You’ll need to pretrain a Spanish ULMFiT model (is there one that people can download @piotr.czapla@sebastianruder ?) Then fine-tune the LM in the usual way - although better still would be to first fine-tune the LM first on a larger set of Spanish tweets downloaded using the twitter API. Then finally fine-tune that for humor classification using the provided dataset.
Looks like winners get to present a paper showing their approach
I"m planning to give it a try once we fix the ULMFiT in fastai v1.0, I can’t get the version that works with ulmfit-multilingual to go above 0.06 error rate on IMDB, and our winning version was using Fastai 0.7 (with a few modifications that @mkardas did for German hate speech detection). I plan to fix that during ablation studies, although I would appreciate help the paper deadline is close (May 11th).
To form a baseline, you need to run the code a few times as unfortunately, the classifier easily overfits and has different results depending on run/weight init.
All of tar.gzs contains the .json files with all the hyper parameters that are needed to load the models.
If you add the competition to ulmfit-multlingual as a dataset similar to imdb we can train and experiment with different models, and I will try to move our code from fastai 0.7 to that repository, so any work you do will benefit from the fix once we figure out what is causing the current ulmfit-multilingual to perform worse.
Awesome. I just got my acceptance so I’m going to give it a shot. I’m going to try (time permitting) to do ULMFiT and BERT to see how they both perform. Definitely complicates it for me that they are in spanish, but once I get past that hurdle, ULMFiT vs BERT shouldn’t really matter from a technical perspective.
Kevin, how can I help you out with this? I should have time this week to work on it. I’m not a Spanish speaker so can’t help on that part! I can run code for you or update to v1.0 in whatever model you want to run
Updating to v1 is what I’m going to focus on. I would say start there. ULMFiT is my focus but once that is working I’m going to try implementing BERT on fastai v1. Lots of work there, pick whatever sounds interesting to you!
So I have a little repo that does what I think of as ULMFiT for english. Going from raw Wiki103 articles to IMDB classifier with 94% accuracy. All using v1. Is that what you are looking for or is there something else about ULMFiT that is needed? We could easily swap in the weights from @piotr.czapla rather than learn from scratch. Should I try to do that?
FWIW on this I am going to try to pull down a larger Twitter (spanish) data set for LM modeling (or fine-tuning) Script is pretty simple if you have Tweepy installed and have an “authorized” account (just a matter of requesting it.) Code is below if it helps anyone else out. the text file will only be good for LM training (single column with just the full tweet text in it)
import tweepy
from config_twitter import Config_Twitter
import json
import os
from ipdb import set_trace
#config params
my_config = Config_Twitter()
consumer_key = my_config.CONSUMER_KEY
consumer_secret = my_config.CONSUMER_SECRET
access_token = my_config.ACCESS_TOKEN
access_token_secret = my_config.ACCESS_TOKEN_SECRET
auth = tweepy.OAuthHandler(consumer_key,consumer_secret)
auth.set_access_token(access_token,access_token_secret)
class StdOutListener(tweepy.streaming.StreamListener):
def __init__(self,out_fn):
self.fhOut = open(out_fn,'a')
self.fhOut.write("tweet_text" + os.linesep)
super().__init__()
#This function gets called every time a new tweet is received on the stream
def on_data(self, data):
j=json.loads(data)
try:
if 'extended_tweet' in j.keys():
text = j['extended_tweet']['full_text']
print(text)
self.fhOut.write('"' + text + '"' + os.linesep)
except KeyError:
pass
def on_error(self, status):
print("ERROR")
print(status)
try:
l = StdOutListener('out_file.txt')
stream = tweepy.Stream(auth,l)
stream.filter(languages=["es"],track=['el','su','lo','y','en'])
except KeyboardInterrupt:
pass
I have a simple first attempt at this. I am getting about 82% accuracy. Anyone know what the Naive Bayes accuracy would be?
I am getting a lot of xxunk using Spacy. I think I can improve by quite a bit, but want to know SOTA on this data if anyone has it at hand. I can’t find in the twitter link above.
