Oops sorry couldn’t make it - got called into a meeting!
4 Likes
Oops looks like Zoom might have closed. Running again now. I’m hoping to be available at the times in Orange on this pic (pacific time):
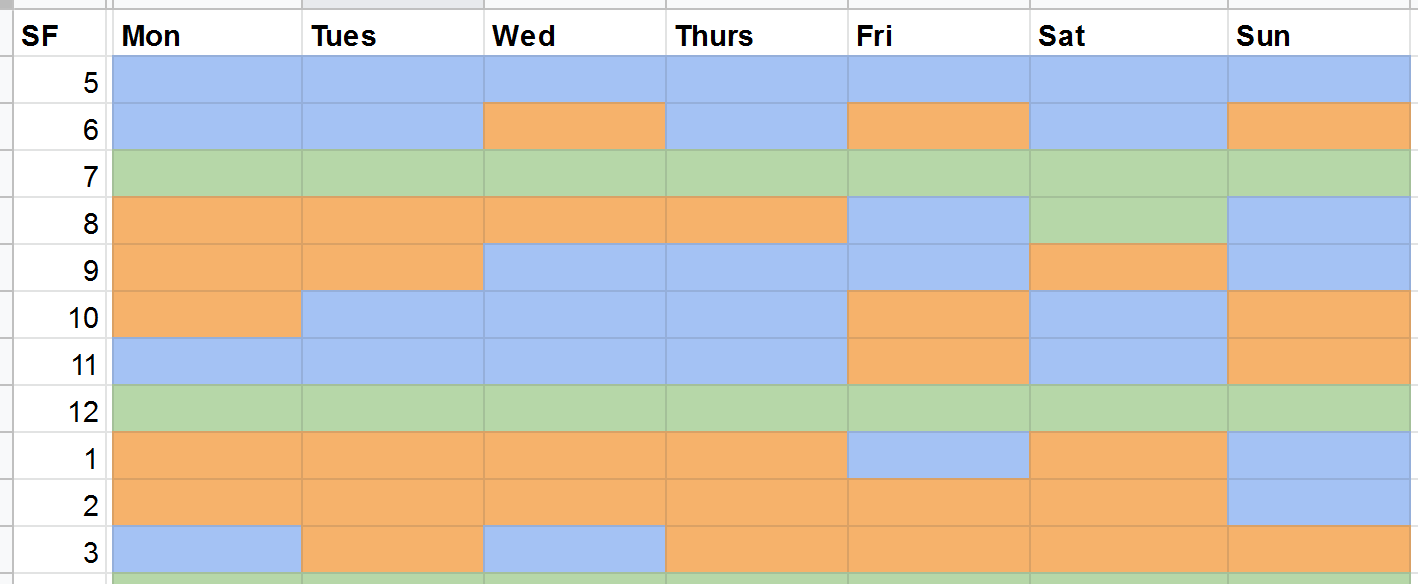
5 Likes
Anyone interested in trying their hands at a Healthcare Big Data Challenge with the NIH(Hearth Failure Data Challenge)? This just popped up in my email and it looks like a fun challenge.
5 Likes
@jeremy we cannot share the screen on Zoom meeting, and no one is host. Can you please turn it on when you get a chance?
Thank you! 
@Jess Great suggestions!
@jeremy One more idea: similar to how companies have “onboarding buddies” perhaps all the women (or maybe everyone?) in the class can get an assigned “fastai buddy”, a person they could reach out to for 1:1 questions and weekly check ins - to get help setup on Discourse, get over the hump of getting notebooks running, etc. Ideally the buddy would be a little further along and in a similar time zone, but the buddy could also be a classmate.
If this were an in-person class these are friends we might have made on the first day, but thanks to covid we can get creative and set this up with a google form asking general availability (9-5pm, evenings, weekends, etc), time zone, and pairing people up ourselves.
My personal strategy has been virtual coworking hrs M-F with friends also taking the course until I got through enough reading and code to think of project ideas, then hop on Discourse & read up on forums. I’m late to the Discourse party, and just joined today  That said, I’m encouraged by all the positive comments and this thread! Coworking in a small group with daily check ins has been a tremendous morale, confidence & productivity boost. I look forward to meeting more of the fastai family!
