I think so - I also think the lr finder itself might need to be modified. I’m actually going to see if I can blend an autolr optimizer I’ve been working with and combine it with RAdam’s rectifier.
First results on epochs 20.
On woof.
lr = 1e-1 (!!!) - 0.798
lr = 1e-1 - 0.790
lr = 1e-2 - 0.806
lr = 3e-2 - 0.800
lr = 3e-2 - 0.802
Now started train on 80 epochs - it takes time )
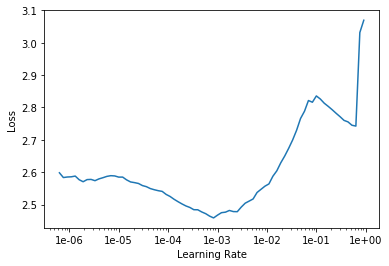
with adam
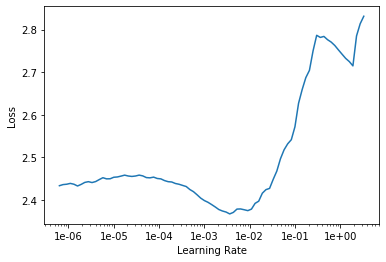
with RAdam
Had a very similar shift in lr finder on a different dataset.
I spent this morning merging Lookahead + RAdam into a single optimizer (Ranger). The merge may not have been needed as you can link both together by passing one into the other, but I felt it would make it easier to have one single optimizer to integrate with FastAI.
Lookahead is Hinton’s paper from last month that they showed outperformed SGD - it basically maintains a slow average that periodically merges in with the regular optimizer weights (Adam was what they used but I’m using RAdam)…analogy is a buddy system where one explores while the other has a rope to pull them back if it turns out to be a bad path.
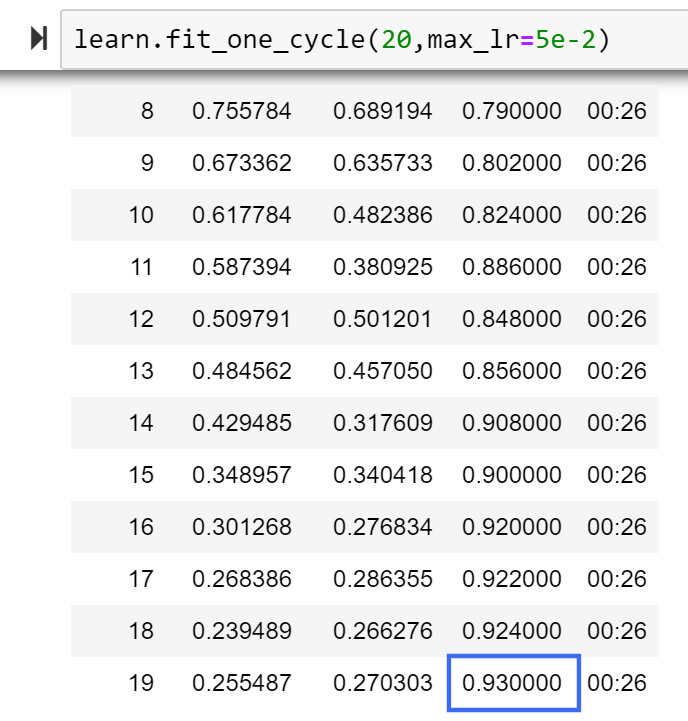
Anyway, first results are impressive - got 93% for 20 epochs vs 92% current leaderboard and I had 92.4-92.5% with RAdam alone. That’s a first run only with a guesstimate LR, but makes me feel confident I’m on the right track.
Training looks even more stable than with RAdam alone.
Was doing the next run and got kicked off via pre-emption yet again on Salamander, so I’ll continue with more runs later as I have to get other real life things done…but wanted to post that for anyone that didn’t have improvements with RAdam, hold out for Ranger here as it brings another arrow to the game.
11 Likes
FYI the Radam github has been updated with a readme.
1 Like
Less: Keep up the good work with Ranger (I look forward to using it in the future). RAdam was easy for me to implement with Fast.ai, but I did not show improvements in my RAdam optimized kernel.
2 Likes
Thanks for the kind words @Ajaxon6255!
Please give Ranger a try and see if the addition of LookAhead improves your results!
Just a tip, you can read an article in medium without limitation, if you don’t login 
1 Like
I wrote a post where I explain why it looks like current baseline on the leaderboard is lower than it should be. It wasn’t quite about number of GPUs after all.
