I am interested as well.
1 Like
Hi I would like to join this study group. If it’s possible.
1 Like
Hi, I would like to join the study group. Please add me in too.
1 Like
I am interested.
1 Like
I am also interested to join this study group
1 Like
Hello, I am interested too.
1 Like
Hi everyone I am interested too
1 Like
Great @chinmaydas! We are having an online meetup in 1 hour  Join Zoom at 3PM GMT https://zoom.us/j/564723458
Join Zoom at 3PM GMT https://zoom.us/j/564723458
1 Like
We used up free 40 min of Zoom, this is the new link for today https://zoom.us/j/641244020?pwd=T0V5c2VMS0lYOEpWVmFwY2ZwTU9UQT09
1 Like
Hi,
I feel like I am a little late for today’s meetup but I am very much interested in these meetups.
1 Like
Hello. I’m currently in the middle of exams but still would love to join the slack group and meetups. Please invite me!
1 Like
Hello everyone. I am a high school student from Waterloo and I am interested in being a part of the group. Unfortunately, I was unavailable for today’s meeting but I would love to join the slack and be a part of future discussions!
Thanks!
2 Likes
Hi, I’m interested too please send me the invite for upcoming events.
1 Like
Hey guys i started the Deep learning course 3 days ago , so i am new in this and it’s not easy, how to set up the dataBunch for Flowers Dataset.

1 Like
Hi @Miske! One idea is to transform text files into a dataframe. The df should have 3 columns: name of image, label of an image, and whether it is from a validation set. E.g:
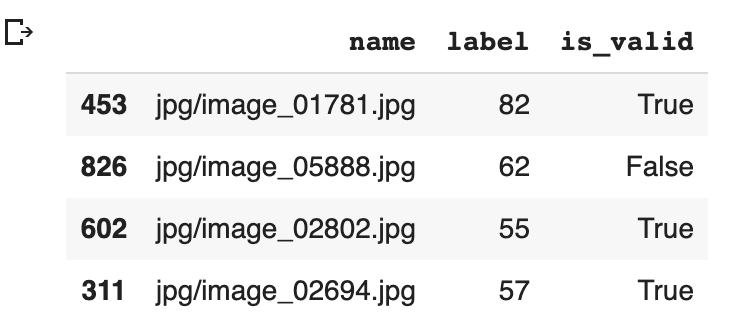
Then you can use
ImageList.from_df(your_df, path).split_from_df(). You can read more in the docs.
Here is the sample code that worked for me:
from fastai.vision import *
path = untar_data('https://s3.amazonaws.com/fast-ai-imageclas/oxford-102-flowers'); path
#Take txt file and turn it to df, add new col
cols = ["name", "label"]
train = pd.read_csv(path/'train.txt', sep=" ", names= cols )
train ["is_valid"] = False
valid = pd.read_csv(path/'valid.txt', sep=" ", names= cols )
valid ["is_valid"] = True
#Join train and valid dataframes
train = train.append(valid)
train.sample(4)
tfms = get_transforms()
data = (ImageList.from_df(train, path)
.split_from_df()
.label_from_df()
.transform(tfms, size=64)
.databunch()
.normalize(imagenet_stats))
data
You will also need to create the second DataBunch for the test data.
P.S. I am also a beginner, so there might be a more elegant solution 
1 Like
Hi, I would like to join as well!
1 Like
#meetup_notes
We had our 4th meetup on 30th of November! More people joined thanks to @jeremy ’s tweet  Thanks everyone for the meetup and there will be another one next Saturday at 3PM GMT
Thanks everyone for the meetup and there will be another one next Saturday at 3PM GMT 
Project. We talked about our first Kaggle challenge: Kannada MNIST. Our biggest trouble was to configure proper DataBunch for training set. So we discussed how to turn tabular data into images and how to add pretrained models to the kernel. We are far from the top of the leaderboard, and therefore we will keep working on the challenge during the coming week. 
Lessons. More beginners joined this time. So @rugan01 went through the notebook for Lesson 1, and we discussed the main learnings from it. We also talked about cloud platforms (GCP, AWS), experience with Google Colab, data augmentation and transfer learning. 
Communication. We decided to post all questions related to fastai in the fastai forum and have this thread as the main communication channel. There is also an open slack channel for discussions regarding the projects and chit chats. 
P.S. The meetup is informal and dedicated for sharing, learning, and keeping each other motivated. Feel free to join anytime, you will not be late, usually, people discuss/present/ask questions from the lesson they are in.
P.S.S. Currently we are using a free version of Zoom for meetups but it disconnects every 45 mins. What do you guys think, can we get unlimited calls in any other platform? Or crowdsource/rotate payment for zoom? The upgrade is 15$.
2 Likes
Thanks for the update @shahnoza!
1 Like
Thanks @shahnoza it worked perfect . Thank you this solution is elegant and more than a nought for me . You own me one .
1 Like