Hello everyone,
I have a data which consists of text column and label column. I have to do a multi label classification for each sample. here is a snapshot of my data .

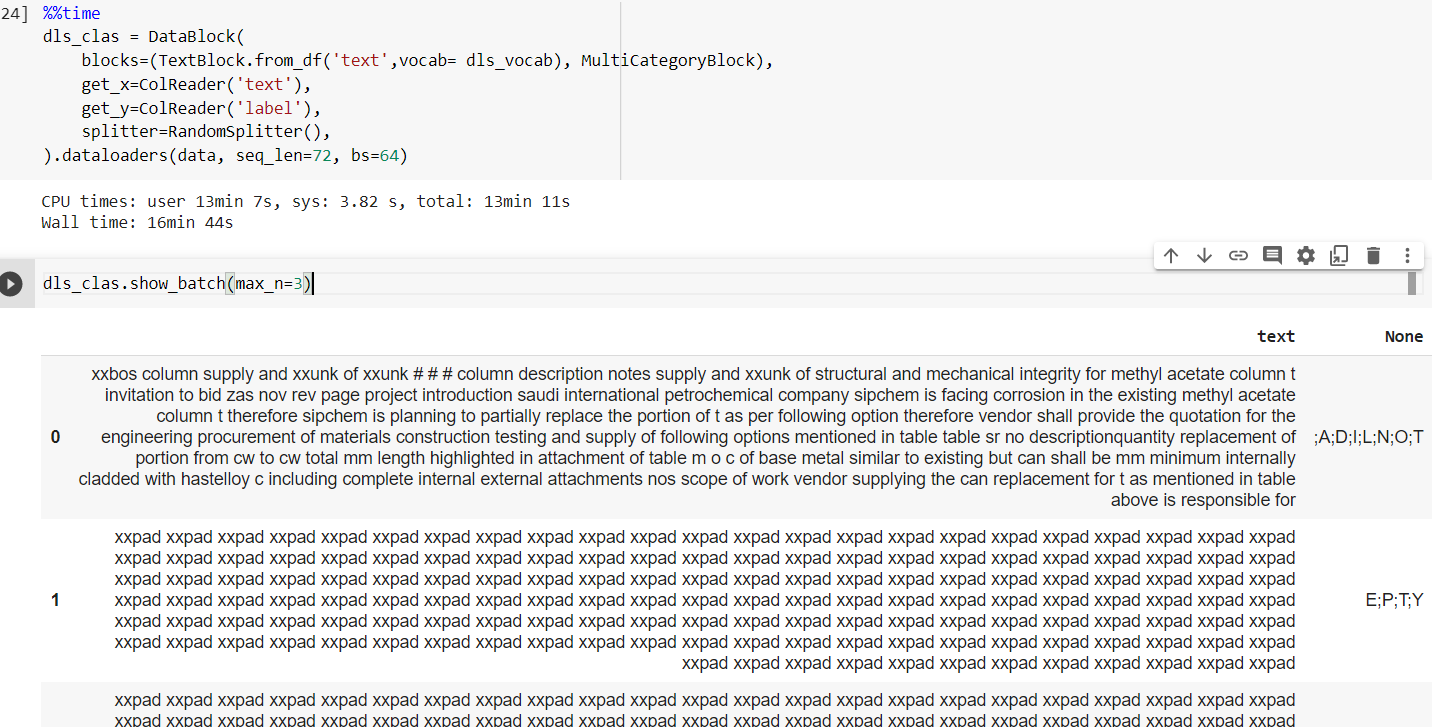
1 Like
@Anish_sri I think you need to specify label_delim parameter for get_y ColReader
@arampacha hello,
can you tell what would be the label_delim = [; ,|] …?
in your dataset labels are separated by spaces, so try label_delim=' '
@arampacha hello, I have tried by taking label_delim =’ '. I have a doubt regarding the input as my whole motive is to predict multiple labels for a input where my label column has only one label per sample. Is there a possibility that ULMFIT can perform this task. …? As if you see my upper post it is categorizing into different inputs that are not there in the dataset. could you please help me out in solving this problem.
