It might also be worth trying my strong linear baseline: https://www.kaggle.com/jhoward/nb-svm-strong-linear-baseline .
5 Likes
It is reasonable. It colors the word that makes the phrase a joke, most of the time.
I found a large dataset of spanish text here:
http://opus.nlpl.eu/DOGC.php
It is a catalan-spanish dataset.
1 Like
This NBSVM baseline comes up with 83.9% accuracy (lifted the code and ran with my same validation split) With that reference point, 85.5% is better, but not “better enough” for me!
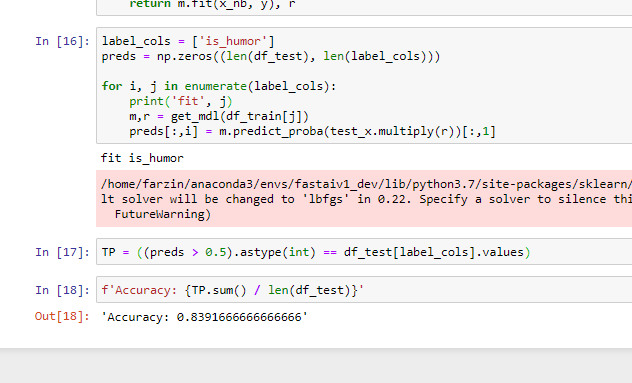
I seem to get better results with RNN than QRNN (and the accuracy of the LM is better with RNN) @piotr.czapla do you see that in your multilingual models as well?
It does not seem that there are a lot of xxunk coming up. Frequency of unknown tokens is about 2% on the joke text and about 5% on the training corpus.
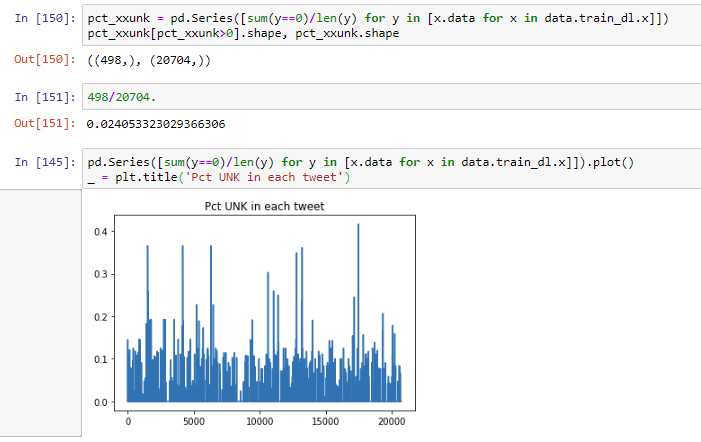
I am going to venture into Transformer to see what the produces ( hoping for a better LM which should lead to a better classifier.)
I have also toyed with the idea of an attention head on top of the model rather than the PooledLinearClassifer The idea being that Last, Average and Max are arbitrary ways to summarize the text and an attention head would allow the model to find the best way to use the output states at each point in the sequence. Any thoughts on that idea appreciated.
Now I’m curious to know what the naive bayes approach that gets 84.7% is!.. @313V ?
(Maybe it’s just a different validation set).
1 Like
Here is a Gist with the full code. I can get a few different values between 83.4% and 83.9% depending on how I split my data. Maybe they are using a prior years test data?
1 Like
I got a Transformer (not XL, regular) to train as my LM and then used as my Encoder for my sentiment analysis. Overall getting about 85% on my validation (similar to what I got with RNN model. There is some ability to get better values with an ensemble of the two models boosting the result to 85.6% or so.
I have not yet tested a “backward” version of either one, that will boost by a little bit also. Maybe to 86%??
I also think I can set config['mask'] = False for the Transformer that is doing sentiment analysis (it can look at the whole text, not just the history to generate the encoder state.)
I setup a Github repo with my progress so far. Right now has the baseline and the RNN model. I have notebooks for the QRNN model encoder and Transformer encoder and will add those as well so three possible (forward) models. Running all three backwards should help with an ensemble.
