Hi there!
I have a rather small dataset of ~3500 images of t-shirts, each labelled with 4-5 different features (blue color, long sleeve, patch pocket, etc).
While some features are common, others aren’t – there are around 3000 labels that can be predicted from. I am assuming this is the issue behind my poor performance, but I don’t have an intuitive sense for how this is affecting the behavior. Any ideas?
I’m attempting to train a multilabel classification model using lesson 3’s planets method, pretty much exactly as Jeremy did. But I’m getting some results I don’t understand:
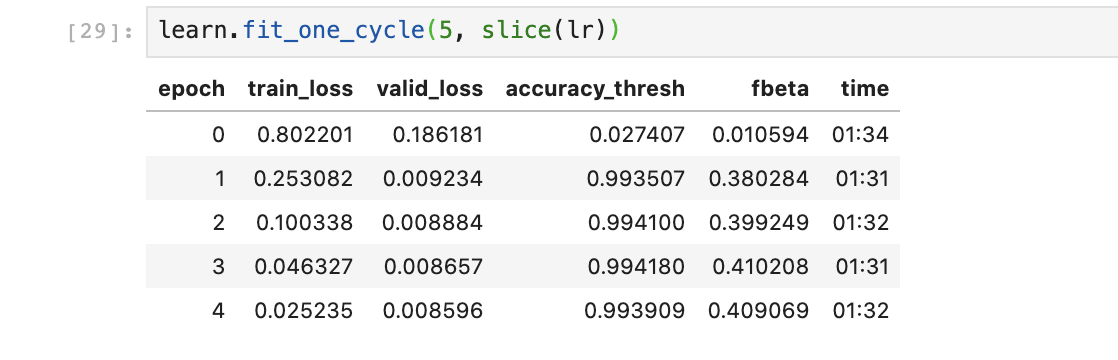
The model gets extremely high accuracy very quickly, and the validation loss is way lower than the training loss! Shouldn’t valid be higher than train?
I do see decent results when I train through and run it on a test set, but the model generalises very poorly.
I’m not sure if I’m simply overfitting, or if this is because of the high number of labels I’m trying to work with.
What would be the best way to add regularisation to a multilabel classification model like this?
Thanks very much for any help!
Britton