i want to train resnet from scratch, not using pretrained weights.
how should i normalize images for resnet18 or 34/50 for images that are not from imagenet?
would normalize(imagenet_stats) work?
Whatever you use for normalizing your train data, use that one only for normalizing test set too. For example, say scalar is the normalizer based on the stats for train data. Use that only for test data
1 Like
You should. Just call data.normalize() and fastai library will take care of finding the stats and applying the normalization.
1 Like
Not sure using data.normalize() is always sufficient, I think it may depend a lot on the homogeneity of the dataset.
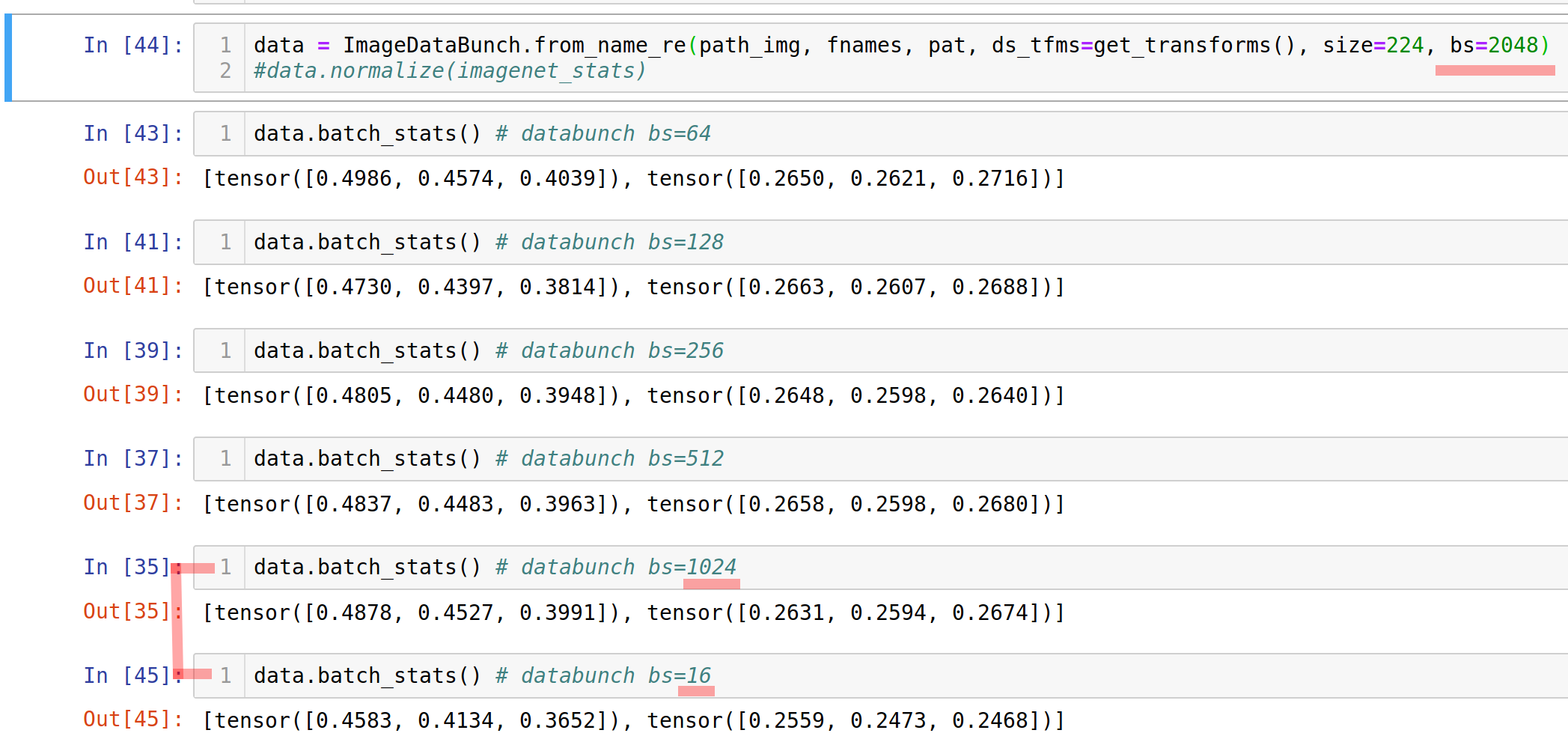
Calling data.normalize() without passing the respective stats means fastai will calculate it on ONE batch of data (using batch_stats internally, which you can also call directly). If you had to set your batchsize really small (like 16) due to your setup, this will not give you a good representation of the dataset at all. I have just run a little trial, see below, but one possibility (there are better ones, but this requires no coding  ) is to set the batch size really high just to calculate the stats. then save those and use them in the normalize method. That way you can calculate the mean/std at least on a larger batch of a size you could never use for training and then set the size back to training size and run the model.