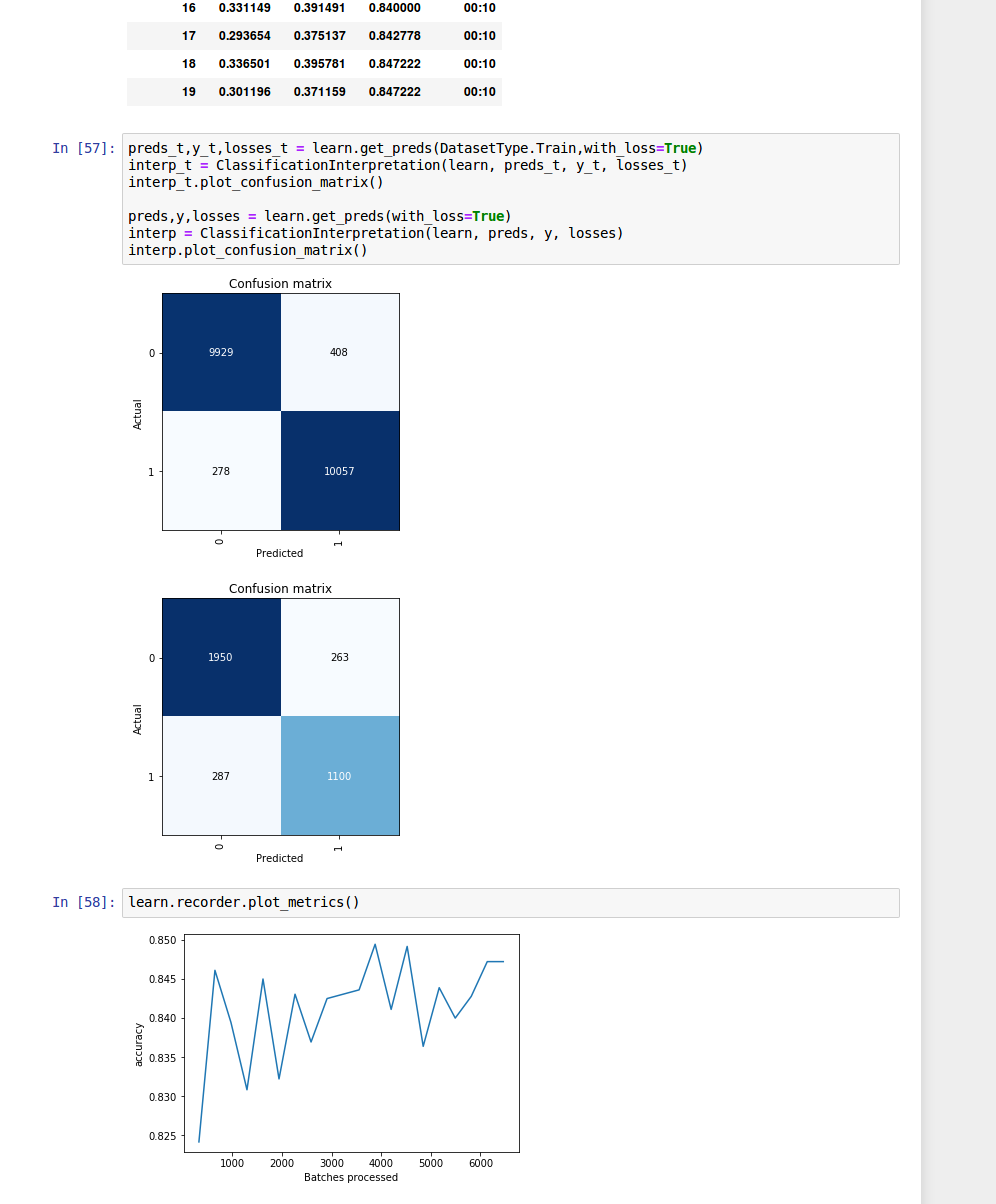
With a little more work, I get to 84.7% pretty solidly. (F1-score of 0.8 - again, how does that compare to the simple Naive Bayes baseline? I have no idea.)
Confusion matrix looks ok, less xxunk from spacy by updating to the “tweet vocab.” I don’t speak spanish, but here are some of the top error tweets as well (second image below.) Going to sentencepiece will increase coverage and remove/reduce the xxunk to nearly zero. That should not be difficult to build out, so I will try that out next (because it is easy!) After that, going to attention based models is probably sensible. Either with BERT for embeddings or TransformerXL (although the text is not very long…)
I am running my Tweet collector for a while longer today. currently have 100k tweets, but they are all small amounts of text, so that is not really very much data. I think with a large enough tweet corpus, we could just train on that from scratch. Any thoughts there? I am open to ideas about what to try out next.
I will clean up the code and put in a repo and then add the link here. That will take a small bit of time, but I will do it so others can replicate results and move forward.
We haven’t had much luck with classification using attention models yet FYI. ULMFiT is still giving us the best performance, and is also winning competitions for @piotr.czapla. If you’re able to get better perf with BERT et al then let us know!
BTW @313V do you know what the naive bayes baseline is?
I am working on SP now. Should have results soon on that. More Twitter data will also help.
I found the results from last year for the challenge. If this train/validation split is similar to what we would see in test, than this first pass with SpaCy would be top or nearly top in the competition.
I have not taken the time to put this code into a repo. Sorry about that delay, but I will get it out for the community very soon. I want others to help me improve it or take it and do better on their own
Two changes that seem to have a positive effect.
I pulled yet more tweets in Spanish. Got about 475k now. Using that to train-from-scratch rather than use Wiki103-es. It seemed to me that there are a lot of chars that are used that don’t seem to turn up in the Wiki tokens that are common in Twitter. In particular Emoji.
