Hi all,
I’m very excited to introduce you to a paper by Liu, Jiang, He et al that I think will instantly improve your AI results (seriously) vs Adam.
I tested it on ImageNette and quickly got new high accuracy scores for the 5 and 20 epoch 128px leaderboard scores, so I know it works.
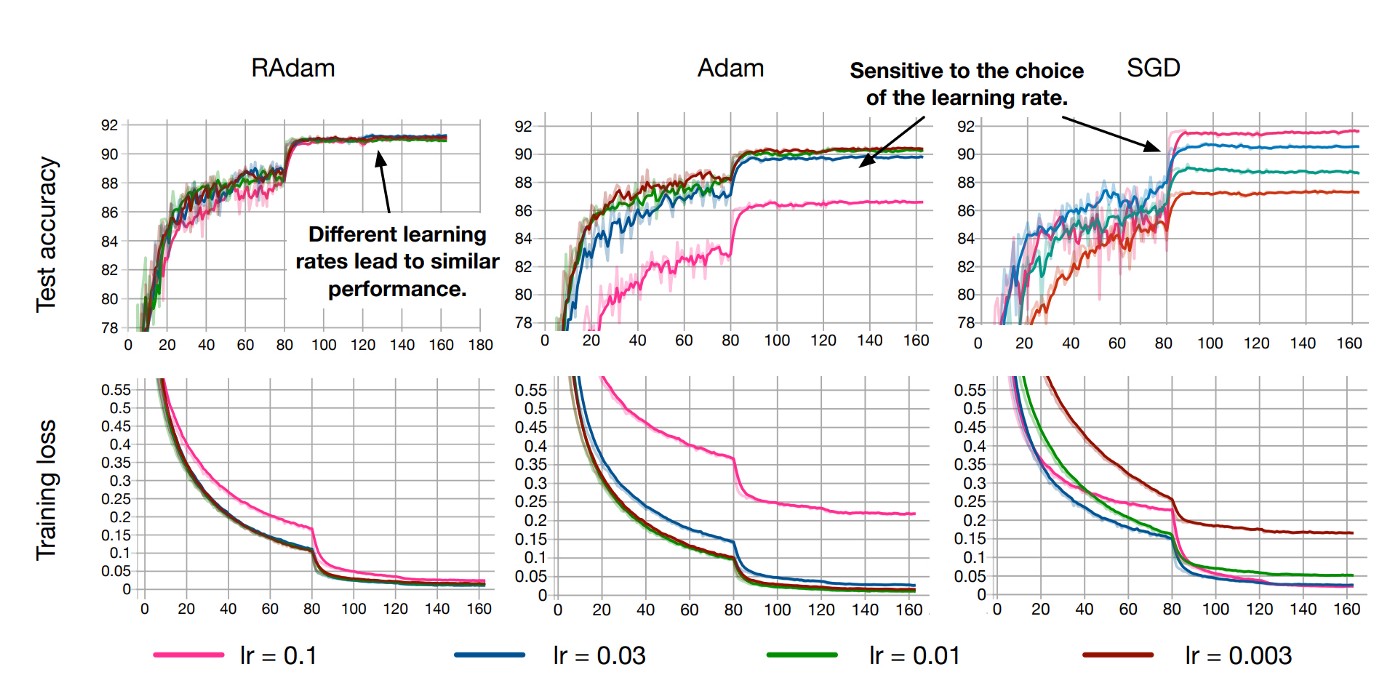
The simple summary - the authors investigated why all adaptive optimizers require a warmup and found it was a result of excessive variance of the adaptive momentum in the early stages. They then developed a dynamic algorithm to adjust the adaptive momentum based on the variance and show that with this, RAdam readily outperforms vanilla Adam with or without a warmup while providing much greater robustness to varying learning rates.
This quick image from their paper should get your interest:
I’ve written a complete summary and overview along with example of using in FastAI here:
Here’s the link the paper directly and more importantly to their github with the unassuming one word readme (“RAdam”). I would recommend jumping directly to their github and trying it out as it really appears to be new state of the art for optimizers now;
Paper:
I have to say after having tested a lot of papers this year, it seems that most over-promise and under-deliver on unseen datasets.
However, it appears RAdam delivers since I jumped to new high accuracy relative to the ImageNette leaderboard with it with minimal work other than plugging it in, and I’ve run a lot of tests trying to beat it with various papers before
Enjoy and please post any results if you test it out!
I would be careful when testing on Imagenette/Imagewoof
There is a lot of variance from run to run (especially after 5 epochs only), so I would run things more than once.