) is to set the batch size really high just to calculate the stats. then save those and use them in the normalize method. That way you can calculate the mean/std at least on a larger batch of a size you could never use for training and then set the size back to training size and run the model.
That being said I have no idea how crucial it is to get the mean/std about right or if it is sufficient to have it in somewhat an “okay” range. Maybe someone can answer that?
2 Likes
It is not crucial that they are exactly right, having a good approximation is fine. However, the method you propose is a good one if you want to be really precise in you calculations 
2 Likes
I guess the sample size used to calculate the mean,std should be some multiple of the number of classes and should include samples of all classes.
Since normalization is meant to speed up convergence, approximates should be good enough; I think precise numbers may not be essential
2 Likes
If you use your own stats, is it still ok to use pretrained model if the images are very different than imageNet? Or you have to train your model from scratch?
If you’re using a pretrained model you need to use the same stats it was trained with.
3 Likes
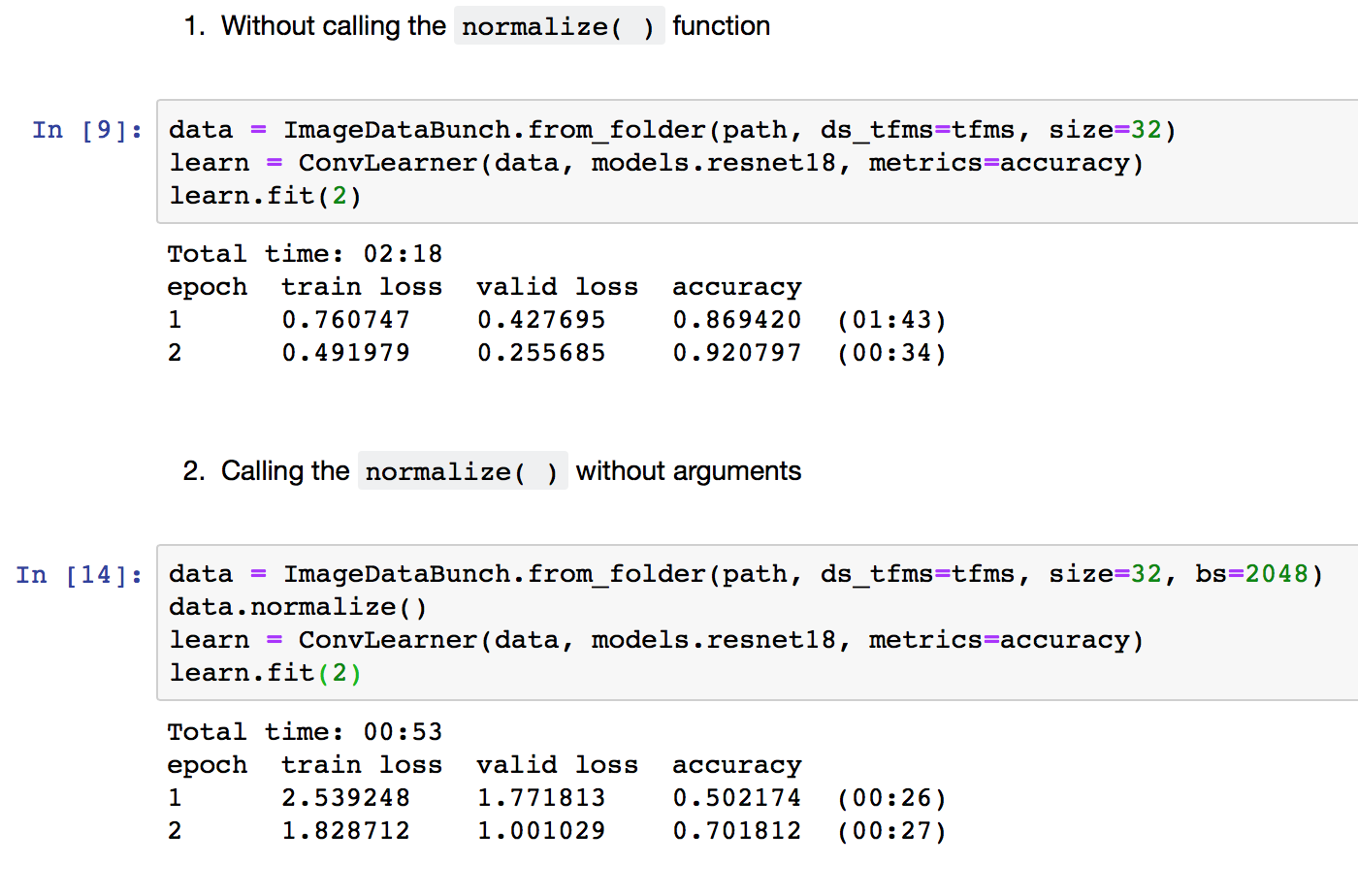
Interesting discussion. I tried to run my code on a dataset similar to MNIST with 4 variations.