Thanks In Advance,
Anish srivathsav
Oh, I thought those were different labels separated by space. In case you have a single label for each item, using any character which is not encountered in your labels as label_delim should work (e.g. label_delim='*')
@arampacha Hello,
It dosent’ work even if i have provided other delimiter that have been not there in dataset.
Thanks,
Anish Srivathsav
Ok, you want your system to work if it encounters previously unseen labels, right? Try using
MultiCategoryBlock(add_na=True), I guess it might help
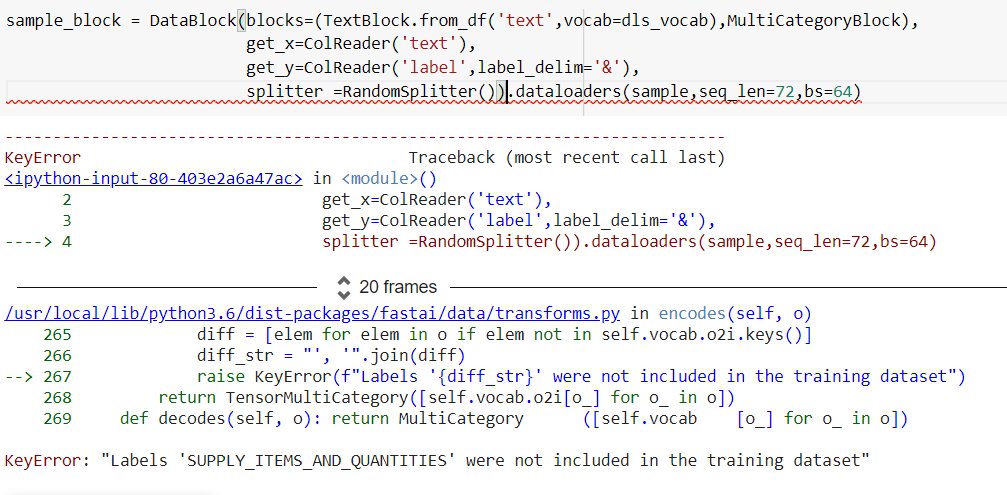
@arampacha No, The label which is displaying it as error . all those labels are included in the dataset . Now when i have done this by including add_na = True . it doesn’t help me. Now i got another label was missinfg from dataset.
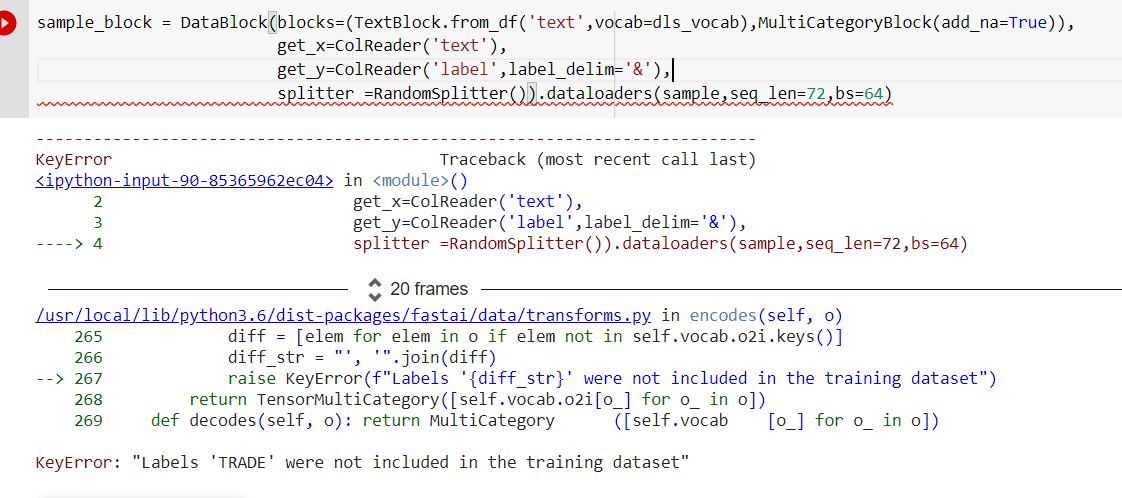
@arampacha Can you help me in deciding this whether it is correct or not…? like i thought of a solution where by taking one hot encodings of all labels and store it in a data frame .
