Has anyone here worked on a multi-label classification problem using ULMFiT. Any pointers?
Also interested in this topic…
1 Like
Sure.
- Language Model works as is … so nothing needs to change there.
- For the classifier, a number of changes will be required (see below)
First, the datatype for your labels will need to be a np.float32 rather than an np.int64. Look at the pytorch docs for binary_crossentropy to better understand why and what is going on.
Second. the shape of your target values will need to be a numpy array such as (num_of_labels,). So, if you are trying to predict 5 labels, it is (5,)
Third, your classifier needs to know how many labels you are trying to predict, and also predict that many values. For example, here is how I create my model to predict 8 labels:
m = get_rnn_classifer(bptt, max_seq=20*70, n_class=8, n_tok=vs, emb_sz=em_sz, n_hid=nh, n_layers=nl,
pad_token=1, layers=[em_sz*3, 50, 8], drops=[drops[4], 0.1],
dropouti=drops[0], wdrop=drops[1], dropoute=drops[2], dropouth=drops[3])
Fourth, you’ll need to use F.binary_cross_entropy as your loss function (this i discussed at length in the course)
Fifth, you have several options to put your predicted values in the format you want … what I did was create another nn.Module and append that to the head of the sequential model you get from the code above. The code looks like this:
class MultiLabelClassifier(nn.Module):
def __init__(self, y_range=None):
super().__init__()
self.y_range = y_range
def forward(self, input):
x, raw_outputs, outputs = input
x = F.sigmoid(x)
if (self.y_range):
x = x * (self.y_range[1] - self.y_range[0])
x = x + self.y_range[0]
return x, raw_outputs, outputs
learner = RNN_Learner(md, TextModel(to_gpu(m)), opt_fn=opt_fn)
learner.reg_fn = partial(seq2seq_reg, alpha=2, beta=1)
learner.clip = 25.
learner.crit = F.binary_cross_entropy
learner.model.add_module('2', MultiLabelClassifier())
Sixth, use pdb.set_trace() everywhere to learn what is going on 
13 Likes
This is perfect, thank you!
A question, though: I was under the impression that the argument , n_class refers to the number of classes for any given label (and not the number of labels). Is that incorrect?
Further, the function definition of get_rnn_classifer() does not appear to be utilising this argument at all …
def get_rnn_classifer(bptt, max_seq, n_class, n_tok, emb_sz, n_hid, n_layers, pad_token, layers, drops, bidir=False,
dropouth=0.3, dropouti=0.5, dropoute=0.1, wdrop=0.5):
rnn_enc = MultiBatchRNN(bptt, max_seq, n_tok, emb_sz, n_hid, n_layers, pad_token=pad_token, bidir=bidir,
dropouth=dropouth, dropouti=dropouti, dropoute=dropoute, wdrop=wdrop)
return SequentialRNN(rnn_enc, PoolingLinearClassifier(layers, drops))
So I’m led to believe that whatever n_class we pass to the function is irrelevant, what goes into layers is what is important. However, I am not sure if layers=[em_sz*3, 50, 8] is going to give you predictions over 8 labels or 8 classes.
Take a look at the source. It’s not even used.
Thank you for the solution. How is the evaluation accuracy calculated in this case? I get errors as the accuracy function in fastai simply argmaxes the predictions which leads to one output column of labels. For my case, the labels are quite structured so I tweaked the accuracy function to average the accuracy after comparing the argmaxes of the specific columns I want, but this doesn’t generalize to all multi-label cases. Anyway, my problem is with the accuracy score printout during evaluation phase while the binary cross entropy loss seems to work nicely for training. How did you deal with this problem?
1 Like
Seconding @chiayewken. Setting learner.metrics = [acccuracy] throws the following TypeError:
File "/home/guest/.pyenv/versions/3.6.1/lib/python3.6/site-packages/fastai/metrics.py", line 10, in accuracy
return (preds==targs).float().mean()
File "/home/guest/.pyenv/
TypeError: eq received an invalid combination of arguments - got (torch.cuda.FloatTensor), but expected one of:
* (int value)I’m currently doing this by setting learner.metrics = [accuracy_thresh(0.5)]. And it seems about right.
See metrics.py for details.
You want to use multi_accuracy rather than just accuracy since you have multiple labels. I don’t have access to my computer so I can’t verify this, but I think you’ll find something helpful in either metrics.py or evaluation.py.
Use pdb.set_trace to see what is getting passed into the accuracy function as is and you’ll see why you are getting this error.
Thank you!