Any/all contributions welcome!
3 Likes
hey, - sorry off topic. My colab notebook crashes as I try to create databunch with sentencePiece, citing no more space in RAM. What cloud service are you using to create databunch? I have only 60k files, and still it is crashing.
Curious - can we create a databunch iteratively, using chunks of data at a time. I tried playing with batch size, with no success. Any tips?
I am running on a local box. I don’t think/see how a Colab notebook would have any problem. More details and I could answer/look into it.
Not sure what you mean by iterative data bunch building. Are you trying to keep down RAM usage? If so, have a look here about what we are working on to make RAM usage better for tokenization.
2 Likes
I added more files to that repo today, but still cannot seem to crack 85% accuracy (or not by much…) in validation set. Maybe my expectations are far too high for what could be done. I had thought we could get well over 90% accuracy.
I have used both RNN, QRNN and Transformer language models. All get me in the 35% accuracy for the LM predict-next-word.
Here are my next ideas:
- Current SP vocab is 60k. Seems others have used 15k, I can try that. It could be that with sub-word units you don’t need as much scale to model the tokens.
- LabelSmoothing - seems like it should work for both the LM and the Classifier
- Some kind of TTA with text that could boost performance?
Any ideas welcome.
[UPDATE]
Label smoothing on the classifier alone has gotten me into high 85% and touching 86%. With some LR fine-tuning, might get that solidly over 86. Also running a new LM with Label smoothing to see if that is better.
1 Like
I was earlier creating a databunch using folders - 300MB data was giving OOM on ~11GB colab RAM. I now switched to your method of creating it via df. So it is resolved now.
Next question - how are you playing with the hyper parameters? I read about this bayesian optimisation approach a while ago, are you using that?
They are comparably or slightly worse but they train faster, and i don’t think anyone really tuned hyper params for qrnns, so I would keep that as an option.
Yeah label smoothing works really well. You can think about using one cycle for the classifier training with unfreezed model from the start it was working better for us on MLDoc than gradually unfreezing.
60k seems better if you aren’t using sentence piece, if you are using sentece piece try 15k or 25k they train faster and you may get better results.
@mkardas tried that for few data augmentation techniques and it wasn’t working well.
On the other hand what looks really promissing is mixmatch (vision that could be adopted to NLP [1905.02249] MixMatch: A Holistic Approach to Semi-Supervised Learning) and UDA already works with NLP augmentation [1904.12848] Unsupervised Data Augmentation for Consistency Training .
I’m trying to get some guys that are learning fastai to implement mixmatch and we could think about getting UDA implemented.
Another idea that is worth exploring is keeping the lmseed weights fixed and looking for a right seed as a hyper parameter. It gave us promising results on Poleval. Ot let’s you stay sane when you experiment with text classification as the results differ a lot quite often and you never know if that was due to change or due to different random seed. Fixing random seed lets you reason about that.
We have fixed random seeds implemented and tested in the ulmfit-multlingual/reproducingpoleval branch. Here is the poleval paper it talks more about the issue of the weights initialization. poleval2019.pdf (156.8 KB)
And after ablation studies on poleval the most important bits was to use proper corpus for pretraining, with reddit we got way better results than with wikipedia. What corpus do you use for training, can you share it privately (forum priv / twitter)?
2 Likes
So far all by hand, nothing baysian. Using the IMDB fit as a guidline, but making changes from there as I see things that might not make sense.
Thanks for the notes, I will try that out with the random seed as a hyperparam.
UDA seems promising, I need to re-read it more carefully. And thanks for your other notes - all very helpful for me to pursue further.
Has there been a replication of the UDA paper for IMDB in Fastai? Maybe that is the best place to start with understanding UDA.
I found this applied in this case as well and I am exploring it.