. But i was unable to figure out how to create a datablock for this by using multilabel problem…?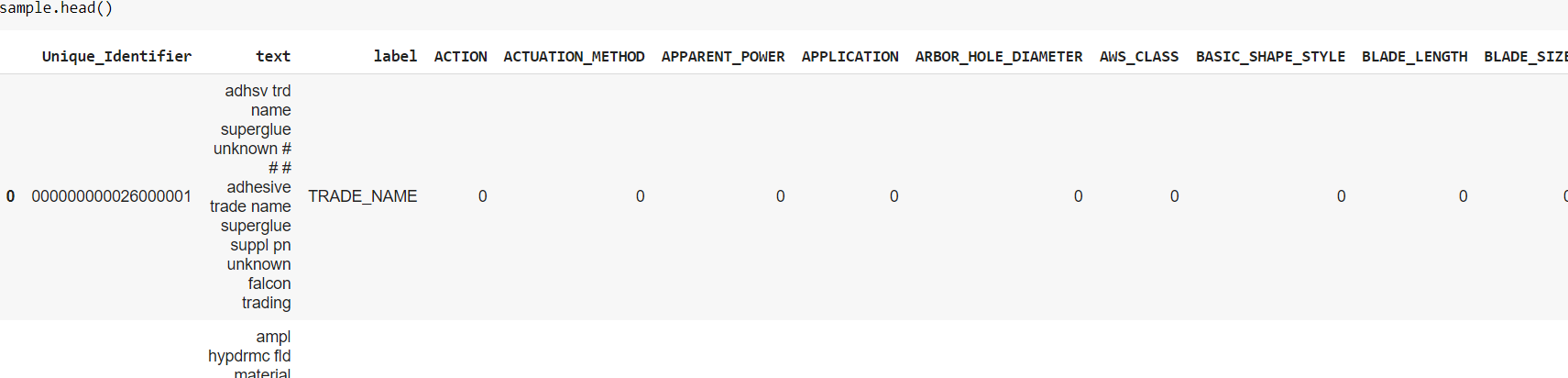
@arampacha I have found a similar article related to multi label text classification where they performed it using fast,ai version 1 but I am unable to figure out for version2 . Here is the following code snippet of fastai V1.
. I think if we found a alternative for this will help finding a solution .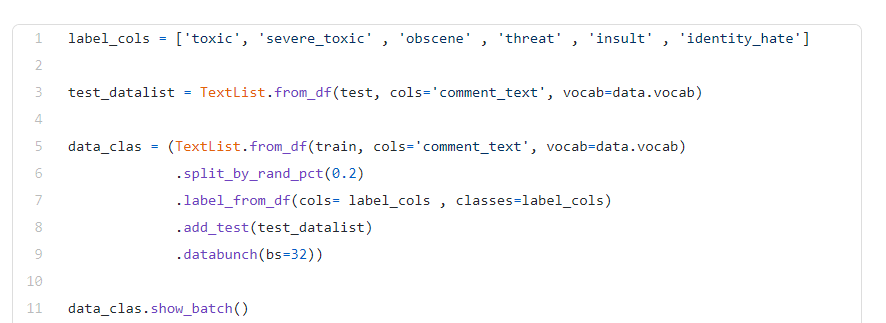
Thanks,
Anish srivathsav
Well, seems add_na parameter does something different from what I expected.
You can also try passing vocab parameter with all your label to MultiCategoryBlock.
1 Like
@arampacha well, I tried that also by passing labels to vocab. That doesn’t help me solving the problem. The same error was getting repeated.
