Confused about my results, and looking for guidance.
My big difference is that I am forced to use a batch size of 32 because of my old GPU.
My results are all over the place when compared with Jeremy’s.
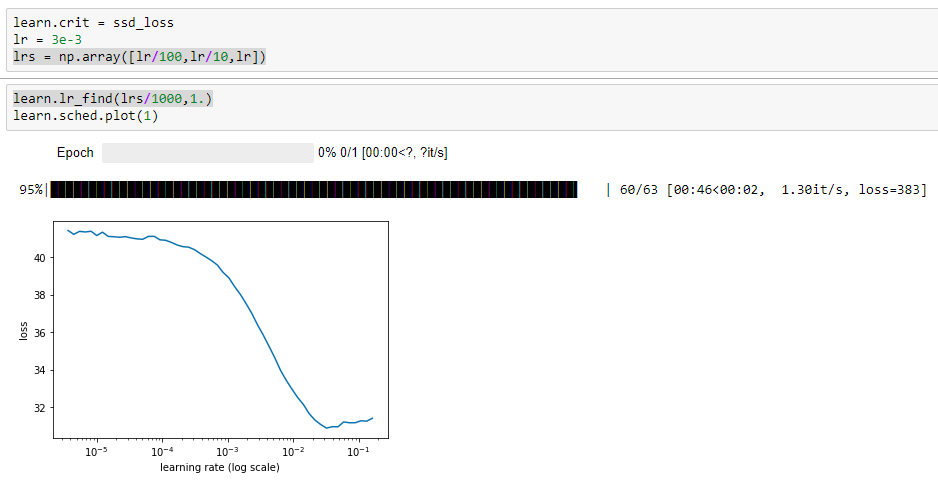
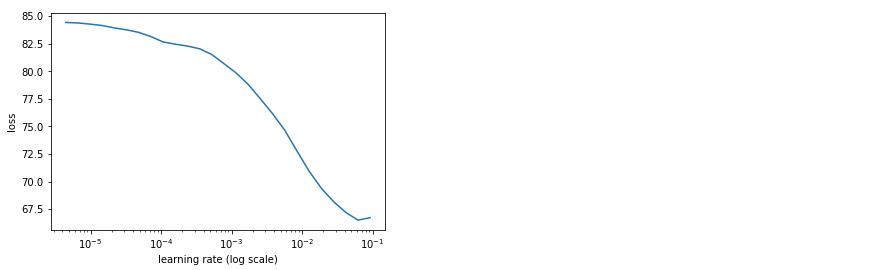
For instance after the initial learn.model() and the application of lr = 3e-3, lrs = np.array([lr/100,lr/10,lr]), learn.lr_find(lrs/1000,1.)
My plot:
Jeremy’s plot:
Then after learn.fit(lr, 1, cycle_len=5, use_clr=(20,10))
My results:
epoch trn_loss val_loss
0 19.368023 15.716943
1 15.620254 14.04254
2 13.78509 13.574283
3 12.395073 13.149381
4 11.260969 12.904029
[12.904029130935669]
Jeremy’s:
epoch trn_loss val_loss
0 43.166077 32.56049
1 33.731625 28.329123
2 29.498006 27.387726
3 26.590789 26.043869
4 24.470896 25.746592
[25.746592]
Well, this looks good at this stage, but why is everything roughly half / twice?
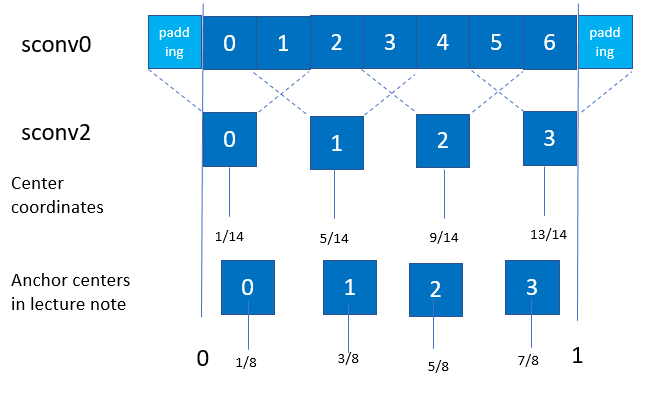
But after all of the next process of testing, creating more anchors, then the Model section we come to:
learn.crit = ssd_loss
lr = 1e-2
lrs = np.array([lr/100,lr/10,lr])
x,y = next(iter(md.val_dl))
x,y = V(x),V(y)
batch = learn.model(V(x))
batch[0].size(),batch[1].size()
(torch.Size([32, 189, 21]), torch.Size([32, 189, 4]))
ssd_loss(batch, y, True)
I end up with this:
Variable containing:
164.1034
[torch.cuda.FloatTensor of size 1 (GPU 0)]
Jeremy has:
Variable containing:
4.5301
[torch.cuda.FloatTensor of size 1 (GPU 0)]
Variable containing:
61.3364
[torch.cuda.FloatTensor of size 1 (GPU 0)]
Variable containing:
65.8664
[torch.cuda.FloatTensor of size 1 (GPU 0)]
Only one Variable in my notebook?
After learn.lr_find(lrs/1000,1.), learn.sched.plot(n_skip_end=2), and plot I have:
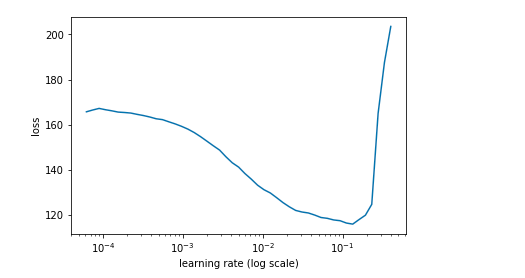
Jeremy has:
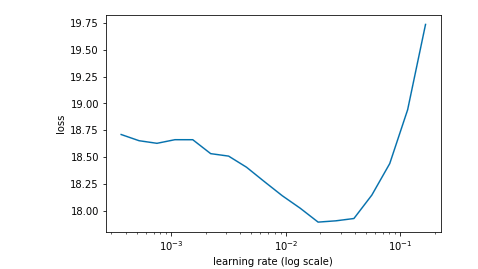
With learn.fit(lrs, 1, cycle_len=4, use_clr=(20,8)) I have:
epoch trn_loss val_loss
0 72.285796 57.328072
1 57.207861 48.549717
2 48.630814 44.12774
3 43.100264 41.231654
Jeremy has:
epoch trn_loss val_loss
0 23.020269 22.007149
1 19.23732 15.323267
2 16.612079 13.967303
3 14.706582 12.920008
[12.920008]
After that I do my best at adjusting the lr (and subsequent lrs) and use_clr
e.g. tried lr = 1e-3, tried use_clr=(60,10) and got this upon retesting lr:
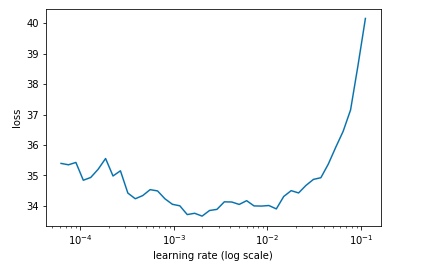
But the best I’ve achieved is this and I’m just spinning my wheels:
epoch trn_loss val_loss
0 33.419068 39.042112
1 32.294365 38.817078
2 31.792605 38.655365
3 31.260753 38.581855
ANY ADVICE ANYONE?