- Without calling
normalize() - With no argument to
normalize() - With imagenet_stats to
normalize() - With mnist_stats to
normalize()
Trained 2 epochs on reset18 and found almost no difference in results other than the option 2. How should I interpret it? Would the different become noticeable after more epochs?

1 Like
Interesting. You can look at the values used by data.normalize() without params by looking at data.norm (without brackets, so not calling the func but looking at it). It will show you the params (tensors for mean, std) generated by the normalize method. They must be very different from the rest ?!
1 Like
The issue with (2) is your enormous batch size.
1 Like
Jeremy was right. I removed the big bs and found the same accuracy. Now my question is why am I getting similar results (even for time taken) with 4 different variations? Then, why we need the same stats the model was trained with?
I checked the data.norm as suggested by Marc,
mean=[0.2059, 0.2059, 0.2059], std=[0.3668, 0.3668, 0.3668]
which is different than imagenet_stats
([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
and the mnist_stats.
([0.15, 0.15, 0.15], [0.15, 0.15, 0.15])
I would think that the larger batch size the better for accuracy (and speed). but this experiment show otherwise (in terms of accuracy, at least for first epochs). interesting…
@Jeremy I bet you have a good reason to say that. But isn’t it that, normalized dataset with its own stats will have roughly the same distribution like imageNet?
The only thing I can think of, which may differ is skewness:
Is it the possibility of skewness or something else the reason of your statement?
And does that mean you don’t recommend using pretrained model with very different dataset like the one-point mutation that you showed us in lesson 2?
or it is okay to use pretrained model for Genomics images, but we should use imageNet stats? However if it is yes, then the dataset will not be normalized well!
Larger batch size helps for parallelizing with GPU. But you would be doing fewer gradient updates. The two pull indifferent directions. In general you should be looking at keeping your GPU fully occupied.
Also, keeping the batch size small is thought to have have a regularizing affect, which helps your model generalize better, that is a lower validation loss. But if you have a batch normalization layer, keeping batches very small negatively impact the convergence.
3 Likes
Jeremy was kind to reply my question in-class after getting 13 votes. And I am copying the answer from @hiromi 's lesson 3 notes :
For a dataset very different than imageNet like the satellite images or genomic images mutation points shown in lesson 2, we should use our own stats.
Jeremy once said in the forum:
If you’re using a pretrained model you need to use the same stats it was trained with.
Why it is that? Isn’t it that, normalized dataset with its own stats will have roughly the same distribution like imageNet?
1:46:53]
Jeremy :
Nope. As you can see, I’ve used pre-trained models for all of those things. Every time I’ve used an ImageNet pre-trained model, I’ve used ImageNet stats. Why is that? Because that model was trained with those stats.
For example, imagine you’re trying to classify different types of green frogs. If you were to use your own per-channel means from your dataset, you would end up converting them to a mean of zero, a standard deviation of one for each of your red, green, and blue channels. Which means they don’t look like green frogs anymore. They now look like grey frogs. But ImageNet expects frogs to be green. So you need to normalize with the same stats that the ImageNet training people normalized with. Otherwise the unique characteristics of your dataset won’t appear anymore﹣you’ve actually normalized them out in terms of the per-channel statistics. So you should always use the same stats that the model was trained with.
3 Likes
I have a question, if you do not use pretrained, according to the source code of fastai, it uses mean and standard deviation of the dataset to normalize, but the results are just good, how to explain this