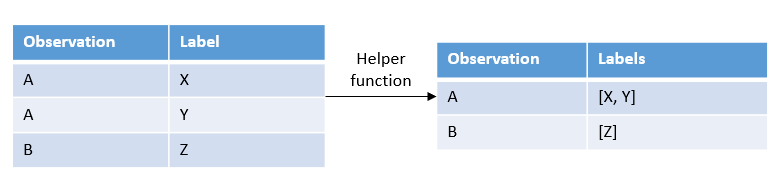
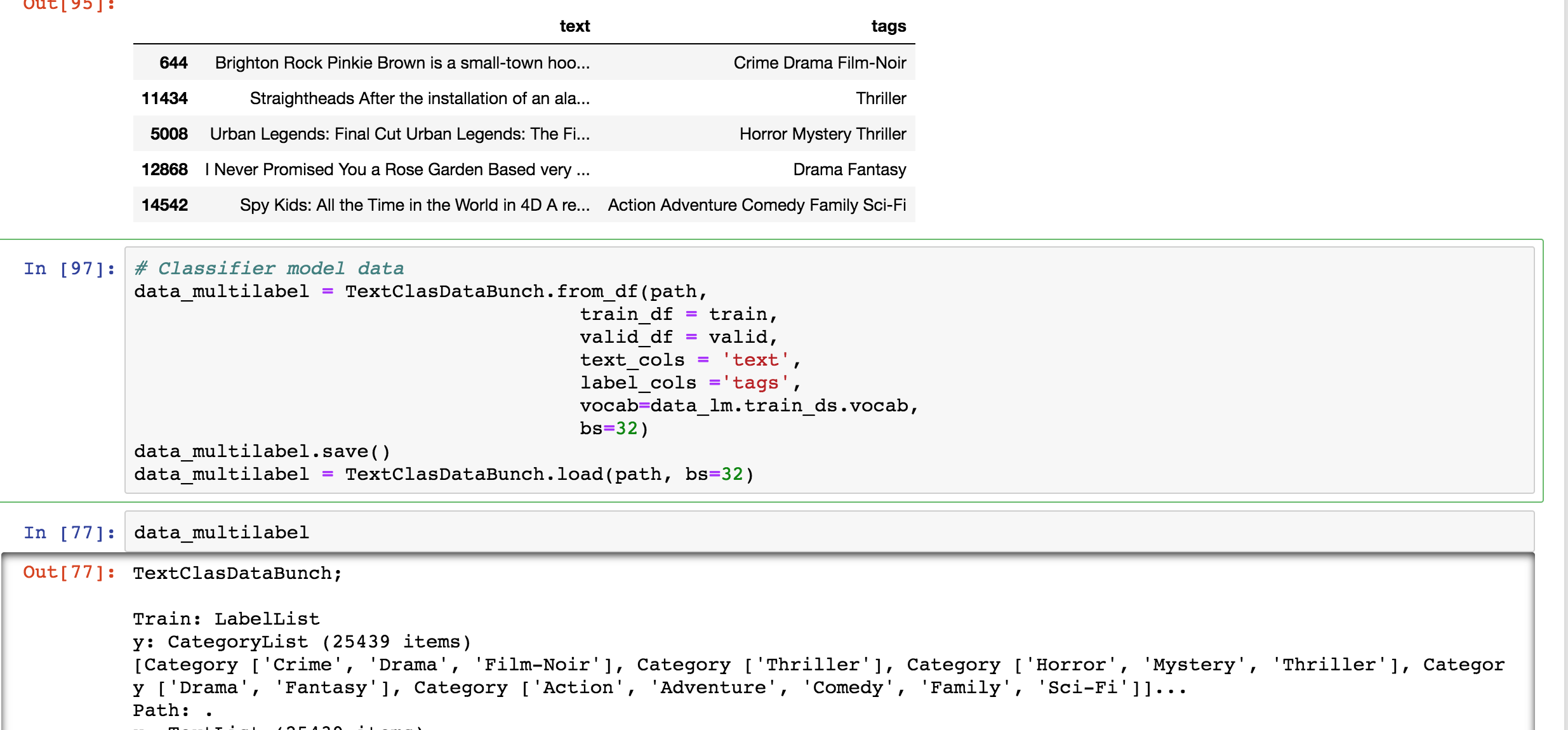
Thank you!
Now I get another error:
FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
res[x] = 1.
