Thanks to everyone’s work testing these new optimizers. I have been switching among Adam, RAdam, and Novograd, with and without the Lookahead wrapper. It’s all anecdotal, but I can’t see any significant difference in their rates of convergence or asymtotic losses. The only standout conclusion is that RAdam’s loss graph is smoother.
One observation: I see a large variation in loss over the same training period, about ±15%, depending on the random initialization of the model. So it will be important to average many runs to assess the relative performance of these optimizers.
My (hobby) test case is time series of 5000 stock prices x 16 symbols, trained with 20000 passes at lr=.001 followed by 20000 at lr=.0001. No RNN, all “parallel” operations.
I’ll keep testing, and hope we can figure out the useful domains of these new optimizers.
I got about 2.5 hours of testing in before getting pre-empted.
Summary so far is Novograd produces nice curves and ends up about the same place as Ranger (RAdam+Lookahead).
I tested Novograd + Lookahead and the training got more erratic.
One takeaway so far is that for Ranger or Novograd, they all seem to do better with higher learning rates vs Adam. 5e-2 or so seems to be a good spot for it at least on ImageNette.
I’ll try tomorrow on ImageWoof and see if a harder dataset pulls out more differences.
I’ll have to start a new thread but Novograd is doing great on ImageWoof. It seems a harder dataset is what is needed to really show the differences for the optimizers.
I just got pre-empted again but here’s the initial results. I’m testing a few other lr if I can get back on and will then run for 5 and hopefully submit for a new leaderboard score:
When you are doing a direct comparison, how do you determine the learning rate for each Adam, RAdam, Ranger?
I’m testing them now with the same hyper params.
I’m trying to fix everything except for the optimizer to remove the effect that I might have just picked a bad lr for the respective optimizer but I’m now wondering it’s the wrong approach.
Before concluding that Novograd is better than Adam in this case, you might want to rerun the baseline with Jeremy’s intended effective learning rate. (as I described elsewhere[1], the baseline was run at lr = 0.75e-3 and not the intended lr = 3e-3 because of an oversight in the code).
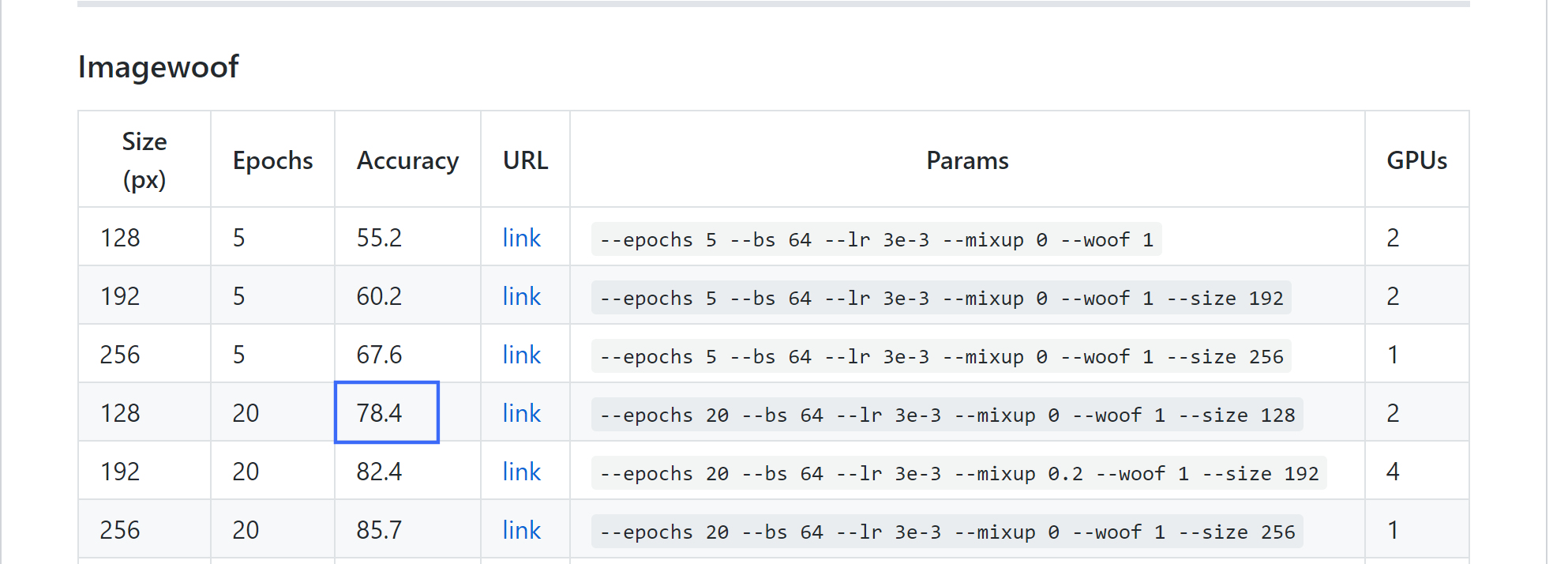
I don’t have data for 128 px, but on imagewoof 256px, I reworked the baseline at 83.9% rather than 81.8%
(the 85.7% being my entry to the leaderboard, but I don’t like it too much because it runs slower).