1 Like
Yes, i find it too.
I forget about it. When i tried default baseline, i used real lr - changed this line. 
So did you get same results as on the leaderboard even after correcting the learning rate? I didn’t. Did you run it more than once?
I’ve run some initial tests with Radam vs Adam on Imagenette.
- I first reran the Adam baseline because of the glitch with learning rate that I detailed elsewhere [1]
%run train_imagenette.py --epochs 5 --bs 64 --lr 12e-3 --mixup 0
(note that the effective learning rate is 3e-3)
Results (10 runs): [86,85.4,84.4,85.2,84.8,85,85.6,85.4,85.4,86.4]
Mean: 85.3%
- Radam, learning rate 3e-2 (as in the OP’s article)
%run train_imagenette.py --epochs 5 --bs 64 --lr 12e-2 --mixup 0 --opt ‘radam’
(effective lr = 3e-2)
Results: [85.2,85.2,83.6,85.4,85.6, 86, 84.6, 84.6,82.8,85.4]
Mean: 84.8%
- I tried Radam with wd = 1e-3 instead of 1e-2, cout=1000 to be close to OP’s parameters (based on the Medium article).
Note that normally I specify cout=10, but OP didn’t do so. I don’t think it makes a difference (though losses are higher), but you never know.
Results: [84.2, 86.2, 83.2, 83.8,85.2, 85.2, 84.4,82.6,84.8,84.4]
Mean: 84.4%
Conclusion: I haven’t been able to get better results with RAdam than with Adam on Imagenette (128px) so far. I am able to get 86% on some of my best runs, but on average Radam is doing worse that Adam when running for 5 epochs.
[1] ImageNette/Woof Leaderboards - guidelines for proving new high scores?
Thanks for the testing Seb!
If you have time and aren’t paying for GPU, can you test with Ranger (RAdam + LookAhead) and 20 epochs?
Ranger/RAdam usually start a bit slower so I think the 20 epochs is the more interesting/definitive test overall. I got higher than the leaderboard with both, but now it’s unclear what the leaderboard ranking is with the whole GPU mixup.
I’ve been trying to do my testing on Salamander since Sunday, but every day for the past 3 days I keep getting pre-empted after 10-30 mins in, just as I’m getting the first runs going, and tired of wasting money like that.
1 Like
I wrote my Ranger results in your other thread.
(I switch to vastai when I want a break from Salamander and vice versa)
Yes, i tried different lr rates, several times, results was close.
It should be logs - will look at it again…
At my home box i train without fp16.
And i tried it on colab, with fp16, same results.
Will check it…
Hi @LessW2020,
Thank you for reporting back the results of your experiment! Glad to see that this summer largely benefited optimizers’ design
On my side, I haven’t yet been able to get improvements using only RAdam compared to Adam (I used a personal reimplementation of lr_find for those two so I guess I’m not likely to observe performance’s sensitivity to LR). But I’m going to give a try to Lookahead coupled with RAdam.
Besides, I was wondering if you had a specific idea about combining RAdam and Lookahead?
From my understanding, since Lookahead is just a wrapper class for another optimizer, I don’t see the need (at least in this implementation) of combining both in a single class. Something like:
optimizer = RAdam(model_params)
if lookahead_wrapper:
optimizer = Lookahead(optimizer, alpha=0.5, k=6)
would do just fine. But perhaps you have an idea for future improvements when combining both?
Thanks in advance!
Hi @fgfm,
You are correct - lookahead is a wrapper and will wrap any optimizer underneath (I show this in my article actually
The reasons I integrated lookahead and RAdam into a single class (Ranger) was:
1 - Ease of use/FastAI integration - to make it easy to integrate into FastAI (didn’t want to have the intermediation of lr pass through, as FastAI changes lr extensively via fit_one_cycle) and wasn’t sure how well that would be handled otherwise. Similarly, based on comments from my RAdam article, it was clear that people just wanted a simple plugin to test with.
2 - Future work - I am planning to test out an automated lr seeking code that adjusts based on the loss surface, and that wouldn’t be easy with the wrapper setup. One class makes it a lot easier to code and test.
3 - Minimal downside - From a theory standpoint, I’m hard pressed to explain why one would not want to use RAdam and LookAhead given their advancements (i.e. it’s very hard to see how they would perform worse than say plain Adam, and in most cases should perform better) so why not just put them into one class together.
Anyway, that’s why I bundled them together into Ranger. As I can get time/money to dev/test, I’ll integrate the lr seeker as well and see how that performs.