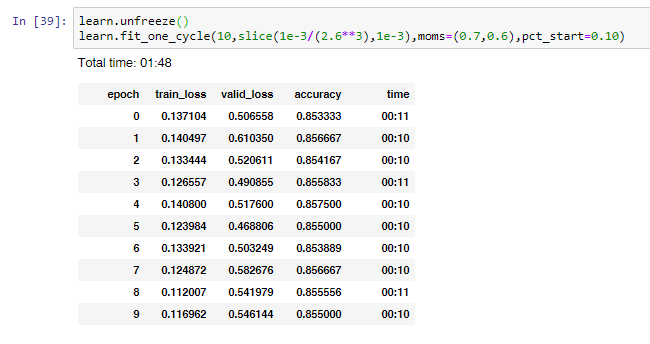
I moved over to sentence piece and trained about 2.5 hours, got something with 33% accuracy and have run with that. It was not topped out and I suspect I can get a better LM by training that more with the tweets I have.
Anyway, I am solidly into 85.5% now. That is better than bag of words, but not by enough. I think we can do better. I think that an ensemble with several kinds of tokenizer settings could really help here, but that is going to push it by 1-2% more.
What will bump this by 5% more to over 90%? That is what I want to try and eek out. Still thinking more data will help, so collecting that. But maybe a different/bigger model? Maybe time to try a Transformer? I am open to ideas from anyone else.
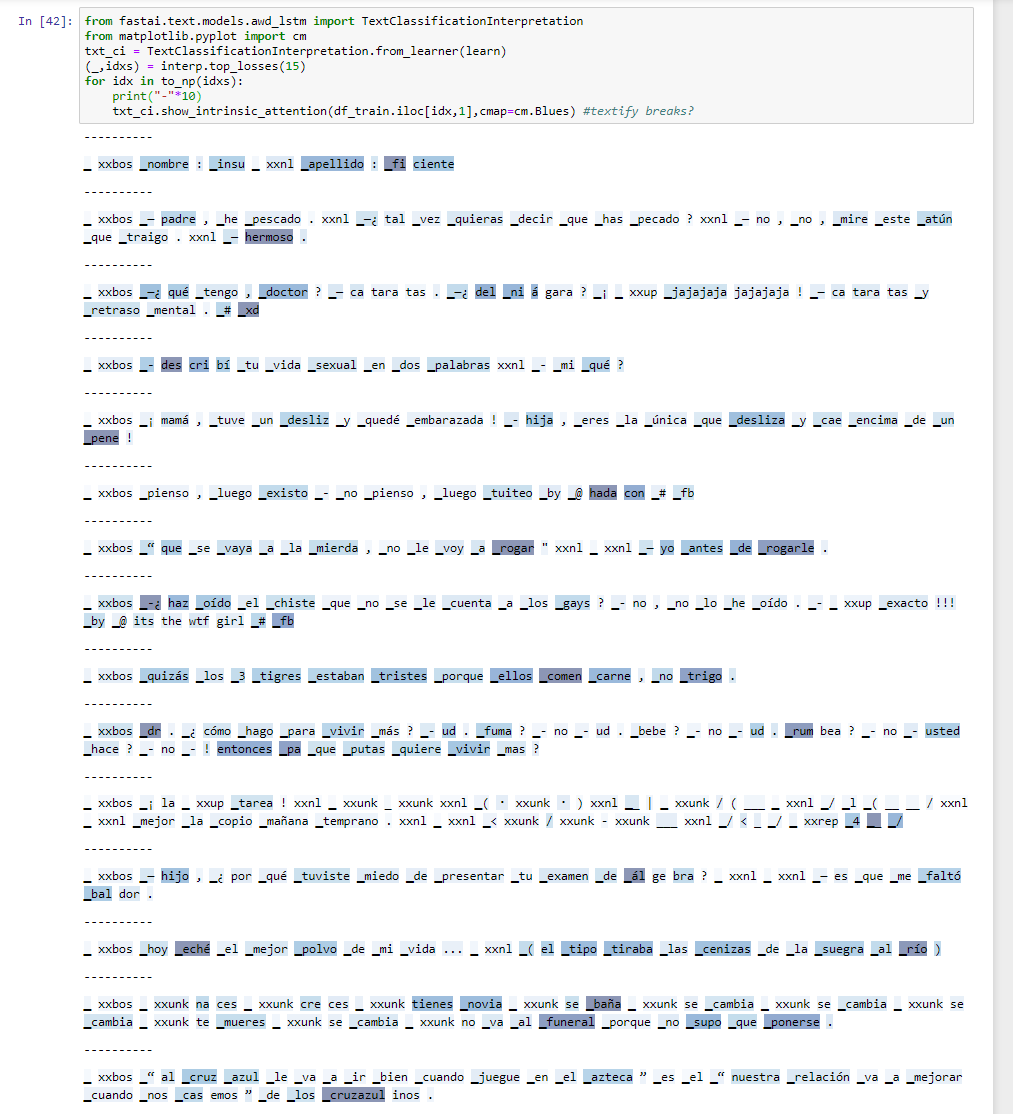
Some error interpretation. Any assistance from a Spanish speaker. These all seem to key off of a particular word or few words. I don’t know if that makes sense in this context.
I am using Tweepy with the short script above that dumps to a file. (I could expand the track list and then get even more text.) Then reading in the file and tokenizing in the usual ways. You have to register with Twitter to get it working (private key, etc) but that is free and easy enough to do.
I do think this is a bit of a different challenge in that each text is so short. Attention might work better (or worse!) I will find out and report back here.