Also exploring all the UDA stuff. The back-translation seems “hard” in terms of having to setup a lot of machinery. I am going to start with dropping words either by low-prob of next word or at random and/or swapping the “next likely” word from the with some prob. These seem more tractable, but I am unsure if they will change the meaning of the sentence too much and cause more problems than they will fix. I will start with IMDB and see how it helps (or hurts) that since it will leverage to the rest of the community.
Thanks again for the notes.
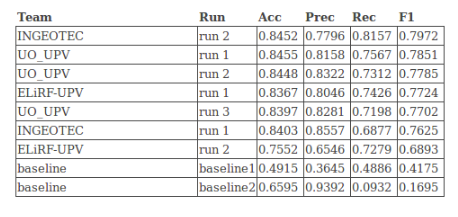
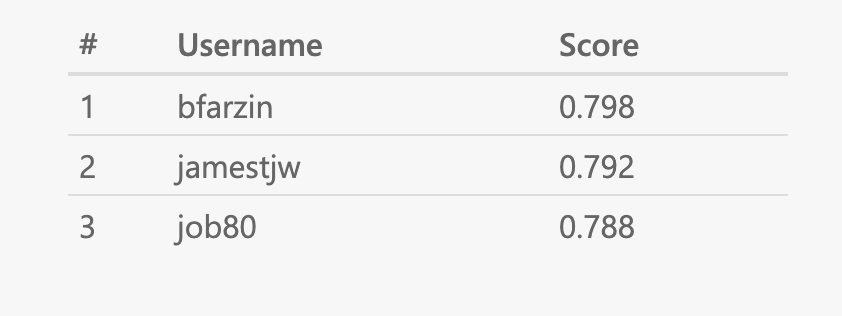
The test data is not yet out for a leader board. However, I had a run of my current pipeline with the 2018 data and the 2018 test data. I did not change any params in the pipeline, just ran my sentiment classifier end-to-end with the same LRs, etc. and got the outputs.
Accuracy is 86.9% and F1score: 82.005 The leader board from last year is below. As suspected, LM pre-training + classification is promising.
[UPDATE]
I tried your idea of fixing the LM seed and seeing how the different classifers fit in terms of accuracy. I don’t see as much difference as you do in your Poleval model. I trained for 1 epoch on the LM, then did 100 different random seeds on the classifers. I am using this code to set the seed for the LM with a fixed value and then passing None to allow it to pick a new seed on each pass of the classifier. Once I graph the outputs, I get this (vertical lines are the means of each seed-group):
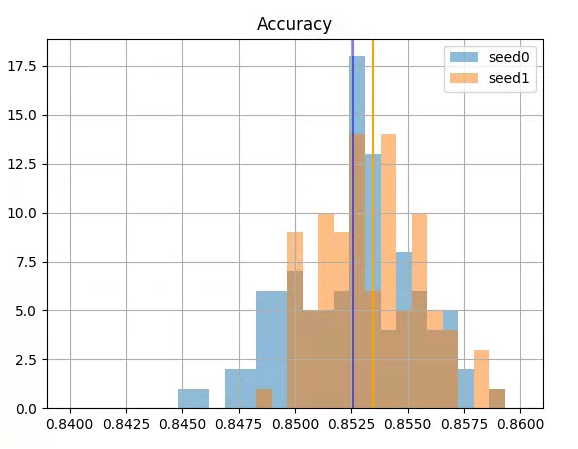
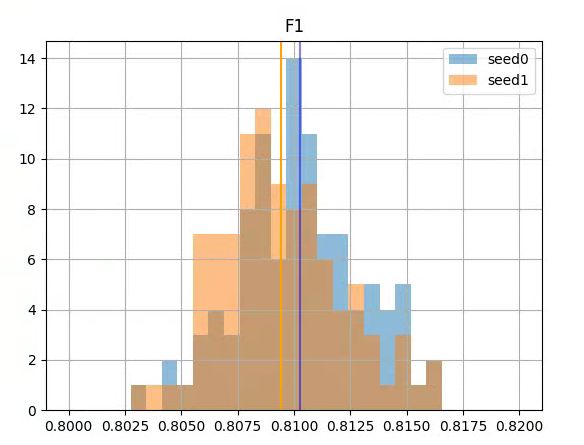
However, this does lead me to think I could improve by ensembling the outputs of the 100 models. That gives the best chance to get the F1 at the mean of the outputs. (rather than a single model)
Maybe I need to just try more potential seeds for the LM? Or run that for more epochs? or just in my case it has less effect?