Also, I suggest running on vast.ai when salamander is not happening. Cheaper, faster, no pre-emption; but you usually “lose” your machine and files if you stop, and machines are not always available.
Hi @Johnny,
Unfortunately you can’t run all the different optimizers under the same lr or you will hold most of them back.
So far all of the new ones work better with a higher lr than Adam. In general, 8x higher lr (5e-2 for example vs 3e-3 for Adam).
Unfortunately finding a good lr is a bit of trial and error - I just run the lr finder, pick a spot from that and test. Then I’ll run +/- 10x from there (i.e. 5e-1, 5e-2, 5e-3) to try and do a bounds test and then have a pretty good idea what works for testing.
With Ranger, the other wildcard is the k parameter - 5 or 6 is the default but I believe they also used 20 at one point in the paper and so running with 10 or 20 for k as a test would be a good thing to.
Please post any results you get!
Best regards,
Less
Well hours and dollars later, nothing really promising - here’s the results:
Novog (5e-2 lr):
20 epoch
80.6
80.6
80.2
81.2
82.4
Average of 5: 81%
RangerNovo (Novograd + LookAhead):
81.80
Ranger (RAdam + LookAhead)
80.00
Adam:
80.8
81.0
80.9% total
So, Adam and Novograd end up in a virtual tie (and @Seb was right, the leaderboards seem to be off as it has 78.4).
RangerNovo may have some promise but I got pre-empted before I could run more than 1 time.
I reread the Novograd paper and noted that they used LabelSmoothing…re-running with the following changes and I’m getting much better results:
1 - LabelSmoothing + Mixup
2 - no weight decay
I’m getting around 82% on multiple runs, or about 1% better than Adam and +1% than w/o labelsmoothing. I got worse results when I used labelsmoothing + regular Adam by comparison.
