I’ve been trying to implement a FPN as well and running into similar issues where everything I’ve tried performed worse than my baseline: a nearly default pascal-multi that gives mAP=30.4%. Here’s my baseline notebook.
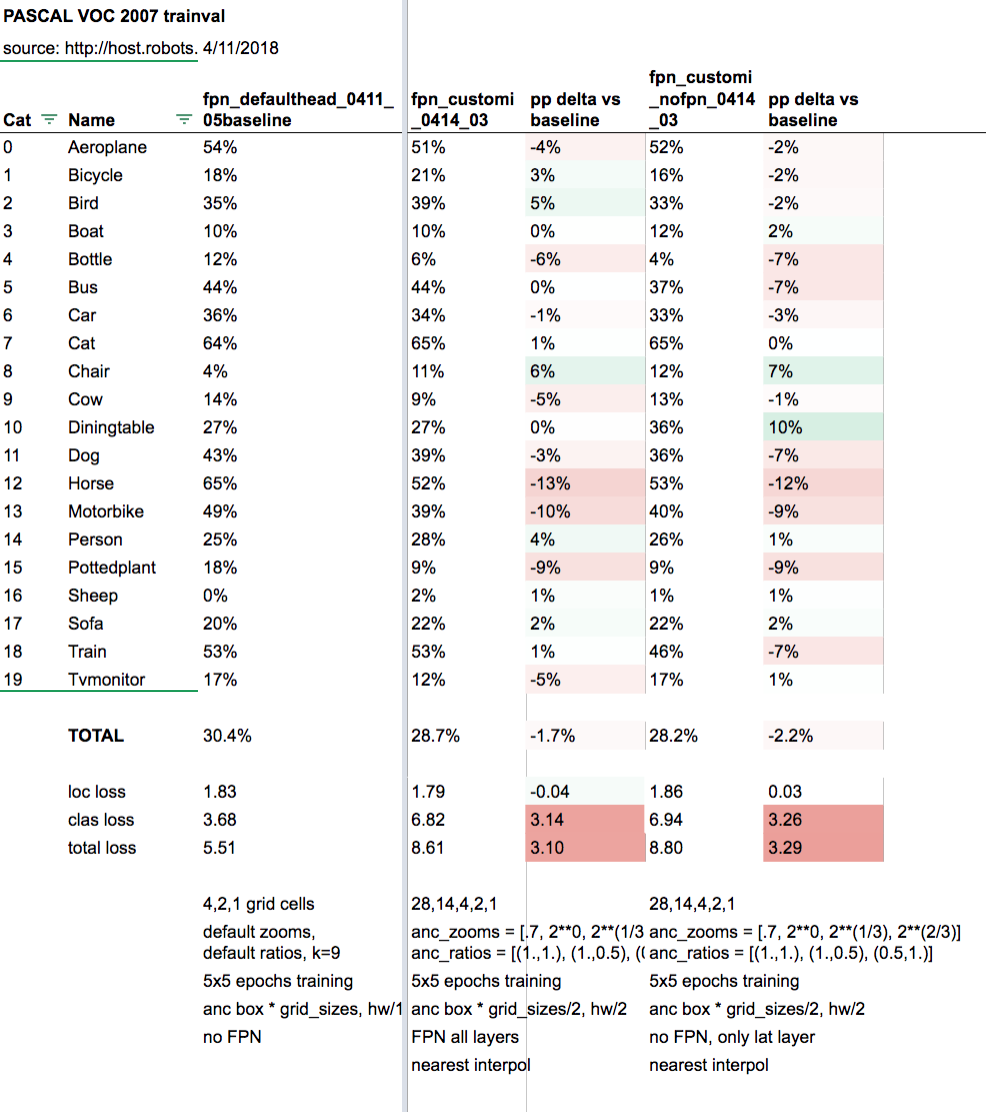
The best mAP with my FPN implementation I got so far is 28.7% using a [28, 14, 4, 2, 1] scale pyramid with k=12. Thanks @sgugger for some helpful functions and techniques in customizing the model. Here’s that notebook: https://github.com/daveluo/fpn/blob/master/FPN_heavycustom_0414.ipynb
I’m not faithfully recreating retinanet in full - just applying the concept of a FPN (correctly I hope) to the default pascal-multi resnet34 backbone and head to try to improve its performance.