That said, I’m encouraged by all the positive comments and this thread! Coworking in a small group with daily check ins has been a tremendous morale, confidence & productivity boost. I look forward to meeting more of the fastai family!
11 Likes
@jeremy - also something to consider for fastbook!
Alexis’ sidebars are helpful, but all 3 perspectives are still all male. I’m a little nervous to admit this… but I was kinda hoping one of the commentators would be female, or another person who doesn’t come from a math/physics background.
I was excited about Alexis’s diverse zoologist background and was like, great - he’s like me! But then I saw he’s got a Math/Bio PhD + Physics degree… and the doubts about being successful in studying Deep Learning without a math or physics degree crept right back in.
Part of what inspired me to take this year’s class was the diverse examples of projects from the 2019 year’s lesson 1 video & the positive impact the projects had in the world. Maybe in fastbook add a 4th commentator, or a few more of the diverse project examples? That way you can give even more of us examples of who we hope to become. 

10 Likes
Hey, I am new to the community and I am thinking about doing a project while I do this course. I have been studying Deep Learning by myself and would love some feedback on my project idea. Could someone please take a look at this and tell me if it makes any sense?
Story Generation with long term coherence
Using large language models like GPT-2 has improved the state of the art for text generation and increased the overall interest in machine learning based text generation. We can use large transformers to generate stories or even use it to create a textual game like AIDungeon.
One weakness of this approach is the lack of long term context of the generated text. Since the context used to generate the next sentences is limited we tend to lose the coherence if the generated text is too long. A way to solve this context problem could be by creating architectures that can handle bigger context like the Compressive Transformer by Deepmind and the Reformer by Google.
For the story generation problem I think it’s possible to increase the long term coherence by using as input both the previous sentences and a updated world representation. In order to build this world representation we can extract Named Entities from text and create a vector containing all adjectives attributed to a Named Entity and previous Verbs both as object and subject. This world representation is updated for every new sentence generated and would maintain the order in which the adjectives and verbs appeared.
We can use as a corpus a combination of the project Gutenberg and scraping large Fanfiction sites.
For every book in the corpus we would split the text into N sequential sentences and parse the text in order to extract the Named Entities and the adjectives and verbs related to it and append it to the World Representation vectors. The final dataset would have a World Representation and N sentences as input and the next N sentences as output.
I am thinking about 2 possible ways to develop this project:
- Encode the world representation as text and put it together with the input sentence using some kind of separator. Fine tune GPT-2, BERT, etc on this data set.
- Create a Seq2Seq model with both sentence vector and world representation vector as input and the next sentence vector as output.
https://deepmind.com/blog/article/A_new_model_and_dataset_for_long-range_memory
https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
3 Likes
@edmar Great project idea, I’ve been thinking in similar directions - my first ML project was to generate nursery rhymes, and I was thinking of longer form story generation as well. The level of difficulty is probably more reflecting part 2, vs part 1 of this course, this does appear like a proper research topic, you may want to check out Mark Riedl’s papers on arxiv, e.g. https://arxiv.org/abs/1602.06484. Good luck, and please keep sharing progress or learnings as you go!
1 Like
For my project, I am building a Tennis Shot / Stroke Classifier. Basically, given an image of a tennis player in-action predict if it is one of the following shot types serve, backhand, forehand, smash. I created an initial dataset of ~500 images from Bing. Attached are some example images. Using resnet34 as the architecture I get an error rate of around 33%. The goal is to use Transfer Learning to improve on this. Other than using ImageNet / ImageNette data are there any other data you think might help in this problem ? I was thinking of human pose dataset. However, many of them (like COCO) are segmentation / localization datasets rather than classifying an entire image into one of the few classes. Are there other datasets that someone could suggest ? I did a little bit of research and found this human pose estimation dataset – http://human-pose.mpi-inf.mpg.de/ – as well as a larger Microsoft project https://github.com/microsoft/human-pose-estimation.pytorch. Any pointers re datasets / architectures especially related to transfer learning (e.g., can we use a model learnt in one sport to use in another sport) will be vey helpful. Also if anyone wishes to team up for this project – plz ping me!
