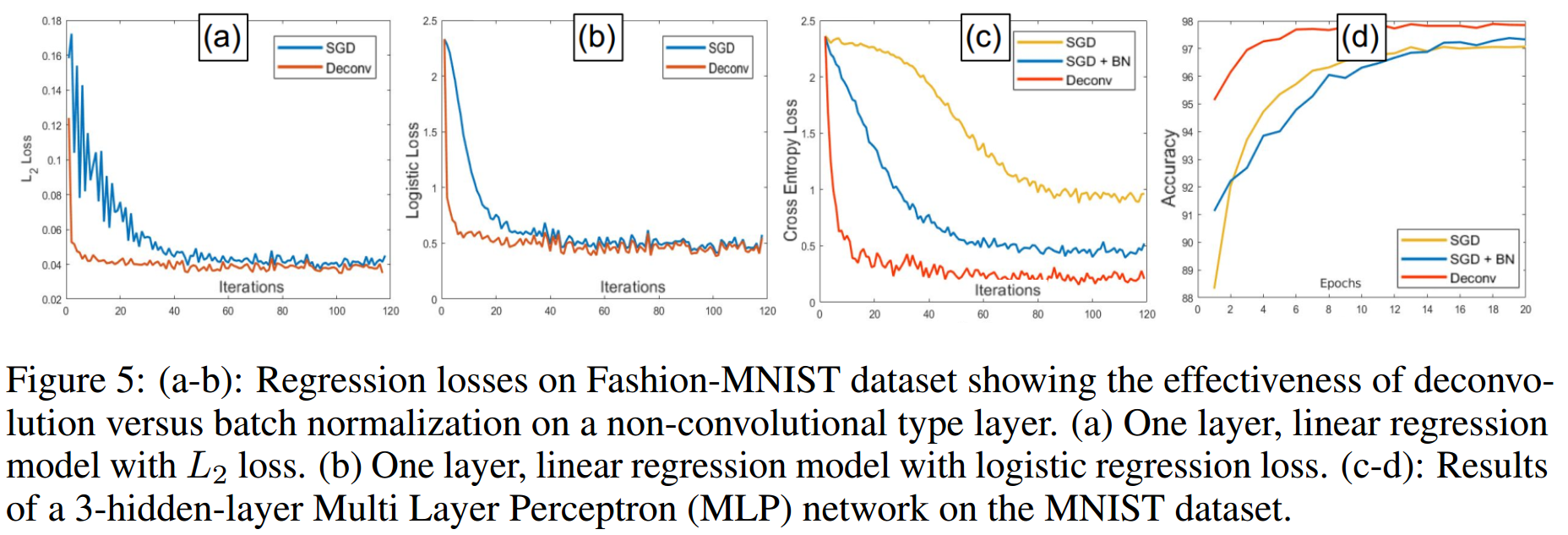
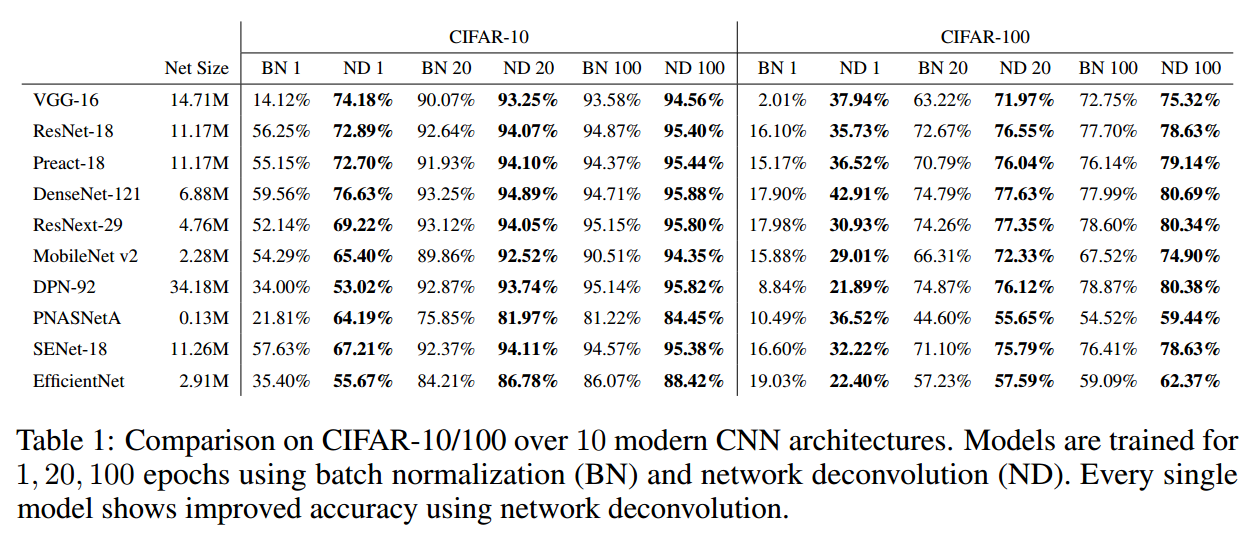
I recently read the ICLR paper on network deconvolutions (Ye et al. 2020) (not to be confused with “deconvolutional” neural networks which actually use transposed convolutions; e.g., Zeiler et al. 2010). The upshot of these deconvolutions is that they remove correlations between pixels and channels, which allow for a more sparse/efficient representation of features via convolutional layers. There’s also a bit of biological intuition for why this might be useful. The authors demonstrate empirically that deconvolutions speed up training and give better results overall:
Anyway, the authors discuss approximate computation of the deconvolution matrix, and have extended some Pytorch models using this implementation in their Github repo. If I have time later this week, I may try some experiments. But I figured others may be interested in having a look, and perhaps try using them for the Imagenette, FastGarden, and/or Animal vocalization challenges!
I’ve extended the fastai2 xresnet implementation using the official deconvolution repo linked above. Here, I’m only substituting FastDeconv layers in the stem of the model. This seems to create a really flexible (and quick to train) model!
Currently I’m running a few tests on my own hyperspectral astronomical data, and so far it looks like the loss drops extremely quickly. I’ve upped the weight decay (mentioned in the paper too) to about 1e-2 and might even try higher. In any event, early results are promising. I’d love to see it applied to other tasks!
