Thanks a lot Jeremy and Rachel for this awesome course! it really gives a lot of insight. Before fast.ai i wanted to learn about AI/ML with no idea where to start, tried a few times in the last 2 years but it never clicked. now after only 4-5 months of fast.ai i’m confident that i can understand the concepts behind a paper or blog post and get started on reproducing similar results (given enough time), and that i just need to practice (a lot :D) to become good at it. The quantity of (actionable!) knowledge you give us is just great! Thanks again.
Jeremy mentioned in the lecture that there’s an ongoing project in the forum that someone uses U-net to improve the SSD’s bounding box model on small objects. Does anyone know which post he is referring to?
Here you go: http://forums.fast.ai/t/retina-net/14793/5
Edit: You might also want to go through this - http://forums.fast.ai/t/dynamic-unet/14619
3 Likes
Thank you Jeremy and Rachel for this wonderful course. I am sad it has finished. I think your purpose to make practical machine learning and DL accessible to a vast audience is definitely a success! Now what ? Some spot lessons where interesting paper/techniques are discussed and implemented ? A kind of channel for the student of all years to stay tuned for a continuous update…
Thank you Jeremy and Rachel for providing the opportunity to be part of this journey…
Thank-you very very much for the opportunity to learn so much from you Jeremy and Rachel, it’s been fantastic!
Hi,
I missed live lesson, and now live stream link points to 16 minutes record, looks like it is the last part. When are you planning to upload whole video?
3 Likes
Hi,
I found the first link in the edit history of the first post 
5 Likes
Lesson video added to top post. (Processing now - will be available in ~20 mins).
1 Like
What’s your understanding of that part of the paper at this stage? Which bits are you not sure about?
VGG16 is in the loss function, not the model.
If we set requires_grad to False then it’s not learnable - e.g. a pretrained net we’re not fine-tuning.
Yes. Although if you don’t have >1 GPU you shouldn’t use this at all, of course.
1 Like
See lesson 2.
There’s still a little pixelation there - I think it might be because I didn’t use a sufficiently good down-sampling method to create the 288x288 versions. I’m not sure - will be interested to hear if anyhow can create a better version…
1 Like
I didn’t have a chance to try it - would be interested to hear results of those that do!
I am a big fan of the course To the point that when I try to express how much I appreciate it i feel I must sound like a lunatic.
My two newest discoveries are this:
I have fallen way behind on coursework partially due to not having enough time and partially due to how I learn. But thanks to the fastai curriculum I now feel this is okay. I am confident I can learn the material, even if it takes me another couple of months. That is a very big change for me.
The second, much bigger discovery, is the community. The insightful posts people write on the forum. The amazing blog posts. The top notch library contributions. Yesterday I studied SWA so elegantly implemented by @wdhorton. I continue to learn from the resources that @sgugger shares and both the 1cycle and the new training API are such an enormous and fantastic addition to our toolbox. And those are just two areas I have focused on recently, but the list of people I have learned from would go on and on if I were to continue to name them.
And of course none of this journey that I find so rewarding and marvelous would have happened if it weren’t for Jeremy and Rachel (I learned about fastai from one of Rachel’s blog posts and her advice has been what shaped my dive into the material, including starting to blog). In the greatest understatement of the century, that is rather nice 
I am grateful beyond words for how enriching being part of this community is for me.
18 Likes
Thank you so much for the course and materials, it was an absolute delight to learn from you two. I’ve been a huge fan of fast.ai’s top-down approach, and this time I ended up learning far more than I ever even expected! I sure feel competent enough now to even apply them to an actual, full scale project someday soon, and am definitely grateful for that.
Edge of the Envelope:
This one really pushes the machine to the edge of it’s envelope. Mine crashed first few times I ran this. The reason seems to be the number of worker threads assigned to do the transforms.
md = ImageData(PATH, datasets, bs, num_workers=12, classes=None)
Changing this to “num_workers =nw” where nw is set to the number of CPU cores / 2 seems to work without crashing the machine. Also obviously you want to assign the GPUs as suggested by Jeremy.
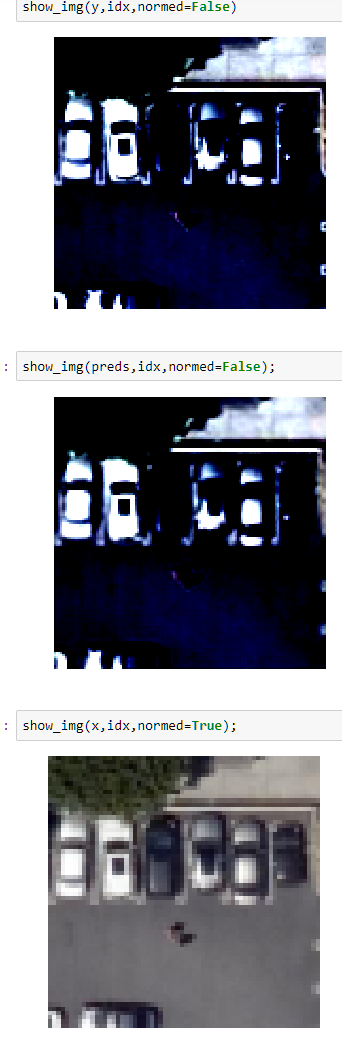
I’m trying out super-resolution (awesome stuff!) to sharpen satellite imagery (in jpeg format).
The predicted and target images have the wrong colors… looks like its something to do with the denormalization or RGB channel order in the images (is there such a thing?). Has anyone seen something like this?