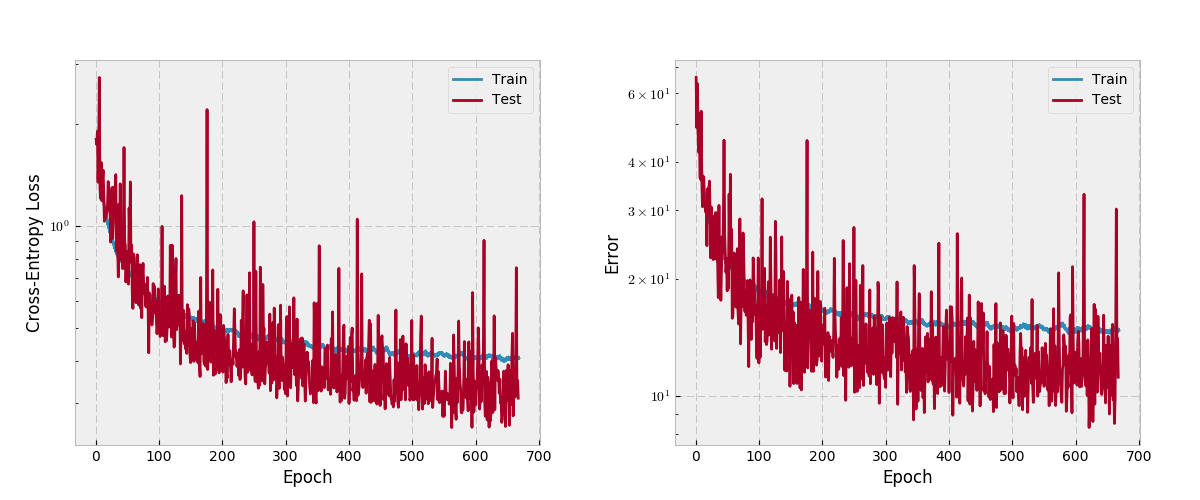
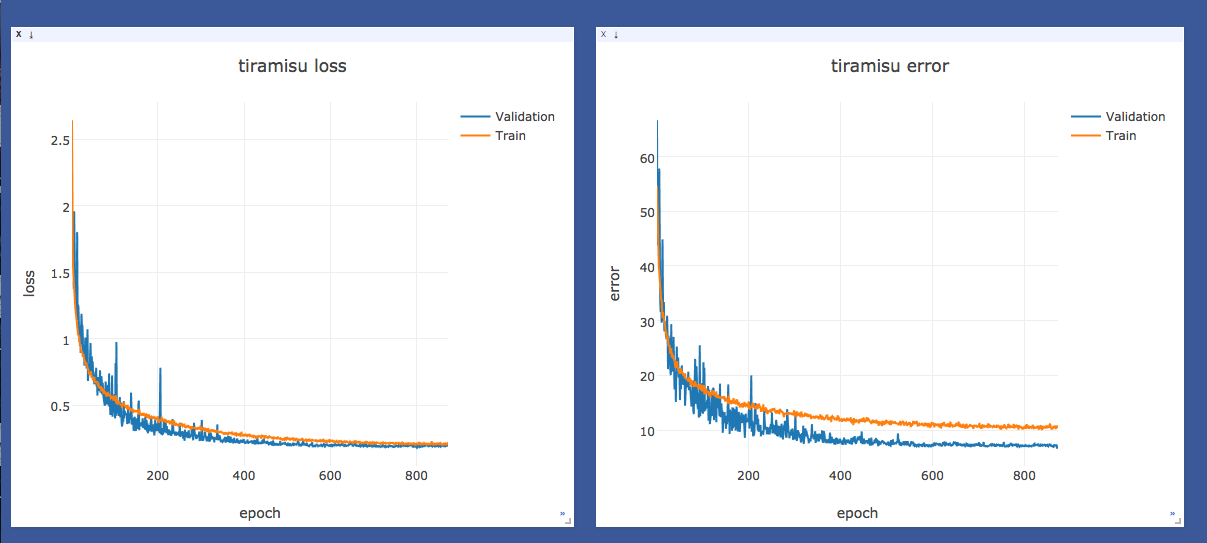
Amazingly, I think it’s still going down? Does the jaggedness suggest I should bring down the learning rate? I’m using vanilla RMSProp, which I thought had its own logic for tuning learning rates… The authors mention they used RMPProp with .001 learning rate with .995 exponential decay. Unlike other frameworks, PyTorch RMSProp doesn’t mention lr decay as a parameter: http://pytorch.org/docs/optim.html#torch.optim.RMSprop
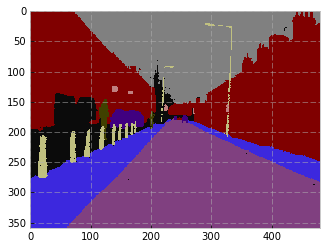
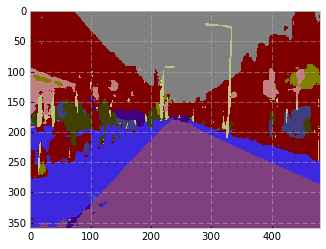
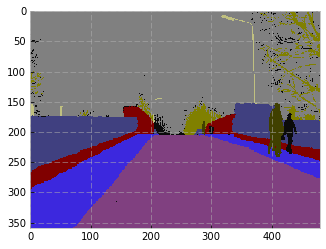
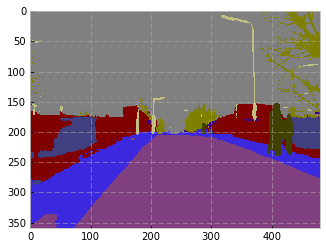
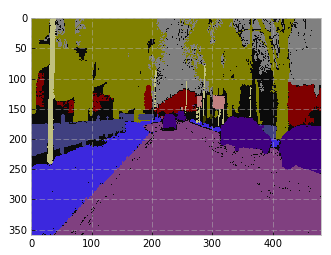
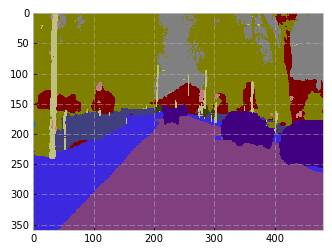