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-38-126d84ffee9a> in <module>()
1 multilabel_classifier.load_encoder('lm_encoder')
2 multilabel_classifier.freeze()
----> 3 multilabel_classifier.fit_one_cycle(1, 1e-2, moms = (0.8,0.7))
~/.local/lib/python3.6/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, wd, callbacks, **kwargs)
19 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor,
20 pct_start=pct_start, **kwargs))
---> 21 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
22
23 def lr_find(learn:Learner, start_lr:Floats=1e-7, end_lr:Floats=10, num_it:int=100, stop_div:bool=True, **kwargs:Any):
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
164 callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
165 fit(epochs, self.model, self.loss_func, opt=self.opt, data=self.data, metrics=self.metrics,
--> 166 callbacks=self.callbacks+callbacks)
167
168 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
92 except Exception as e:
93 exception = e
---> 94 raise e
95 finally: cb_handler.on_train_end(exception)
96
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in fit(epochs, model, loss_func, opt, data, callbacks, metrics)
87 if hasattr(data,'valid_dl') and data.valid_dl is not None and data.valid_ds is not None:
88 val_loss = validate(model, data.valid_dl, loss_func=loss_func,
---> 89 cb_handler=cb_handler, pbar=pbar)
90 else: val_loss=None
91 if cb_handler.on_epoch_end(val_loss): break
~/.local/lib/python3.6/site-packages/fastai/basic_train.py in validate(model, dl, loss_func, cb_handler, pbar, average, n_batch)
47 with torch.no_grad():
48 val_losses,nums = [],[]
---> 49 for xb,yb in progress_bar(dl, parent=pbar, leave=(pbar is not None)):
50 if cb_handler: xb, yb = cb_handler.on_batch_begin(xb, yb, train=False)
51 val_losses.append(loss_batch(model, xb, yb, loss_func, cb_handler=cb_handler))
~/.local/lib/python3.6/site-packages/fastprogress/fastprogress.py in __iter__(self)
63 self.update(0)
64 try:
---> 65 for i,o in enumerate(self._gen):
66 yield o
67 if self.auto_update: self.update(i+1)
~/.local/lib/python3.6/site-packages/fastai/basic_data.py in __iter__(self)
68 def __iter__(self):
69 "Process and returns items from `DataLoader`."
---> 70 for b in self.dl:
71 #y = b[1][0] if is_listy(b[1]) else b[1] # XXX: Why is this line here?
72 yield self.proc_batch(b)
~/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py in __next__(self)
613 if self.num_workers == 0: # same-process loading
614 indices = next(self.sample_iter) # may raise StopIteration
--> 615 batch = self.collate_fn([self.dataset[i] for i in indices])
616 if self.pin_memory:
617 batch = pin_memory_batch(batch)
~/.local/lib/python3.6/site-packages/torch/utils/data/dataloader.py in <listcomp>(.0)
613 if self.num_workers == 0: # same-process loading
614 indices = next(self.sample_iter) # may raise StopIteration
--> 615 batch = self.collate_fn([self.dataset[i] for i in indices])
616 if self.pin_memory:
617 batch = pin_memory_batch(batch)
~/.local/lib/python3.6/site-packages/fastai/data_block.py in __getitem__(self, idxs)
490 def __getitem__(self,idxs:Union[int,np.ndarray])->'LabelList':
491 if isinstance(try_int(idxs), int):
--> 492 if self.item is None: x,y = self.x[idxs],self.y[idxs]
493 else: x,y = self.item ,0
494 if self.tfms:
~/.local/lib/python3.6/site-packages/fastai/data_block.py in __getitem__(self, idxs)
90
91 def __getitem__(self,idxs:int)->Any:
---> 92 if isinstance(try_int(idxs), int): return self.get(idxs)
93 else: return self.new(self.items[idxs], xtra=index_row(self.xtra, idxs))
94
~/.local/lib/python3.6/site-packages/fastai/data_block.py in get(self, i)
330 o = self.items[i]
331 if o is None: return None
--> 332 return MultiCategory(one_hot(o, self.c), [self.classes[p] for p in o], o)
333
334 def analyze_pred(self, pred, thresh:float=0.5):
~/.local/lib/python3.6/site-packages/fastai/data_block.py in <listcomp>(.0)
330 o = self.items[i]
331 if o is None: return None
--> 332 return MultiCategory(one_hot(o, self.c), [self.classes[p] for p in o], o)
333
334 def analyze_pred(self, pred, thresh:float=0.5):
TypeError: list indices must be integers or slices, not NoneType
I’ve already made sure that there are no classes in the valid_df that are not present in train_df. What can I try to fix it?