So I did about 100 epochs of fine-tuning on full-sized images.
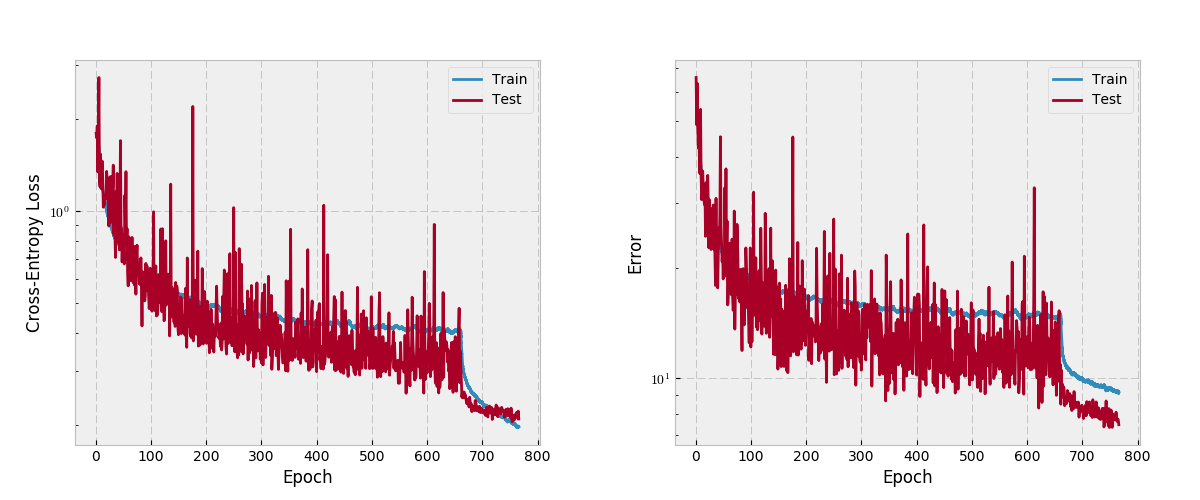
Epoch, Loss, Error for the Validation Set towards the end of fine-tuning:
762,0.21971764021060047,7.808109411764708
763,0.21415826298442542,7.631791764705883
764,0.2103811400193794,7.758129803921568
765,0.22203320849175548,7.704945882352942
766, 0.209, 7.48
Test Set Results
Loss: 0.4357, Error: 13.2225, Accuracy: 86.77
So fine-tuning reduced error by -2.6%, but we’re still above the authors reported 9.2% error.
Some thoughts:
- I manually stopped both the initial training stage and fine-tuning stages early (I was afraid to overfit, but mostly impatient). I think my accuracy could improve with longer training. I was just eager to test the images.
- I didn’t do the random horizontal flip augmentation during the fine-tuning stage. The authors don’t mention whether they continued this technique during finetuning (they also say they used vertical flips, but I thought I saw in their code they used horizontal flips)
- I think we’re on the right track and what the authors claim is plausible. I’ll just have to do some more experimenting. Next step is to refactor my code to handle the FCDenseNet103.
Image:

Target
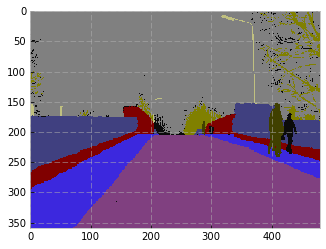
Predicted
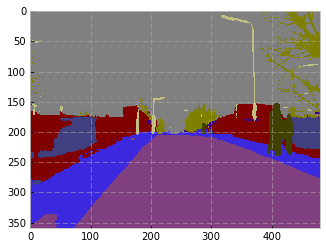
Image

Target
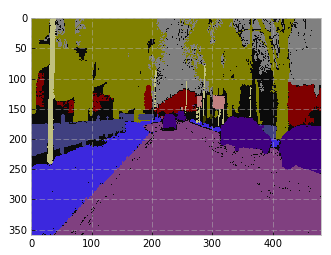
Prediction
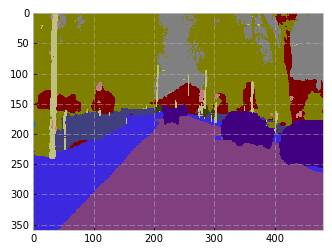
Example from the Author’s paper

Our result for the same image (Target, then Prediction)