Hi,
I wonder if someone has a complete notebook to share for Multi-label classification using fastai.text. I will really appreciate as I can’t figure out how to do this. I fix one thing and then get stuck in another thing. This will be very useful for newbies. Thanks
2 Likes
Hi Everyone,
I am facing out of memory issue in Multi-label Classification using fastai library. I think I am making some mistakes that cause this error because this error arises even if I reduce the batch size to a very low 2. I am running this on AWS Instance that has a GPU with 12GB memory. The data set that I am using is not big either. I have uploaded the data and notebook to dropbox, which can be downloaded from this link. I will be very thankful if someone can help and comment what are the mistakes. This will be super useful for many users that are using wonderful fastai library.
Thanks
## Vaccines Classification
import warnings
warnings.filterwarnings("ignore")
from fastai.text import *
import html
BOS = 'xbos' # beginning-of-sentence tag
FLD = 'xfld' # data field tag
PATH=Path('data/vaccines/')
torch.cuda.is_available()
CLAS_PATH=Path(PATH/'vaccines_clas')
#CLAS_PATH.mkdir(exist_ok=True)
LM_PATH=Path(PATH/'vaccines_lm')
## Classifier
trn_clas = np.load(CLAS_PATH/'tmp'/'trn_ids.npy')
val_clas = np.load(CLAS_PATH/'tmp'/'val_ids.npy')
itos = pickle.load(open(CLAS_PATH/'tmp'/'itos.pkl', 'rb'))
#These are single-label data, with the labels in 0s and 1s form.
trn_labels = np.squeeze(np.load(CLAS_PATH/'tmp'/'trn_labels.npy'))
val_labels = np.squeeze(np.load(CLAS_PATH/'tmp'/'val_labels.npy'))
#Creating multi-labels just for testing purpose
trn_labels1 = np.array([trn_labels, trn_labels,trn_labels,trn_labels,trn_labels,trn_labels,trn_labels])
trn_labels1 = trn_labels1.transpose()
val_labels1 = np.array([val_labels, val_labels,val_labels,val_labels,val_labels,val_labels,val_labels])
val_labels1 = val_labels1.transpose()
val_labels1.shape
em_sz,nh,nl = 400,1150,3
wd = 1e-7
bptt = 30
bs = 24
opt_fn = partial(optim.Adam, betas=(0.8, 0.99))
vs = 60004#len(itos) 60004
min_lbl = trn_labels1.min()
trn_labels1 -= min_lbl
val_labels1 -= min_lbl
c=7#int(trn_labels.max())+1
trn_ds = TextDataset(trn_clas, trn_labels1)
val_ds = TextDataset(val_clas, val_labels1)
trn_samp = SortishSampler(trn_clas, key=lambda x: len(trn_clas[x]), bs=bs//2)
val_samp = SortSampler(val_clas, key=lambda x: len(val_clas[x]))
trn_dl = DataLoader(trn_ds, bs//2, transpose=True, num_workers=3, pad_idx=1, sampler=trn_samp)
val_dl = DataLoader(val_ds, bs, transpose=True, num_workers=3, pad_idx=1, sampler=val_samp)
md = ModelData(PATH, trn_dl, val_dl)
dps = np.array([0.4,0.5,0.05,0.3,0.4])*0.5
m = get_rnn_classifer(bptt, 20*70, c, vs, emb_sz=em_sz, n_hid=nh, n_layers=nl, pad_token=1,
layers=[em_sz*3, 50, c], drops=[dps[4], 0.1],
dropouti=dps[0], wdrop=dps[1], dropoute=dps[2], dropouth=dps[3])
opt_fn = partial(optim.Adam, betas=(0.7, 0.99))
learn = RNN_Learner(md, TextModel(to_gpu(m)), opt_fn=opt_fn)
learn.reg_fn = partial(seq2seq_reg, alpha=2, beta=1)
learn.clip=25.
learn.metrics = [accuracy_thresh(0.5)]
lr=3e-3
lrm = 2.6
lrs = np.array([lr/(lrm**4), lr/(lrm**3), lr/(lrm**2), lr/lrm, lr])
#lrs=np.array([1e-4,1e-4,1e-4,1e-3,1e-2])
len(itos)
# This is language model previously trained on data
learn.load_encoder('V_lm_enc_last_ft')
wd = 1e-7
#learn.freeze_to(-1)
#Memory error even with very small batch size (bs) and bptt
learn.fit(lrs/10, 1, wds=wd, cycle_len=1, use_clr=(8,3))I’m unsure how the training data should be stored. Typically, we create a “train” folder, and for each class, we create a folder with its name (e.g. “positive” or “negative”), and that folder is filled with examples of that class. We could continue that structure here, but then you would only ask the model to predict on one label at a time, and it’d never learn to output multiple labels. Even if it tried to output multiple labels, it’d be penalized because the structure is such that it only ever sees one label at a time.
