In this imdb notebook (see screenshots) I used your notebook from this post in which you created 2 extra dummy labels to create an example multilabel training set. I am aware that for a simple binary classification with 0 or 1 output, my last output layer would have 2 outputs, so torch.nn.BCELoss() would be suitable. Even though by default fastai uses this loss function: torch.nn.functional.cross_entropy() which uses Softmax instead of Sigmoid and thus can be used for any number of classes (Side note: not to confuse with number of labels).
For multilabel I used BCEWithLogitsLoss() which combines Sigmoid with BCE loss to take advantage of log-sum-exp trick for numerical stability:
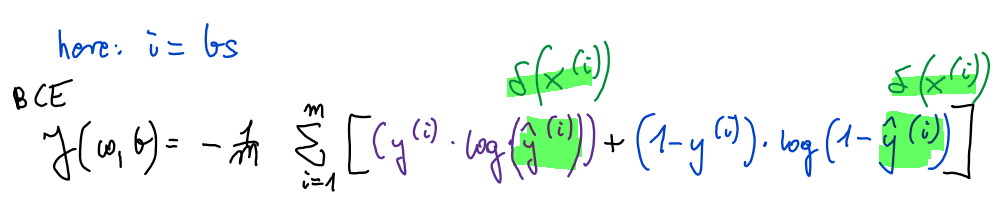
here: m = nr of training examples, y = targets, y hat = predictions
So my problem is still unsolved.