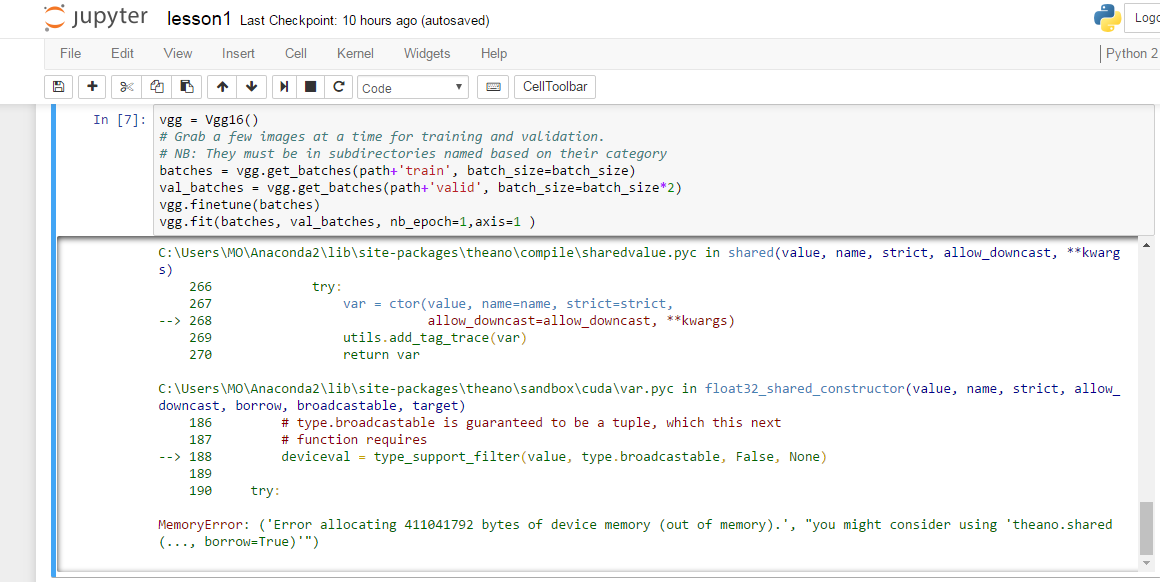
I keep getting a Memory Error on a sample data with a small batch size. Not sure why this is happening (this is a model I’m trying to train from scratch).
MemoryError: (‘Error allocating 7803502592 bytes of device memory (out of memory).’, “you might consider using ‘theano.shared(…, borrow=True)’”)
Anyone have thoughts around how to even debug this issue? Everywhere I’ve read speaks about the batch_size which I’ve reduced to 8 and it’s still crashing…
Any off chance restarting the kernel would fix it? Are you also running on a aws instance or locally? Also noticed that your batch normalization does not have axis=1. Apparently it is important for an n channel input.
I am trying to play around with other datasets and it seems that I ran into memory problem. I run my code in my own PC that has 32GB of RAM. When I opened system monitor after I run, let’s say,
x = 10*np.ones((50000,3,224,224))
I can see that it takes almost half of my RAM and won’t free it. Same thing happened when I open my dataset using bcolz, so when I open the rest of my dataset, I get the memory error message.
For my t2.micro instance (Ubuntu 16.04 AMI), the minimum swap file size to make lesson1 work is 2GB (with batch_size=1). With 1GB as in the stackoverflow example you’ll still run out of memory.
Note that some comments on stackoverflow talk about AWS charges for EBS I/O, so use at your own risk (I’ve just done it today so I don’t know yet if I’ll have charges).
Personally I created a script to add the swap partition on demand (and don’t persist it), and I reboot after I’m done using the swap (as swapoff won’t work)… just in case.
If anyone want’s to try out their environment using t2.mico. I found you can run the Mushroom Classification training without running out memory. https://www.kaggle.com/giuseppemerendino/deep-mushroom-keras-t-sne/notebook. It’s a very small data set but good for validating your environment is setup correctly.