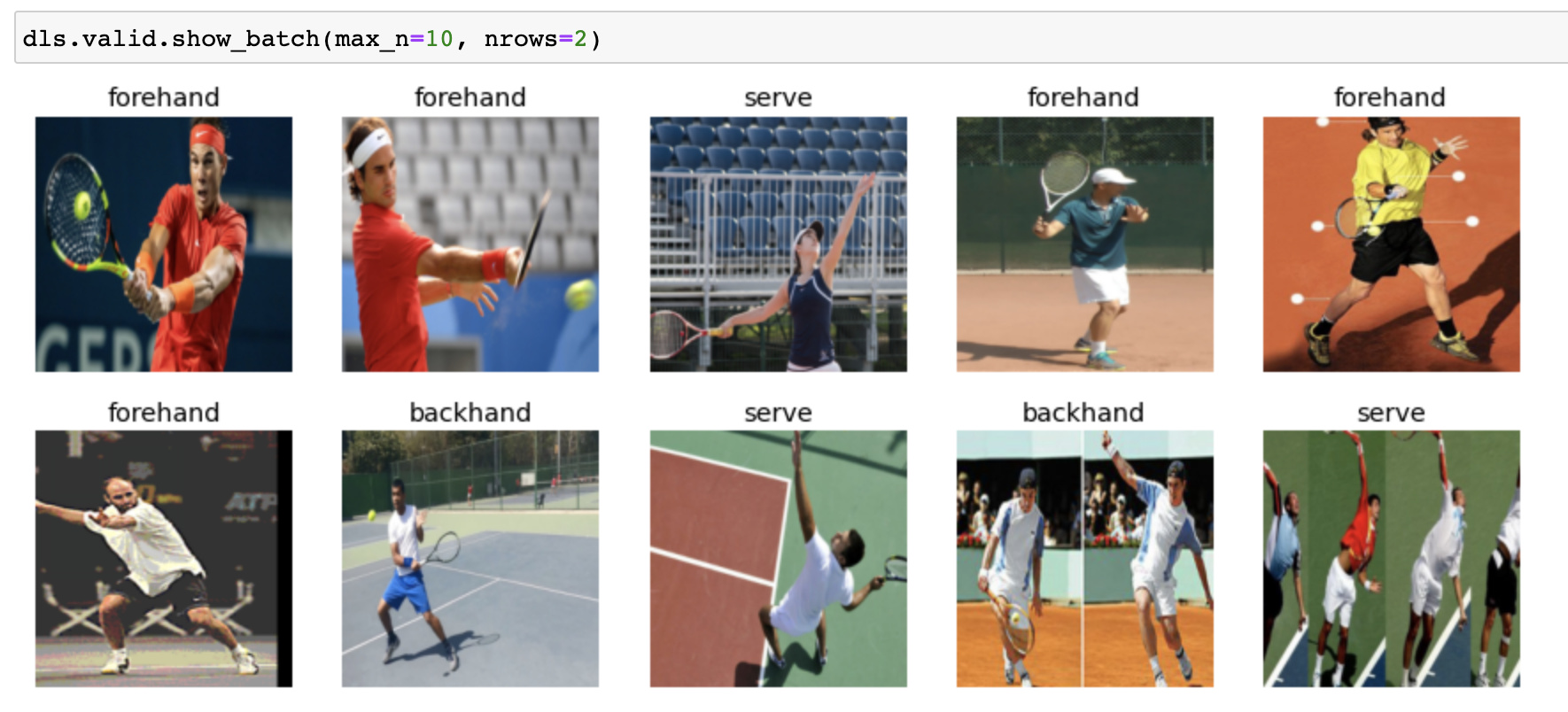
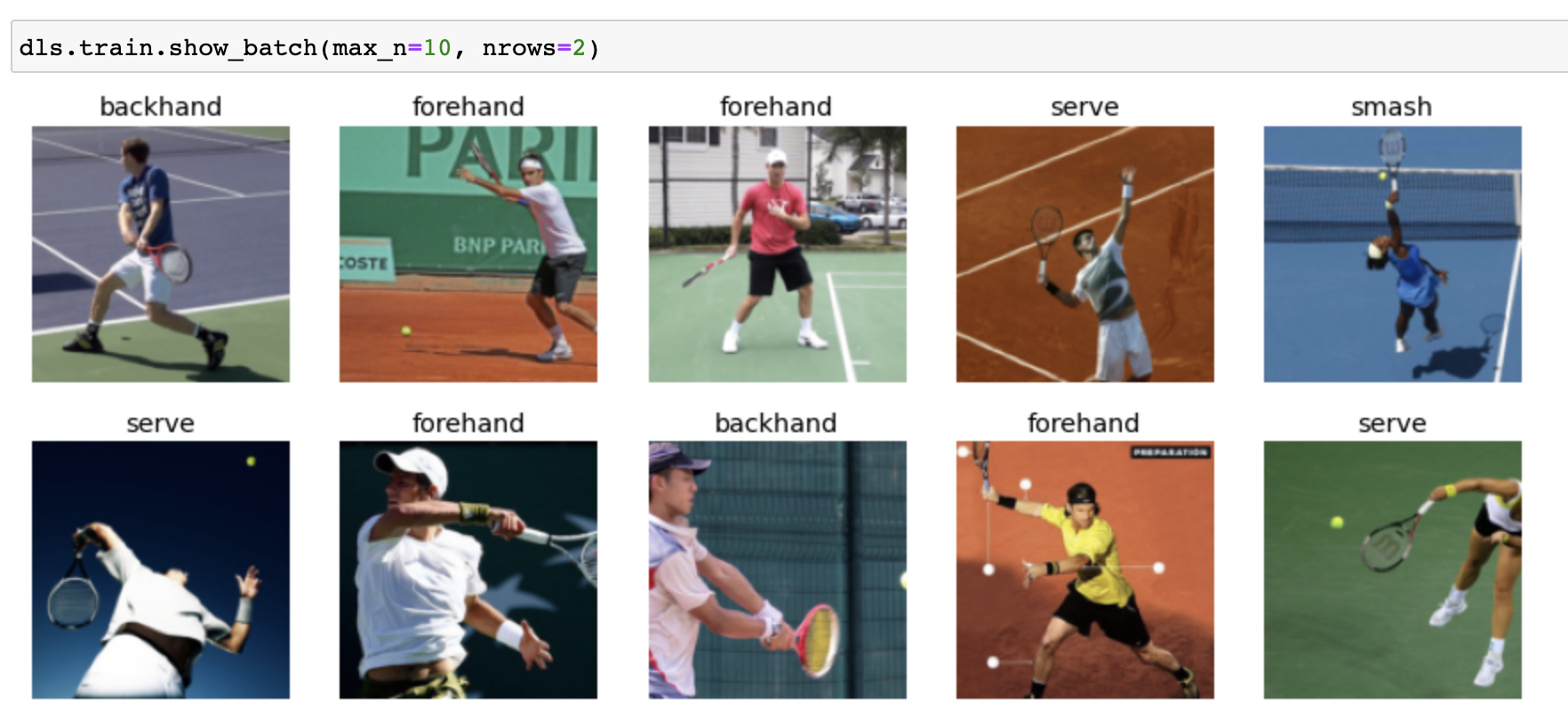
7 Likes

I wonder the same.
I believe that since we were having issues with keeping a host on all the time (as it had to bounce back in forth and if the chain was broken Jeremy had to be on to assign a new one) he shut it off for now?
Is there a regular study group meeting aside from the local ones?
I haven’t seen. Yet, I would like to see a more topic oriented study groups like NLP, Vision, etc. Some people might be doing that on the projects based groups.
What do you have in mind?