The model is FC-DenseNet67. The ‘test’ set is the 103 image validation set. My lowest error on the validation set is around 8.5%. My error on the test set is ~15.8%. Strange. In the paper, the authors mention “global accuracy” of 90.8 for FC-DenseNet67 on Camvid. They also cite IoU, but I haven’t implemented that yet.
According to the authors, the next step is to fine-tune the model on full-sized images.
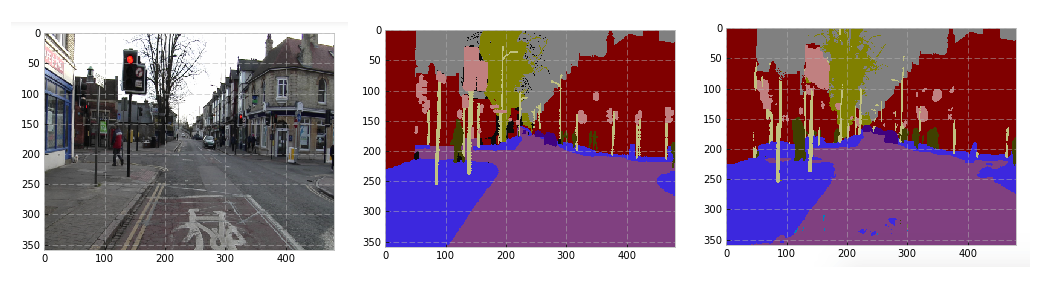
The predictions on the test set aren’t bad, but they’re not matching the author’s results. Even though my validation error < 10, the test error of 15 is probably the cause.
Let me see what happens when I finetune…
Current Questions/Things To Explore:
Implement IoU metric
Add patience function to early stop training after 150 epochs with no improvement
“For batch normalization, we use current batch statistics at training, validation and test time” Do I need to implement this?
RMSProp with .995 exponential decay. How is this handled in PyTorch?
