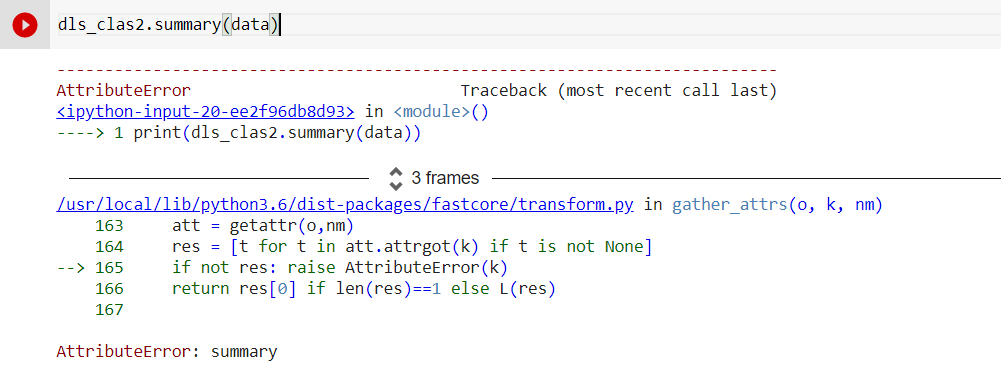
@msivanes Hello , I have a pretrained language model for text classification learner i have Initialized a datablock and ran it . But I got an error while returning the summary.
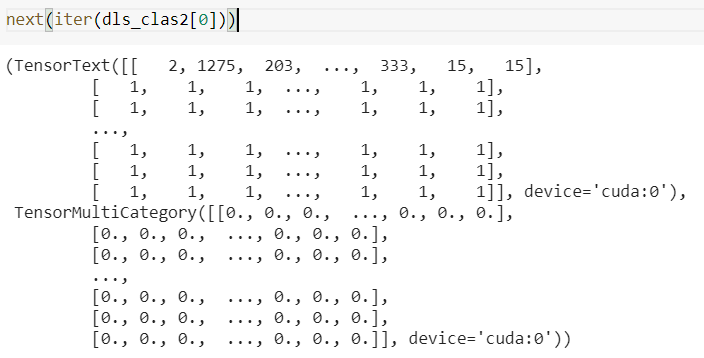
Here is the snapshot of a sample record . Could you please look into this and suggest the following pipeline accordingly…

Thanks in advance,
Anish