No problem. I don’t think it’s important for this anyways.
2 Likes
Hiromi- thanks for putting this together!!!
Sure  It’s just some scribble I did a while ago.
It’s just some scribble I did a while ago.
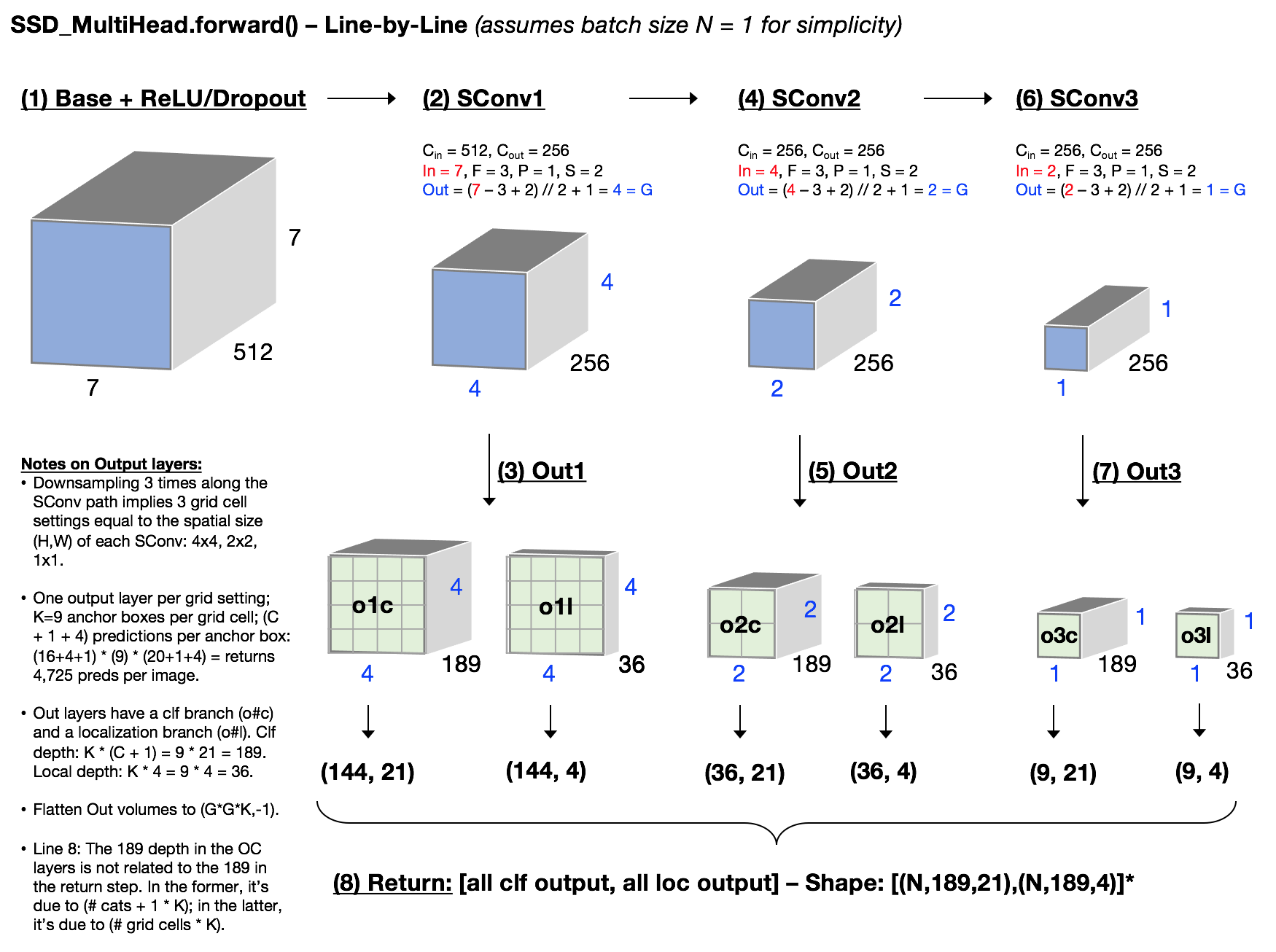
Dovetailing with @daveluo 's awesome whiteboarding of SSD_MultiHead (thank you for that!) - I also found it really helpful to spend time diagramming / visualizing the forward line-by-line. Attaching screenshot here in case helpful for anyone else…
25 Likes
I’d love to show that in class (with credit of course!) - would that be OK? If so, would you prefer me to credit your forum user name, or your real name (if the latter, please tell me your real name)?