In Pytorch, it’s not enough to save weights if you want to resume training later. It looks like we also need to save the optimizer state as well. I made this mistake and my “pretrained” weights performed poorly when I resumed training.
What do the authors mean when they say it would be interesting to “pretrain” FC-DenseNet? Change the model’s final layer for handle classification and run it through imagenet?
Preloaded class weights - According to this people often adjust their class weights (how much each class contributes to the total error/loss) to account for the image imbalance between different classes. Some classes are underrepresented in CamVid. I found a copy of these weights and I’m using them. It’s useful to confirm if I’m doing the right thing.
I’m using Negative Log Likelihood since PyTorch had a nice 2D version. The authors use Cross Entropy loss, but I believe in this case they end up being the same thing? Need to confirm.
Pascal VOC - I looks like the authors tried training on this dataset but were unable to achieve convergence? We made a first attempt on PascalVOC and it did not converge until we use Adam optimizer but it ended with poor results. That doesn’t sound promising? Do you think they were just in a rush to publish?
Other users have struggled to reproduce the results in the paper. For example here.
Ugh - that’s a worry… Especially since that’s in the original authors’ repo. I guess we should run the lasagne code ourselves.
Pre-training simply means taking a model that was trained on imagenet (which I believe pytorch has) and using those weights in the downwards path. Then (I assume) just train the upward path, and then finetune on the whole lot.
@kelvin that’s great that you included the log in github - thanks! Is this DenseNet103? I assume the first few columns are train, and last few are test? If so, then the best test result is:
loss = 0.24795 | jacc = 0.77115 | acc = 0.9440
But table 3 in the paper shows best IoU of 66.9 and accuracy of 91.5. Are these measuring different things? Are you able to match the paper’s results?
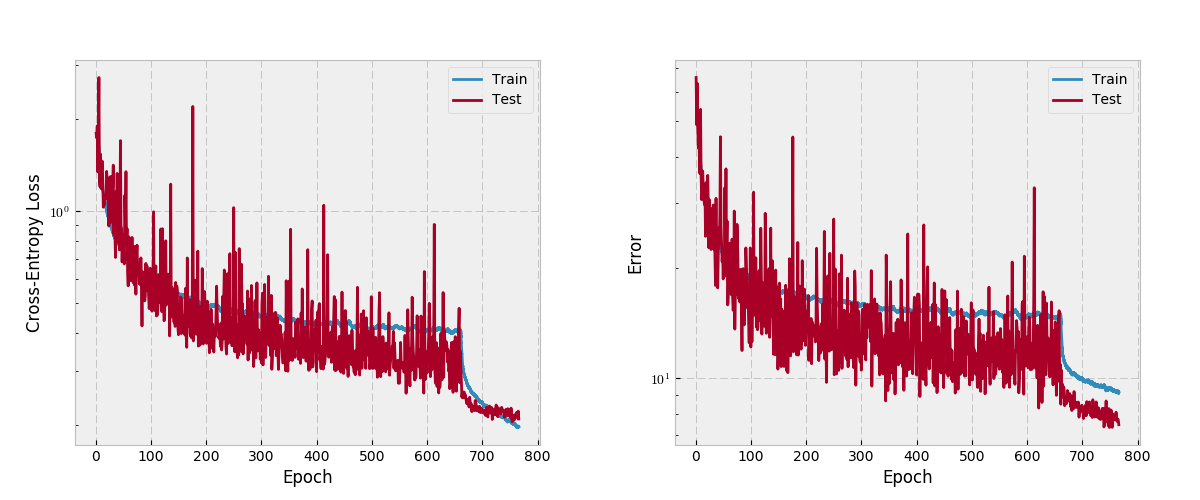
Epoch, Loss, Error for the Validation Set towards the end of fine-tuning:
762,0.21971764021060047,7.808109411764708
763,0.21415826298442542,7.631791764705883
764,0.2103811400193794,7.758129803921568
765,0.22203320849175548,7.704945882352942 766, 0.209, 7.48
Test Set Results
Loss: 0.4357, Error: 13.2225, Accuracy: 86.77
So fine-tuning reduced error by -2.6%, but we’re still above the authors reported 9.2% error.
