I’ve been using Jupyter notebooks for long time, and when git and version control related activities I’ve been using Jupytext to convert from .ipynb to py:percent and then Pull Request, code review or just keep track of my train of thought when switching context to other topics. The advantage of having the code diff of what I was doing is important in my workflow.
I am experiencing the advantages of using nbdev for Python module / package and documentation.
Would like to know today with nbdev 2x what is the recommended best practice to keep track of the exploratory notebooks that are using the module been created?
I do not have ReviewNB for my private repos. Should I continue using Jupytext?
I’m not sure I fully understand your question. With nbdev, your notebooks are your source. The .py files are auto-generated from them. So you keep your notebooks in your repo just like any other file. Run nbdev_install_hooks to avoid conflicts. There’s no need to use jupytext when you’ve got nbdev up and running.
Thank you Jeremy,
I was reading your blogs and exploring the github repositories to learn how to use nbdev properly.
Was able to export and create the Python package properly. Same with documentation.
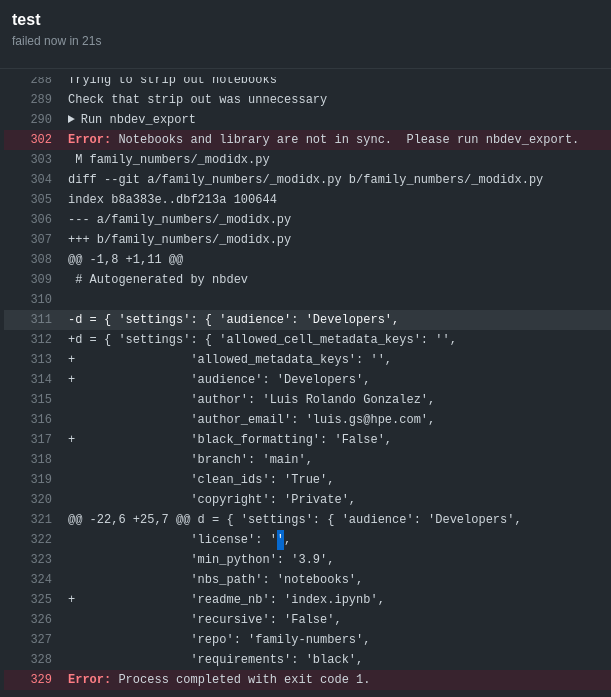
In the other hand, I see the GitHub Actions failing but not sure why, according to the logs, nbdev indicates notebooks and library are not in sync but they are. What do you suggest to check?
My guess is the version of nbdev, fastcore, or execnb on CI and your local version are different. Make sure you’ve got the latest versions, and run nbdev_prepare.
You are correct, defining the dependencies with proper versions the CI workflow move forward, however one of my notebooks should not be executed in GitHub Actions because there are other network entities required to complete the notebook execution that are not going to be available, are in private network.
Is there a way to skip or flag entire notebook to exclude in the CI test workflow?
Awesome! Moving forward, CI workflow completed successfully.
Where I can read more about the skip_exec syntax in raw cells?
Would like to see what else we can do.
Main place is the quarto docs – they have lots of things that frontmatter can impact.
Other than skip_exec, at the moment the only frontmatter nbdev adds is skip_showdoc, which avoids running any cells in the notebook when rendering docs.
Back to one of the questions at the top, @jeremy you mentioned no need of jupytext but how are you doing the code review, commenting and suggesting code changes using GitHub? Assume here is where you use ReviewNB product, correct?
Was exploring vscode to see pull request / issues extension could help but not able to find something here yet.
Doing the code review in the rendered notebook and then going to the JSON file to include a comment or suggest a code change… am I missing something? Would like to learn how are you doing code reviews because am getting used to nbdev so quickly but code reviews seems challenging.