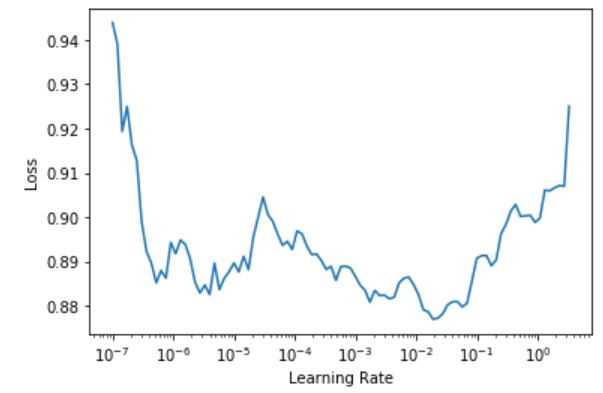
EDIT: another interesting result is that the learning rate finder seems to not work as well…
Maybe this is consistent with results from the paper suggesting that you can train at very high learning rates (lr = 1.0 with SGD at least).
Absolute loss values depend on your setup (e.g., loss func, number of classes, specific pretaining, etc.). Did you used a standard setup (model & data)?
Thank you for sharing this publication - looks very interesting!
Oh, it’s definitely a non-standard CNN task! I’m optimizing the RMSE loss function for multivariate regression using 5-channel images of galaxies The model is an adapted version of the xresnet18 architecture with deconvolution layers substituted instead of Conv2d + batchnorm.
This sounds very interesting! I haven’t had the chance to play with your code yet, but a quick read seems to suggest that pretrained would be ignored if set to True. Looking at the code from the paper authors, however, it appears that they are able to successfully load pretrained weights for the base architectures. Did you experiment with transfer learning at all, or are you training your models from scratch?
I actually implemented a custom version where deconvolution layers are substituted only in the stem of a CNN. In my tests (see the FastGarden thread), these hybrid deconvolution nets work better than regular CNNs or fully deconvolution networks. No such pertained networks are available for the hybrid versions.