Ideally, I’d like to see mean accuracy, variance, sample size, and a good p value. I’m a bit rusty in stats, but I think you can use this calculator: https://www.medcalc.org/calc/comparison_of_means.php
If differences between accuracy means are too small, you could look at validation loss instead (less variance) if increasing sample size is too costly.
I would rerun the baseline (again, multiple runs) yourself, on your own machine, the same way you are running your new optimizer or model.
Jeremy’s baseline, for example, is run on 4 GPUs, which affects things (e.g. learning rate is modified IIRC). I don’t remember the details, but I remember that I was beating the baselines on Imagewoof just by rerunning them on 1 GPU.
Edit to add: Also, you are running with lr = 3e-2 when the original lr was 3e-3.
Thanks for sharing @LessW2020 - I would love to read your Medium article but as I don’t have a subscription its locked away from me. Is it possible to make it available as a PDF?
Hi @LessW2020. Thank you very much for sharing this. Could you share your ImageNette notebook where you conducted the experiments? It would be very helpful to start hacking around it.
Hi Seb,
Thanks for the feedback! For reference, I ran the 5 epoch multiple times with multiple beats, and also beat on the 20 epoch.
Now, that said, the bigger question I think is we really need to formulate a standard setup for the leaderboards.
i.e. what is the criterion to finalize a new high score entry b/c it’s very vague right now…obviously you need multiple runs but how many? 5, 10, 20? And are people really going to run 20 * 20 epochs(or whatever the required amount is) if they are paying for server time (like me?)
Also, 4 GPU really shouldn’t be the benchmark if GPU’s matter at all - in my mind it should not matter how many GPU but if it does…nearly everyone is running on one GPU, so not sure why that’s even listed given how impractical it is for most.
Anyway, let’s start a new thread on this b/c it keeps popping up that there is no real set of rules for how to verify things.
Hi Chris,
I thought they allowed free viewings (certain amount per month), maybe that changed for articles they recommend - anyway, here’s a link that will let you in!
Thanks very much @LessW2020 - yes they do allow a small number of free viewings, and typically I use them up pretty quickly, already long past my limit this month
Tried RAdam.
Now only on 5 epochs.
On imagenette, size 128 have small improvements.
On woof, same 128 have better results.
What i find - with RAdam you can take higher lr.
Also i check it with my custom model - it have improvements too.
Will try it on 20 epoch later.
And, by the way - i try script from examples on 1 GPUs and get same results as on leaderboard.
Hello I am new to deep learning and I just finished lesson 2 of the deep learning course.
I want to ask how can I test RAdam like you guys did? You provided their GitHub page but I don’t know what to do with that. I’m sorry if my question is too basic, but I greatly appreciate your help. I really want to learn.
Hi @minh - here’s a quick summary of how to use RAdam:
1 - copy the radam.py from the github to your local directory, ala nbs/dl1 where your notebooks are.
*(better but more complicated is to git clone it to your local drive and then reference the path… this way you are in sync but if you are working on a paid server such as Salamander I just copy the file over).
2 - In your notebook use:
from radam import RAdam #make RAdam available
optar = Partial(RAdam) #create a partial function to point to RAdam
learn = cnn_learner(data, models.xresnet50, opt_func=optar, metrics=error_rate) #when you create your learner, specify the new optimizer:
Now you have learner running RAdam
Hope that helps!
Hi @a_yasyrev,
Thanks for the testing feedback
Glad to hear RAdam is helping and also thanks for confirming 1GPU results are same as leaderboard 4 GPU.
Good luck with 20 epoch testing and please post results when you can.
Tried it on a tabular model for a running kaggle competition.
Didn’t work out for me, yet. I m using slice(lr), pct_start=0.2 on fit_one_cycle with the default optimizer. My results got worse when I tried RAdam with those settings. When I used the default params on fit_one_cycle with RAdam I got much better results. But they were still slightly below than using my original settings.
If we don’t need a warmup, I wonder if it means we need to adapt the one cycle learning rate scheduler.
Also, I had one case where my result was worse after upping the learning rate. It was some transfer learning on an image dataset. A bit anecdotal, but I wonder what people experienced in terms of results being independent from lr. It would be great to not have to worry about lr as much!
One other anecdotal result was that the learning rate finder curve was shifted to the right with RAdam.
I still want to run some tests on Imagenette with the modifications I suggested above, but that might have to wait until next week. Or maybe someone will run it before me.