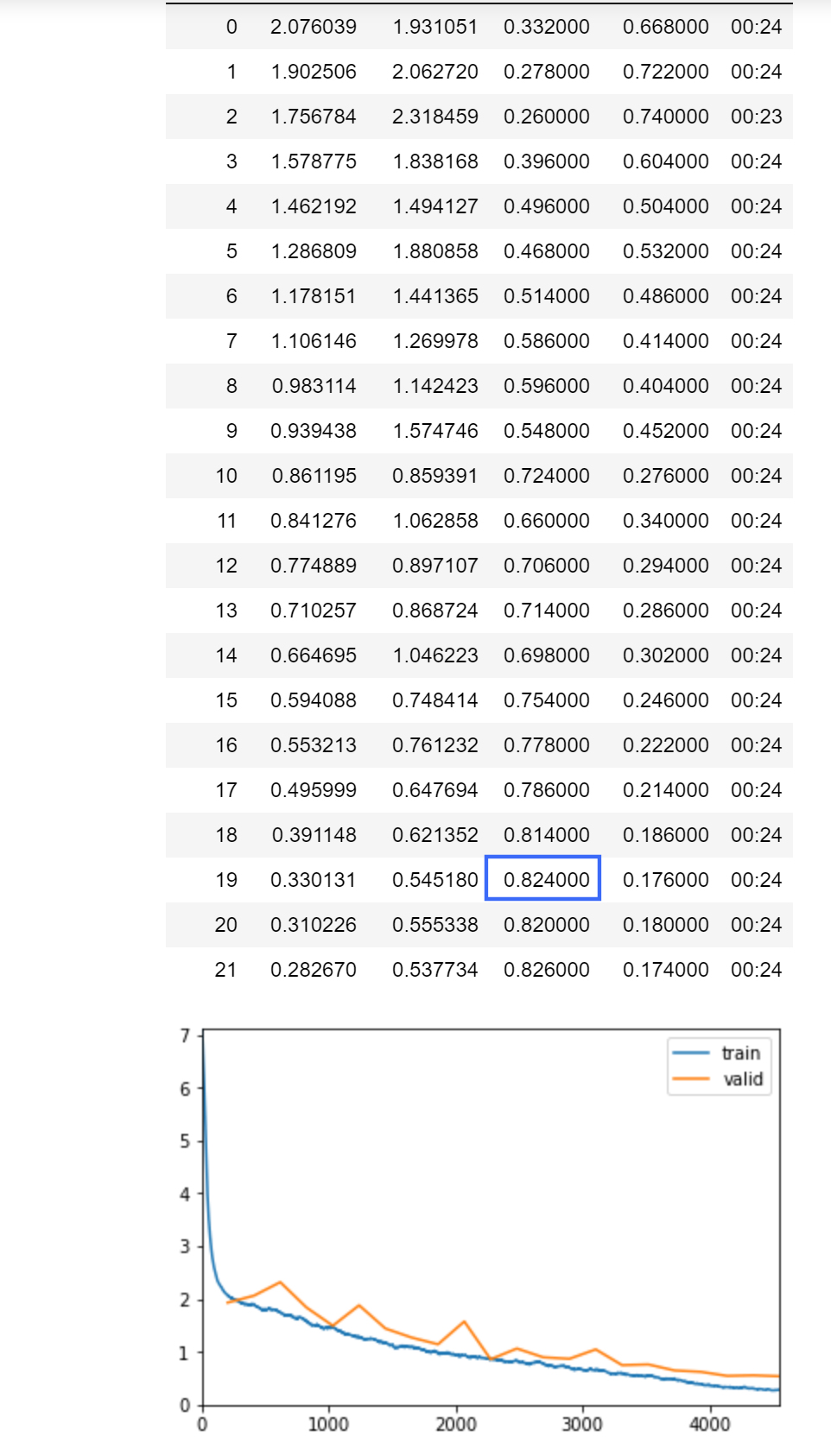
So Novograd still has some promise. I’m also testing one more (Stochastic Adam) that doesn’t beat on the 20 epoch but the training curve is soooo smooth that I want to test running up to 40 epochs for all of these and see if stochastic Adam outperforms or not.
On other news - the code for AutoOpt will be released tomorrow and that is going to be very, very exciting - 100% fully automated learning rate and momentum handling, and they showed it finds the equivalent best params vs manually doing an intensive grid search for each data set.
Who knew the optimizer space would be such a hotbed of activity this summer lol.
hi @LessW2020, I was wondering if the LookAhead algorithm ruins the built-up momentum of the RAdam / Adam? As RAdam is good at the beginning of training steps I think it’s worth trying to zero out the moving average of gradient and square of gradient (m ,v) at every LookAhead update.
The current approach forces the optimizer to move towards the original direction (before LookAhead update, because of the nature of momentum-like approach) while a non-informative prior might be a better estimate of the actual optimal direction on the new weight position (no favored direction to move). And RAdam can handle cold re-starts.
Hi @guyko,
It’s definitely worth testing - let me try and setup a quick run with that and will let you know! I think I will also test increasing K for this setup (i.e. instead of 5, maybe test with 10 and 20…).
This is how we find improvements so thanks for the idea!