Maybe we can use ms teams it’ free. We here use it for edu… it’s also fine…
Any update on this ? It has been days that the Zoom room for projects has been inactive…
4 Likes
I’ve become increasingly interested in fully understanding what Zeiler and Fergus did in visualizing the hidden layers in a neural network. There’s some good information in this post from last year. In particular I’m interested to see if it’s possible to do this for NLP as well as image recognition (but just implementing it with current fastai tools for imagery would be a great start).
To me it seems critically important to understand the progression that the network is going through, at least inasmuch as as human beings can recognize and understand it, in order to arrive at an answer.
If anyone is interested in collaborating or contributing, please let me know!
Thanks,
David
Any update on the Zoom link? I tried joining for the first time in around a week today and saw the “meeting scheduled for…” referenced earlier in the thread. Is there another group other than the discord chat?
5 Likes
Hi, I am new to Deep Learning and I would love any feedback especially with the best way to convert my input into images that CNN would understand. Here is a description of my project:
Modeling DNA sequencing error
My project is in the field of bioinformatics. The main idea of the problem is to estimate sequencing error that results from sequencing machines.
Background:
The DNA sequence is a very long array of the characters A,C,G,T. The order of those characters is very well defined, thanks to the human genome project in 2000. That order is what differentiates a person from others with disease. When we take a sample from a person, we are interseted to know what the sequence at a specific location is. To do this, we extract the DNA from the sample, and run it through a sequencing machine. This sequencing machine basically spits out what each position is along the DNA.
Now, lets assume that the specific position we are interested in has the letter T, and the sequence around it is ACCGGTGTAAA. If the sequencing machine does not do any mistake when reading the DNA, it should output ACCGGTGTAAA. However, sometimes, the machine reads something wrong. So instead, it spits out, for example ACCGGAGTAAA. This is called error. And the probability of that error happening depends on the sequence content of its nearby positions.
For this reason, when we do sequencing, we not only ask the machine to read exactly one peice of DNA, but we extract thousands of that same piece and sequence them. The reason is that the probability that the machine will do that same error while reading at that same position in all of the thousands reads is low. However, again, depending on the sequence context, some reagions will have higher error rates than others.
Dataset:
I have a whole bunch of data from normal samples. I had identified the exact positions I am interested in and sequenced them.
Example:
Lets say we have one specific position, where the actual sequence is supposed to be ACCGGTGTAAA. After sequencing 10 times, those are the reads we got (* indicates the position we are interested in)
-----------*---------
ACCGGTGTAAA
ACCGGTGTAAA
ACCGGTGTAAA
ACCGGTGTAAA
ACCGGAGTAAA
ACCGGAGTAAA
ACCGGTGTAAA
ACCGGTGTAAA
ACCGGTGTAAA
ACCGGTGTAAA
In this case, we can say that the total depth is 10, and the error (reading an A instead of T at the target position) = 2/10. Lets call this last metric error rate.
Model:
I am solving a regression problem, where I am trying to predict the error rate, based on the sequence content. My input would be
- The sequence content of the expected sequence
- The total depth of that sequence (in previous example, 10; After all, getting 2 errors out of 10 reads is not the same as getting 4 errors out of 20 reads)
So my data looks like:
sequence--------------------depth ------- error rate (predicted label)
ACCGGTGTAAA ------- ----10 ------------- 0.2
CCGTCAGTTAA------------20-------------- 0.1
Initial Idea
My initial thoughts are to transform the sequence into an image using one hot encoding. So for the given example, the matrix would look like
A C C G G T G T A A A
A 1 0 0 0 0 0 0 0 1 1 1
C 0 1 1 0 0 0 0 0 0 0 0
G 0 0 1 1 0 1 0 0 0 0 0
T 0 0 0 0 0 1 0 1 0 0 0
Then I would transform this to an image/tensor, similar to what was shown in lesson 3 for the MNIST dataset. My questions now are:
- Does this sequence representation make sense? or is it the case that my sequence is just one vector and it is too overload to convert it to an image?
- How to pass the depth as a second feature or layer to CNN?
- What is the best architecture to start experimenting with? I am guessing resnet would not be suitable to this type of problem
Thank you for taking the time to read all this
3 Likes