I’ve tried systematic variations using every scale level from 56 to 1, a range of zooms and aspect ratios, different matching and NMS thresholds, bilinear vs nearest interpolation for upsampling, etc. but they all performed worse.
To see if my FPN implementation did anything at all, I removed the lateral+upsamp step from my best implementation and directly connected the lateral kernel_size=1 conv outputs to my outconvs at each scale level. Keeping everything else the same, this gave a mAP of 28.2% so there seems to be a small (+0.5% mAP) benefit to the upsampling and addition step. Maybe that’s an insignificant difference? Here’s that notebook: https://github.com/daveluo/fpn/blob/master/FPN_heavycustom_0414-nofpn.ipynb
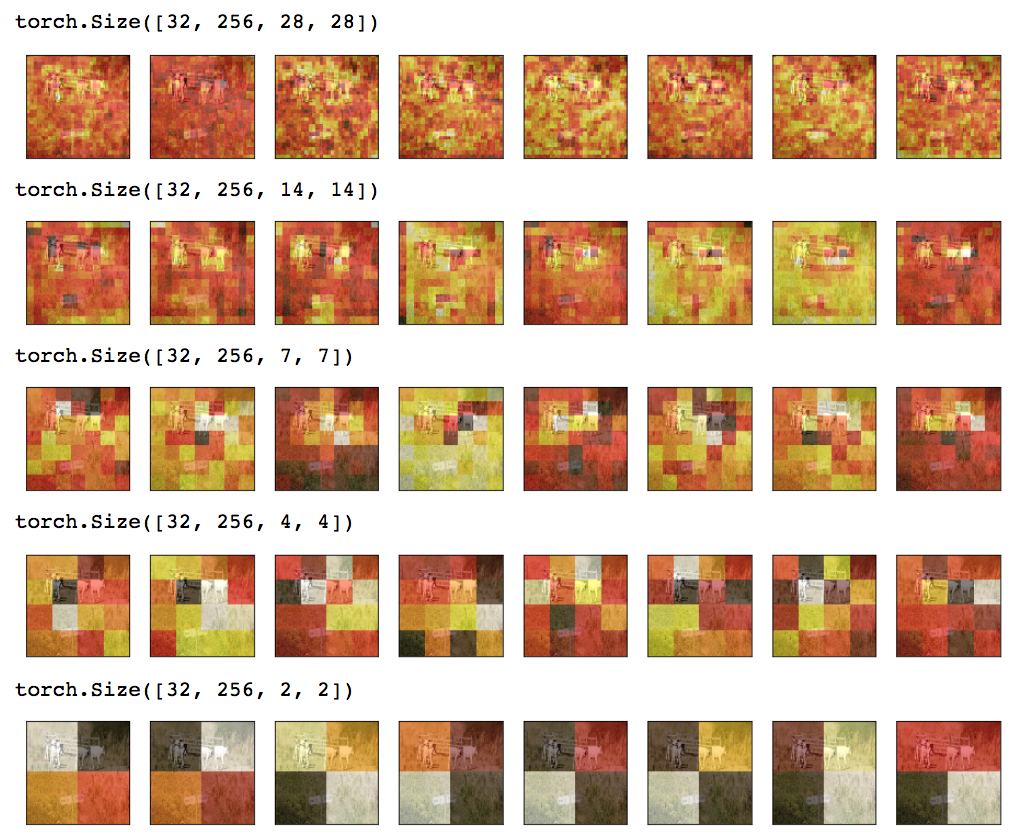
To debug and better understand what’s happening, I used pdb and stepped through the forward loop to confirm each part happened as expected. I also used the heatmap technique to visualize outputs at each scale. Looks like what we should expect:

Compare this to the notebook where I skip the lateral+upsamp step (note the difference of activation near the cows at each scale):
So I’m also still at a loss for where our implementations are going wrong  I don’t think the mAP calculation is wrong because I’ve found that my visual inspection of the predictions vs gt bboxes lines up pretty closely with changes in the mAP and it is calculating as I’d expect in other applications.
I don’t think the mAP calculation is wrong because I’ve found that my visual inspection of the predictions vs gt bboxes lines up pretty closely with changes in the mAP and it is calculating as I’d expect in other applications.
Also if helpful, here’s a comparison of the class APs and loss scores across the 3 models I’ve referenced and linked (baseline vs FPN vs not-FPN):