing and fitting again. Is that intended to counter overfitting?
-
What is happening to the layers of the network when we call learn.set_data(). Is it stripping off later layers and adding new ones or is just adding layers onto the end?
-
We only used data.resize() when we set sz=64. Since it’s so much faster, why didn’t we use that function again when we had the other sizes? Is that only included in the notebook to show a faster way resizing could be done, even though it’s not really necessary on this data set?
- 224 and 299 are standard Image sizes(jeremy mentioned once)
- We need to change size as Very tiny images wont make any sense…
- Regarding freezing and Unfreezing, We are trying to improve our accuracy, preventiong Overfitting and trying to minimise the loss…
That’s right - but in this case, our images (satellite) are very different to what imagenet is trained on (standard photos), so I don’t expect to need to keep all the details of the pretrained weights.
Yes it depends what it was originally trained on. We don’t have to use the same size it was trained on, but sometimes you get better results if you do.
Yes, changing size is designed to avoid overfitting.
set_data doesn’t change the model at all. It just gives it new data to train with.
Once the input size is reasonably big, the preprocessing no longer is the bottleneck, so resizing to 128x128 or larger doesn’t really help.
Thanks @jeremy. Taking your responses together with the fact that we freeze the convolutional layers when we change the image sizes with set_data, train them, and then unfreeze the layers and then train again, suggest that we are still worried about the impact of different image sizes on the weights in the convolutional layer, even though these images are significantly different from ImageNet.
Is the thinking behind the freezing and unfreezing when we change sizes that when you change the sizes of the images, the weights in the fully connected layers, although they aren’t random anymore, really should be tuned to the new image sizes before we unfreeze and train the convolutional layers on the new image sizes? Is this something you just learned from trial and error or is there a theory you can articulate behind this?
I get that you shouldn’t unfreeze the convolutional layers when the fully-connected layers are initially random, but I guess I’m having trouble getting comfortable extending that insight to when we’ve already trained the fully connected layers, albeit on differently sized images.
Thanks for this. I am trying to submit my first submission for this competition but a bit confused about learn.TTA(). Its Docstring indicates that the outputs are log_preds but you are treating them as probs, since later you compare them with threshold. And yet it seems you are getting great results. Why is that?
@layla.tadjpour
There are few changes made to the learn.TTA() by Jeremy few days back…
Have a look there and a search in the forum might help…
This link might help…
Thanks. I looked at the link you provided but it does not seem to be related to what I was asking! An any rate, do you remember if the output of learn.TTA() was log_pred or prob when you posted the above link 16 days ago?
TTA now returns class probability for each n_aug so you need to:
log_preds,y = learn.TTA()
preds = np.mean(np.exp(log_preds),0)
This should work…