Also I think that error is caused by fact, that some of labels end up missing in your train dataset when you do random splitting. How much data do you have? Are there rare labels? You can try to do stratified split
@arampacha No I have enough samples in my training data around 5 lakh records with decent number of labels in it. I trained a classifier fit for one cycle , ulmfit got overfitted. I am looking for any alternate approach to do the multi label classification . Thanks for helping me by taking your time to help me out . I am open to any suggestions if you have any to perform a multi label classification where targets are in column with one label per sample.
Thanks,
Anish Srivathsav
Can you try datablock.summary(df) and paste the results. It will help to show the pipeline for y and show where things are going wrong.
@msivanes Hello , I have a pretrained language model for text classification learner i have Initialized a datablock and ran it . But I got an error while returning the summary.
Here is the snapshot of a sample record . Could you please look into this and suggest the following pipeline accordingly…
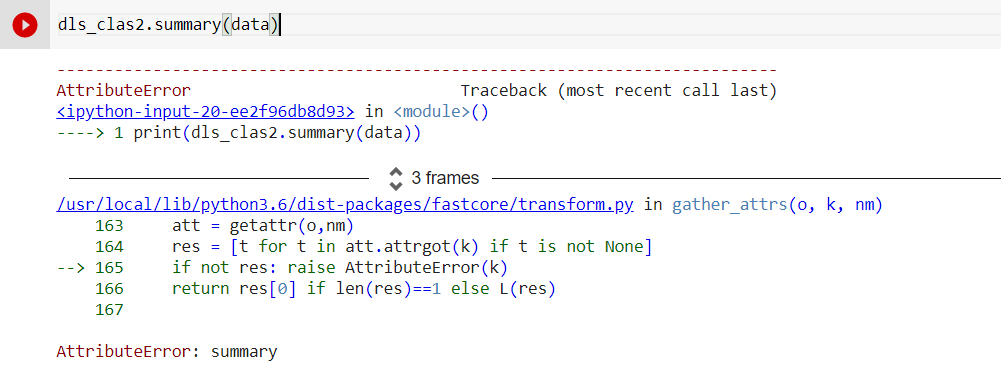

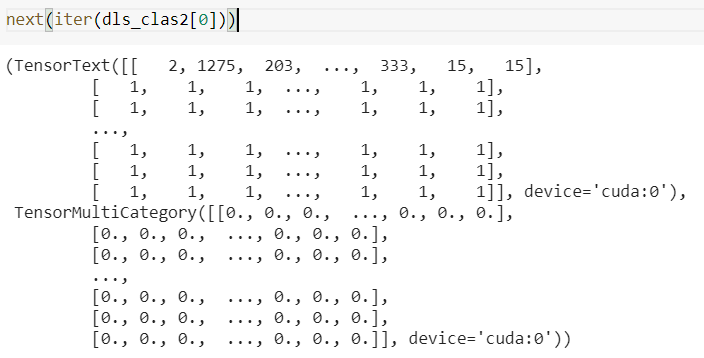
Thanks in advance,
Anish
@Anish_sri
you may need to call the summary on DataBlock() instance and not on DataLoaders.
dblock = DataBlock(blocks=..., get_x=..., get_y=..,splitter=...)
dblock.summary(source=data)
1 Like
@arampacha @msivanes
Hello Manikandan and Arampacha , Thanks for helping me in solving the multi label problem. I have a question regarding the embeddings from the ULMFIT . Is there any way to get the vocabulary tokens of ULMFIT language model embeddings ? If there is a possible way can you please provide any suggested articles or github links to get those embeddings …
Thanks in Advance,
Anish
Yes you can.
Is there any way to get the vocabulary tokens of ULMFIT language model embeddings ?
The vocab attribute from the dataloaders instance you create would have the vocabulary.
For example, dls.vocab
This colab showcases how to inspect the tokens from the pretrained model (wiki dataset) and also from the new tokens added from your task specific corpus.
1 Like