2 Likes
We had small dataset so maybe that was causing the issue. I was trying this on MLDoc and I haven’t noticed a huge differences either I will play with that a bit more later.
You results looks really promising. What data have you used for pretraining?
Yeah, seems to be doing well.
I run this script with tweepy to dump the tweet text into a file. Over a 8 (?) hours I got 475k tweets. Which seemed like enough. I could always get more…
I like this back-translation idea to augment the data for the classifier. I had a thought that you could probably go from one tokenizer scheme to another and never change the language and get the same effect. I am going to first try seq2seq with spanish-english. but then, once that is working, update with Sentencepiece to Spacy and back. See how that does to generate new (but similar) sentences. It should be able to reproduce the original data, but maybe in the process it makes some small “errors” that are useful for augmentation.
[UPDATE]
Averaging across 199 models moved the F1 from 0.79 (single first model) to 0.798.
1 Like
This looks really nice, but the competing model is close, I hope they already tried their ensembles.
How is the work on uda going? Btw the idea with switching the tokenisation is good one. Sentencepice has this implemented it is called subword tokenisation. It might be worth trying it out.
It is close! I am curious what the others are doing. I hope I can learn from them after the competition is over!
UDA is going slowly. Getting a Transformer to work (and understand seq2seq with that) was harder than I thought it would be. I am just at the point where I might have something that goes one-way well enough to try out for augmentation.
Meanwhile, I have been trying to get my code cleaned up so I could write up my results quickly if I do come in first. In that process, I realized that all my results so far are with a single training epoch of my LM. I did that so that I could see what effect the random seeds would have on the classifier. But that is likely far from optimal.
Current plan is to run:
- Many epochs for the LM training (25 seems to plateau on my tests in the past)
- Then re-run the 200 models for the ensemble.
- Also re-run for backwards tokens (just reverse the order for both the LM and then for the Classifier
- And, also, run with different tokenizations.
In code-ish format
for tok_model in [unigram,bpe]:
for backwards in [True,False]:
build_tok(tok_model,backwards)
for LM_seed in [0,1]:
train_lm(LM_seed)
for class_seed in range(100):
fit_clas(class_seed)
That is going to be a lot of models! but should give the best shot at a good averaging of outputs. My prior expectation is that we get the biggest boost from the better LM, but maybe the forward/backward tokenization will help more. I will find out soon enough!
[UPDATE]
I got a forward and backward model. Backward model seems quite a bit worse than forward model, so unsure if combining them will be worth it.
I did two things are the same time, and will need to do an ablation study to understand the impact of them independently. @piotr.czapla you might be interested in this:
- Select on best F1 (that is the metric for the compeition) rather than Accuracy during the training loop using the
SaveModelCallback - Rather than average all the models, pick the top quartile of models in the validation set. That is, use the information coming from the various random seeds to get the model that will most likely perform near the top end of the distribution. My thought is that this has the most effect, but I have not been able to test that yet. Here is a graph showing that. I am taking the models to the right of the solid line and then using that for my ensemble:
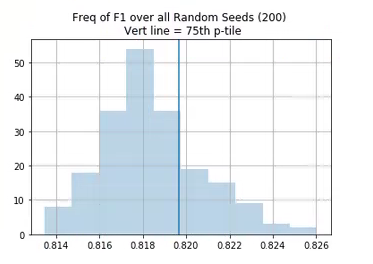
1 Like
There’s a backwards param that will do this for you for both the LM and classifier BTW.
1 Like