2 Likes
Hey everyone…
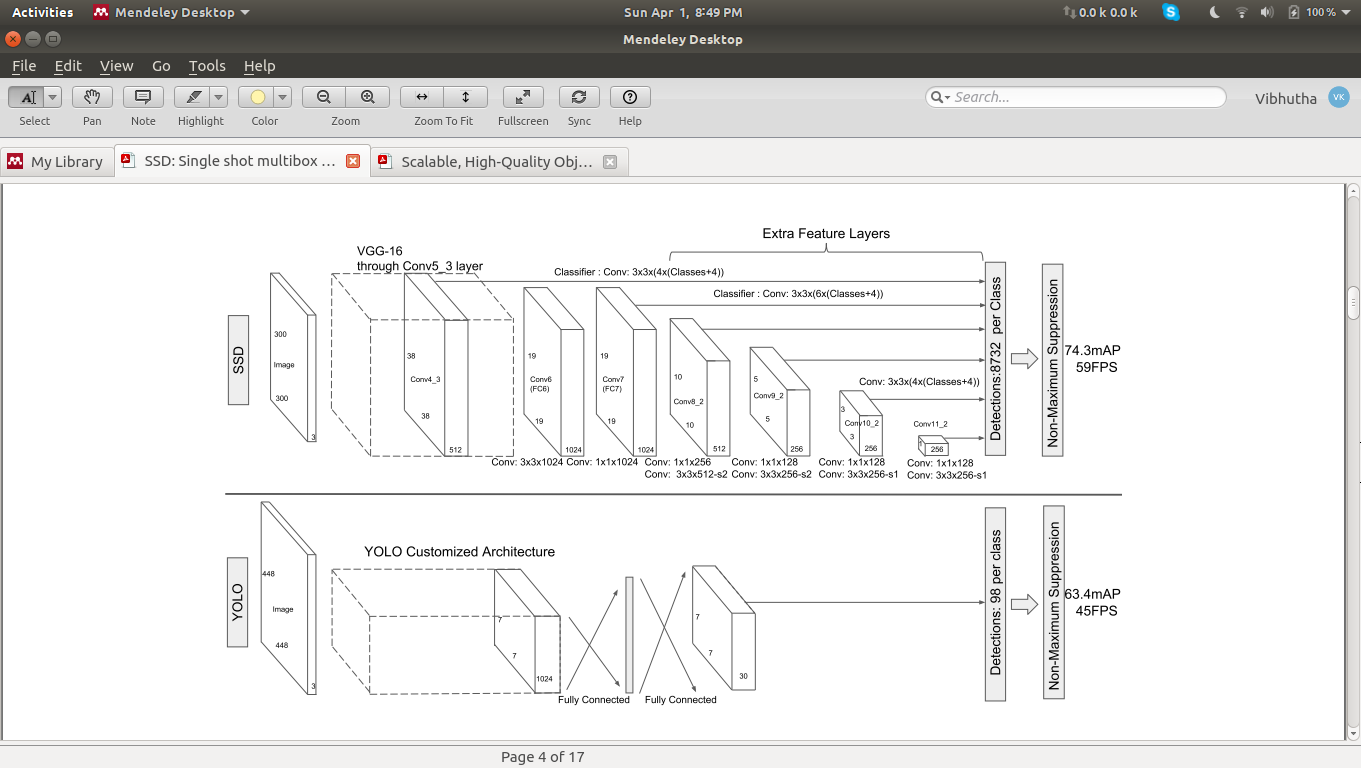
I faced a problem when I’m reading the SSD paper  … Can anyone tell me how Detections: 8732 per class is calculated in the SSD network?..
