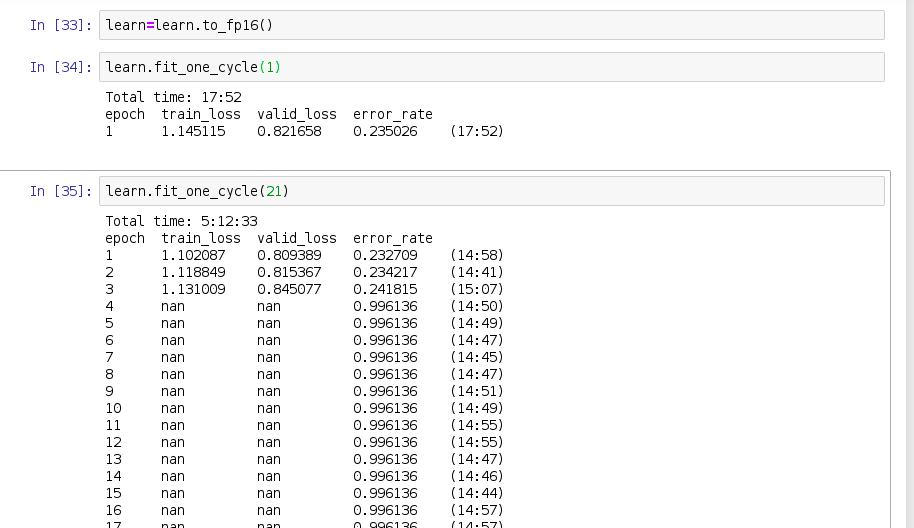
Has anyone been able to try Mixed precision training? I am using a v100 on GCP. When I start with fp16() it helps me speed up by epochs by ~25% but later on, I am getting a bunch of nans.
Is there something I am missing?
Has anyone been able to try Mixed precision training? I am using a v100 on GCP. When I start with fp16() it helps me speed up by epochs by ~25% but later on, I am getting a bunch of nans.
Is there something I am missing?
I’ve been getting this too, sometimes, on long run training. I thought it may be my new GPU (2080ti) and funky cuda/pytorch/driver combination.
Do you just restart your kernel and start over when you get this or something else?I wonder is this due to some parameter setting I am missing .I am keeping all defaults as of now on fp16
Not sure what the issue is. I Have reported it before, but would be good to hear of others experience. Do you have any transforms() in your training? It could be something in a transform going awry.
Yeah I do.What kind of benefit you are observing on using fp16() ?Is it close to ~25% that I reported?
yes about 25% on average
Looks like we are on right path.Will be good to know what others are experiencing with mixed precesion training.
I don’t have much experience with fp16 training but I know one known issue is that gradients or other small values can become zero due to the lower numerical precision. One way around this is to scale up the loss value (ie by a factor of 1000), which by the chain rule also scales the gradients. This might be a solution to the problem you’re seeing.
Thanks Karl.I might have to try that.
The point of mixed precision training is addressing such shortcomings of pure FP16. The library should take care of this: the parts which are sensitive to truncation and/or rounding are handled in FP32.
I’d like to see memory occupation about the same training cycle for FP32 vs. Mixed. Thanks.
I was also playing with the mixed precision training and was not observing some NaN losses so far.
There seems to be also a callback to stop the training when the loss is getting NaN: https://github.com/fastai/fastai_docs/blob/master/dev_nb/new_callbacks.ipynb (However, I didn’t tested it so far.)
Here is the super explanation from Sylvain: Mixed precision training
PS: Maybe also for your interest: learn.TTA(is_test=True) not supporting half precision models?
I am experiencing same issue with mixed precision training. The validation loss reaches nan at about 25-30% of training process. Will try to increase the loss_scale factor to 1000 and let this thread know it’s result.
Even after changing the loss_scale factor in to_fp16() to 1000.0 gives nan value more early around 3% of training. Is this problem specific to a particular kind of data?
Can this be related to vanishing gradient problem ?
So has anyone actually managed to make to_fp16() work in the sense that it has shortened training?
I have successfully used mixed precision to speed up training on Colab with an image classification task with a FastAI CNN with a batch size of 16. When using a batch size of 256, I didn’t see any speed improvement. Not sure why.
For the same task on Kaggle, using mixed precision made training slower than the default fp32 training! That was very surprising. The CUDA and cuDNN versions were older on Kaggle. I’m not sure if that is the cause.
Colab is using CUDA 10 with a K80 and Kaggle is using CUDA 9 with a P100.
Overall, Kaggle was faster than Colab.
Any one have any ideas why training if faster sometimes but not others?
AFAIK, you need Cuda 10 and >=410 drivers in order to use fp16 effectively.
May I ask you a quantification of the speedup you registered in fp16 on colab with cuda 10?
No idea about the slowdowns with higher batch sizes. I can say I noticed a slowdown in convergence when training in fp16. For me, the best thing about fp16 is that it effectively doubles your vram.
Thank you @balnazzar. That makes sense re Cuda 10. I thought I saw fp16 should work with lower in Nvidia’s specs, but my findings agree with what you’ve said.
Here’s the article where I discuss with the speeds: https://towardsdatascience.com/kaggle-vs-colab-faceoff-which-free-gpu-provider-is-tops-d4f0cd625029 19:54 to 16:37 training time improvement on Colab with fp16 vs fp32.
Agree regarding vram.
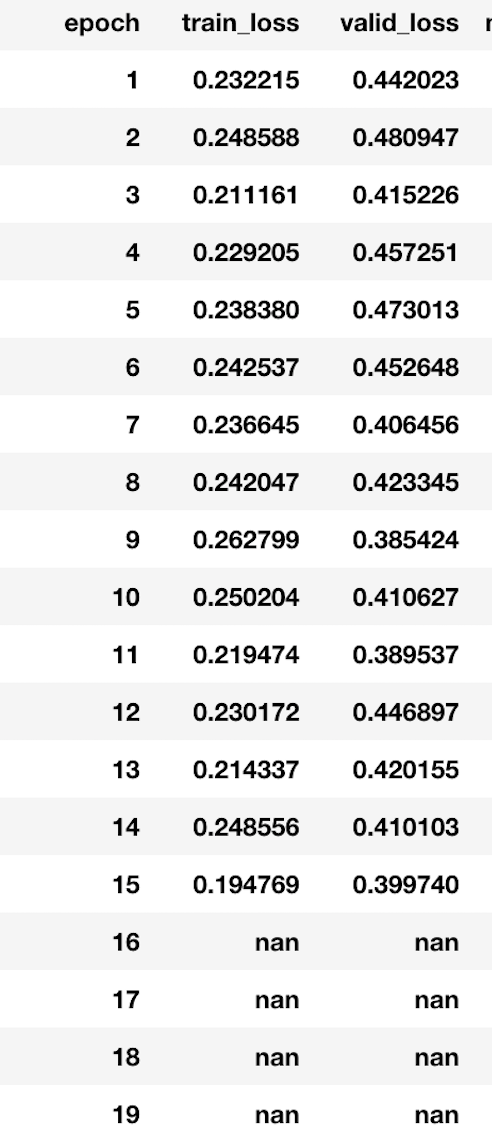
I am facing a similar issue with mixed precision training where my loss goes to NaN after 5-6 epochs. What is the best way to debug such issue?
Possible Fix: Setting Adam eps=1e-4 and using clip in to_fp16 seems to work.