Hello all,
I’ve recently finished the 2020 course and have set out to put together a project to cement my learnings. My goal for this project is to output recommendations for emojis to “Emojify” text written by users, see example below.
+-------+-------------------------------+----------+
| Index | text | label |
+-------+-------------------------------+----------+
| 1 | Wow, I love taco tuesday! | 🌮, 🇲🇽 |
+-------+-------------------------------+----------+
| 2 | I had a horrible day at work. | 😢, 😡, 👩💻 |
+-------+-------------------------------+----------+
Currently, I am having issues in framing the problem. I’ve been following the ULMFiT example in the fastai docs but all my results thus far have been unimpressive.
In order to accomplish this task, I am scraping data from Twitter. I have a sizable dataset (1M Tweets containing emoji) with reasonable class-balanced.
I have some limited experience working on NLP problems so before I jump into my code I’d like to ask the forum what their strategy would be in framing a problem like this? Thus far I’ve tried the following approaches:
- Treat this like a
MultiCategoryproblem (Potentially many labels per observation).
To do this I loosely followed the multicast notebook covered in the course, Combining the ULMFiT method with the
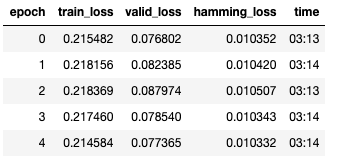
MultiCategoryBlock. Doing this yielded very high multi-accuracy. The issue with this was the model was very conservative in its output. All predictions were generated with incredibly low confidence. Feeding text like the example I provided above would never result in a prediction even with low (20%) multi-accuracy thresholds.
- Treat this like a
Non-Multi Categoryproblem.
After failing to produce confident predictions using the
MultiCategorymethod I’ve simplified my training data to only include one emoji per observation. The issue here is that I feel this is a loose-fit for my problem. Even with my reasonably large dataset, I’m only producing 5% accuracy. Does anyone else have a recommendation for the metric I should be using to evaluate this model? It seems that emoji recommendation is sort of inherently MultiLabel output or maybe I’m missing something?
- Treat this like an
NLP Domain-specificproblem.
Since I have little experience with NLP I wouldn’t be surprised if I’m scoping this problem in the wrong way. I’ve done some basic research into more advanced NLP tools and am aware of the fastai NLP course. Does this type of problem require a more specific toolset that I am lacking entirely? I plan on taking the NLP course eventually but I am not sure if it is critical to producing decent results at a problem like this.
Any thoughts from anyone with more experience with problems like this would be greatly appreciated. I am using this project as a way to continue my learning so I apologize if my thoughts are messy.
Thank you