You can definitely use it as a wrapper and test out other underlying optimizers and if you find a better combo than RAdam+Lookahead, please post about it!
Best regards,
Less
It would be very interesting if you folks could also try Novograd:
4 Likes
Wow, thanks for the pointer to this paper. This looks very compelling as I like what they are doing with the gradient normalization.
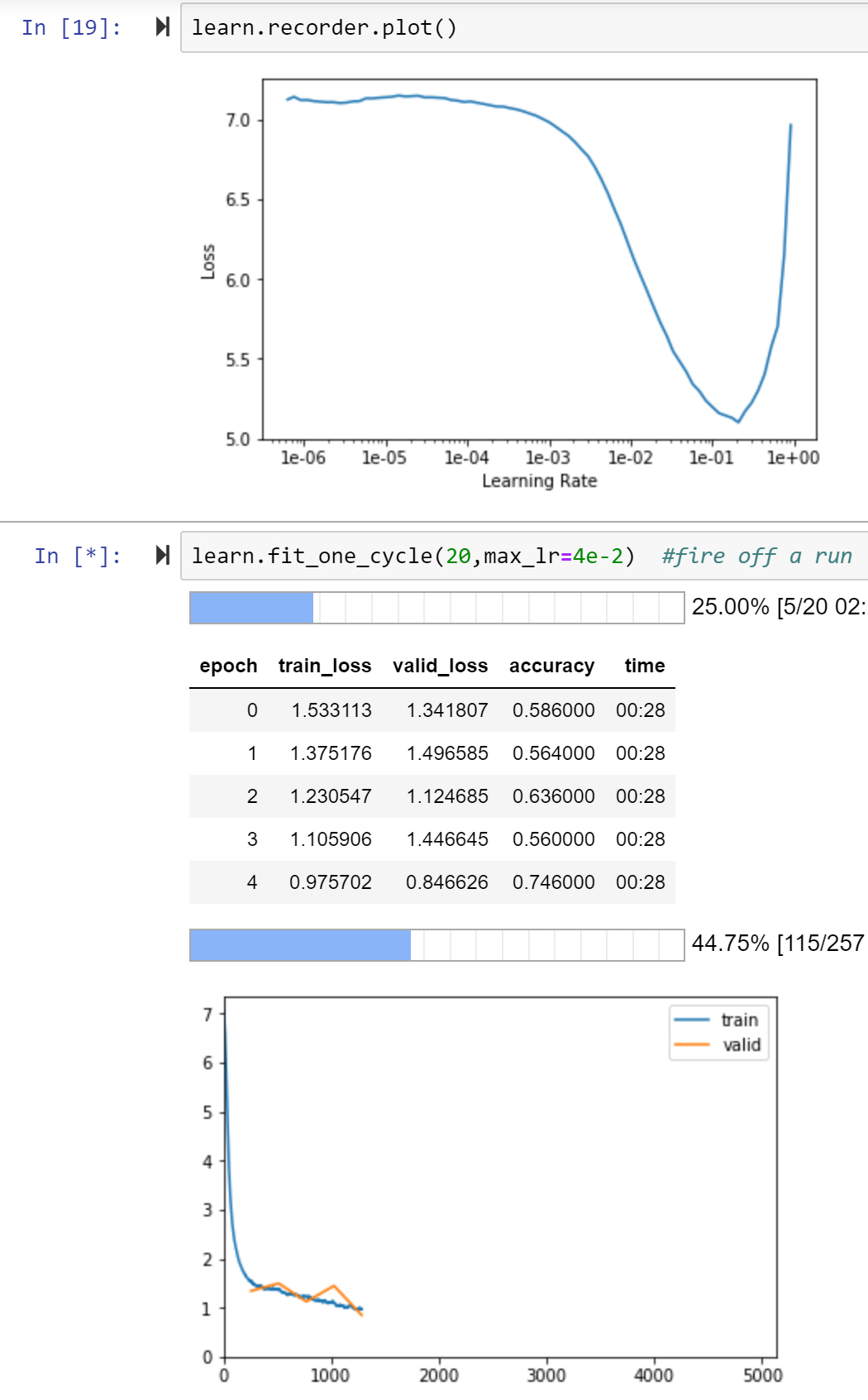
At risk of turning into a walking Optimizer since that’s all I’ve been working on lately, I’ve got it running now and fingers crossed I don’t get pre-empted will have some results in the next hour:
edit - 93.4% on first 20 epoch…so that’s quite competitive. Trying a range of lr now to get a better feel for it.
2 Likes