Some thoughts:
I manually stopped both the initial training stage and fine-tuning stages early (I was afraid to overfit, but mostly impatient). I think my accuracy could improve with longer training. I was just eager to test the images.
I didn’t do the random horizontal flip augmentation during the fine-tuning stage. The authors don’t mention whether they continued this technique during finetuning (they also say they used vertical flips, but I thought I saw in their code they used horizontal flips)
I think we’re on the right track and what the authors claim is plausible. I’ll just have to do some more experimenting. Next step is to refactor my code to handle the FCDenseNet103.
This is where I last trained the model (well before the 750 epochs):
Epoch 0 took 81+25 sec. loss = 0.79147 | jacc = 0.44204 | acc = 0.77681 || loss = 0.47174 | jacc = 0.57472 | acc = 0.87108 (BEST)
Average cost test = 0.65018 | jacc test = 0.47502 | acc_test = 0.80233
I’ll run it for a bit longer to see where it gets to.
Does anyone know what is the state of the art for unsupervised segmentation? Semantic segmentation is not required (Just foreground/background classification is sufficient). Or any easy to implement methods?
There are no labels for the objects at all, but we would like to generate patches for the objects, so that we can identify exactly what is an object and where it is in the picture. So, the notion of what is an object is fuzzy – but in general, it is something which is distinct from the background.
For the FCDenseNet67, my best accuracy was 87.6%on the test set (I used the validation set during training) after about 600 train epochs and 600 fine-tune epochs. But I cut training short.
I’m retraining with FCDenseNet-103, this time using the learning rate decay and early stopping with max patience. I just completed 874 epochs of training on this new net and achieved accuracy of 86.6%. (But max patience was not triggered so I could have continued training).
I’m about to start fine-tuning on the full-sized images (including random horizontal flips) with max patience of 50. I’ll send you the test scores later today. Or you can follow my training at my cool website


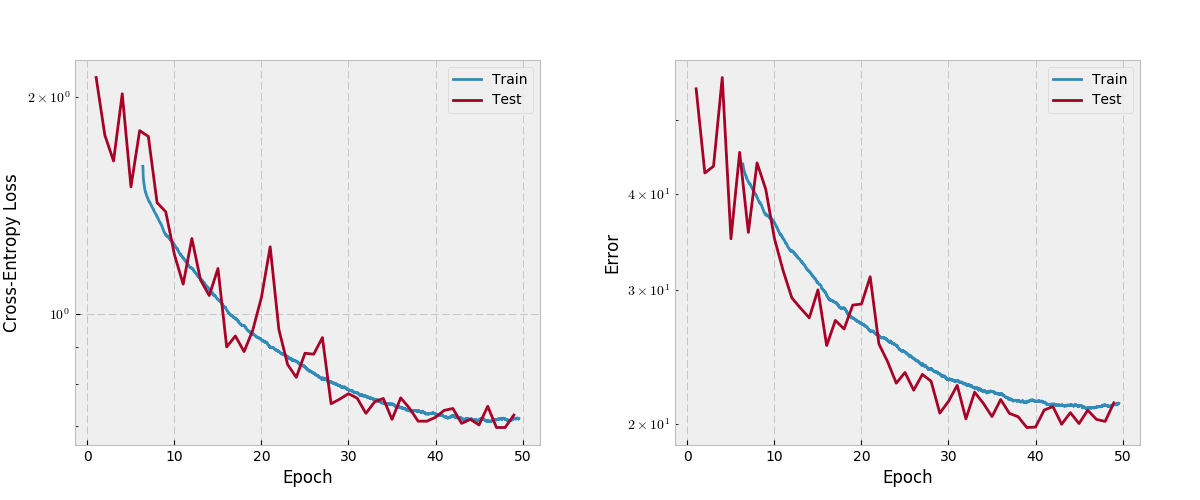
 Strange. In the paper, the authors mention “global accuracy” of 90.8 for FC-DenseNet67 on Camvid. They also cite IoU, but I haven’t implemented that yet.
Strange. In the paper, the authors mention “global accuracy” of 90.8 for FC-DenseNet67 on Camvid. They also cite IoU, but I haven’t implemented that yet.