How do we translate this structure of data to the multilabel scenario?
Multi-label classification is different from traditional way of keeping label data in corresponding label folders. It is discussed in fastai lesson 3 for images but I am trying to do it for text. Other people probably have done this but I have problem. Hopefully someone may help.
As I asked the question, I realized that was probably the case. I’ll go ahead and rewatch the video (it’s been awhile) and update you if I have success.
1 Like
The only difference is that instead of a single label column, you have multiple label columns (where the value is 0 or 1). Other than that, everything is the same.
1 Like
I understand that, but my question was specifically directed at how we access our stored training data, not how do we structure it once we have it loaded. The storage structure in the ULMFit lecture doesn’t lend itself to multilabel classification, but @zubair1.shah reminded me that previous lectures might help with finding the appropriate structure.
It looks like the major difference in data processing comes in at the get_texts method. It assumes that each text only has one associated label, so we need to overhaul that in order to read in multi-label appropriately. @wgpubs, is this correct? And in a previous reply, you mentioned needing to have a column for each possible label, marked with a 0 or 1. However, in past fastai multi-label case studies, we’ve put all the labels into one column. Clarification here would be appreciated. If this is the case, it’d be great if you could edit your original post with some tips on preprocessing, since the imdb notebook assumes your data comes in a particular format.
You don’t need to overhaul it. I’m seeing two scenarios, based on your questions:
- The data are in a single csv with one text column, and one (or more) label columns.
- The data are in text files, stored in subfolders based on their class.
The workflow in the imdb notebook moves data from scenario 2 to scenario 1. Scenario 1 is the standard. The get_texts function takes a slice of columns as labels, based on the n_labels parameter, and for each row in the dataframe, loops through that number of columns. What you get in the case of a single label is a n-dimensional column vector with the label, where n is the number of data instances (or the batch size, if you’re in a training loop). In the multi-label case, you get a n x m matrix, where n is, again, either the number of data instances or the batch size, and m is the number of labels. The values in this matrix are usually 1 or 0.
Here’s a snippet that shows how you could move from a dataset that looks like this:

To this:
text_labels = [f'Label {n+1}' for n in range(12)]
for index, row in trn_df.iterrows():
for c in text_labels:
c_val = row[c]
if isinstance(c_val, str):
trn_df.loc[index, c_val] = 1
# print(c_val)
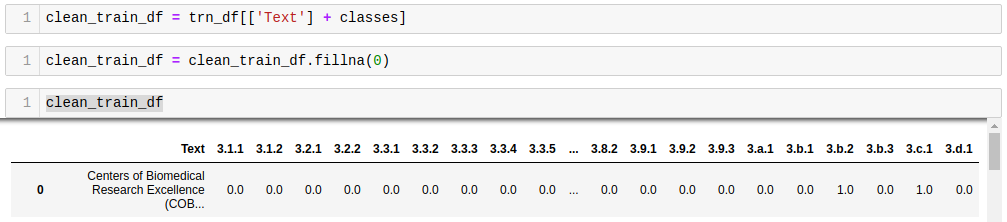
where c_val tracks the column names seen in the second screenshot. Note the values in the row are 0.0 and 1.0. The 1.0 values are set by trn_df.loc[index, c_val] = 1, while the 0.0 values are set by clean_train_df.fillna(0), since the resulting values there are NaN.
Note that, to fit with the standard set in get_texts, the line clean_train_df = trn_df[['Text'] + classes] should instead be clean_train_df = clean_train_df[classes + ['Text']], which follows the convention: ['labels', 'text'].
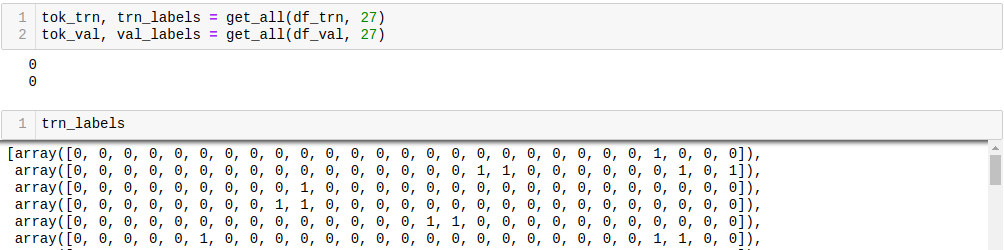
To use clean_train_df as the classification dataset in the state I show in the second screenshot, I set n_labels to 27 (the number of labels), which got me a 3900x27-dimensional trn_labels vector.
FYI this is all much easier in fastai v1. Have a look at the docs and examples and let us know how you go.
2 Likes