… Can anyone tell me how Detections: 8732 per class is calculated in the SSD network?.. 
Thank you…

Sure! But you try first How many detections do you calculate based on what you’ve read? Take us through your thinking and we’ll figure this out together.
Hey everyone.
I think, I found a little bug in pascal-multi.ipynb.
It is a peace of code in the very beginning when we predict multiple classes and plot pictures with one or more predicted labels:
for i,ax in enumerate(axes.flat):
ima=md.val_ds.denorm(x)[i]
ya = np.nonzero(y[i]>0.4)[0]
b = '\n'.join(md.classes[o] for o in ya)
ax = show_img(ima, ax=ax)
draw_text(ax, (0,0), b)
plt.tight_layout()
I found, that ya = np.nonzero(y[i]>0.4)[0] is one object and the code always plots only one class instead of several.
So I removed [0] and added int(o) (to convert from torch.cuda.LongTensor dtype) in b definition. Like this
for i,ax in enumerate(axes.flat):
ima=md.val_ds.denorm(x)[i]
ya = np.nonzero(y[i]>0.4)
b = '\n'.join(md.classes[int(o)] for o in ya)
ax = show_img(ima, ax=ax)
draw_text(ax, (0,0), b)
Now it works well.
Should I create a pull request for this?
1 Like
What is the best way to deal with images with a different aspect ratio? For example, I have a dataset with images of size 375x1242. Width is 3.3 times larger than height. Resizing the images to a square shape expected by pretrained Imagenet models will lead to unrealistically looking images.
Is there any way to leverage pretrained image classification models in this case, or it’s better to create SSD model with an appropriate aspect ratio and train it from scratch?
1 Like
Good list of Criterions for better understanding https://github.com/torch/nn/blob/master/doc/criterion.md
2 Likes
This is great! Just as clarifying statement, if someone had the same doubt as me. If you are wondering why do we have an extra output for background (20 + 1), refer to this:
3 Likes
I was never able to get my verification loss much below 10, but changing the bias from -4 to -3 worked much better in terms of the suppression of false positives.
Sure thing! I’ve updated my forum name to match my real name (Chloe Sultan).
1 Like
It works for me - you can see in the ppt and the notebook that it shows multiple classes for some images. Also the numpy docs show that it returns a tuple. So now I’m confused as to what problem you had! Can you go back and double-check, and if you’re sure it’s not working, show some sample code that demonstrates that?
Oh, you’re right! That’s funny because I would have expected the opposite, given the fact it’s harder to predict a category other than background with a stronger negative bias.
Loved this video, here’s a link to a spreadsheet that follows the examples in the video.
3 Likes
I was trying to attempt this and I made 2 changes.
- Removed the +1 in the oconv1 to exclude background.
- In the BCE_loss, I used all the columns -
x = pred[:,:]
instead of
x = pred[:,:-1]
for matching the dimensions.
The loss was more or less the same. Maybe I haven’t trained it well enough but there are incorrect annotation predictions.
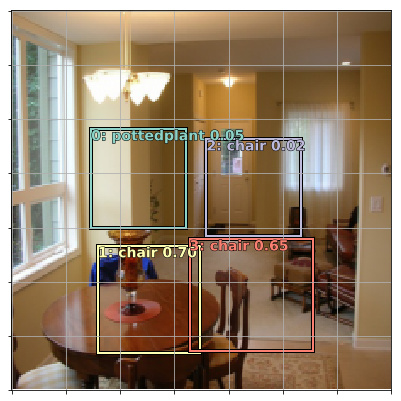
I adjusted the threshold to 0.2 and now the incorrect annotations are gone.

Thresholding seems important.
Am I on the right path? I’m still not sure if I’ve made all the changes to arrive at the right result.
The notebook is here (https://github.com/binga/fastai_notes/blob/master/experiments/notebooks/pascal-multi-without-background-in-conv-exercise.ipynb). See In [103]: & In [104]: code blocks.
2 Likes