I also tried removing the betas to see if just using defaults would work but didn’t change.
Anyway, I have to run for a bit so if anyone can debug that would be great. Otherwise I think I’ll rewrite Ranger to use @fgfm’s improvements and see if I can isolate it while doing that.
I am posting on the new v2 forum about how to implement the callbacks for our fit method
I’ll work on getting two versions of it for us for both libraries.
@LessW2020 I updated the function earlier with the proper format. One question I do have for this, how are we hoping to schedule the momentum? Eg should it be:
Anything else needed for the callback? If not, I’ll put in the PR so it’s easier for others to go ahead and use it? And then I’ll leave either of you, @LessW2020 or @Seb for the optimizers as those were your collaborations? (Or you may choose to wait for AutoOpt)
Re: optimizers - Ranger was my idea, but @rwightman and @fgfm have both coded up improved implementations. I’m hoping to have time to go through theirs and update mine and we can leverage the sync control that @fgfm mentioned earlier. The reason for integrating is of course to get ready for AutoOpt integration in the future.
That said…I spent several hours today on AutoOpt and hit issues with params computations between GPU and CPU…so the researcher/inventor behind it is working on it now ( Selçuk). But at least I’m getting a lot more familiar with the code behind it and how it works in more detail.
Note that Jeremy mentioned I should turn the summary post into an article on Medium, so I’m working on that now. Hopefully we’ll get some movie and book deals from that lol.
Got it! I’ll send in the PR and leave the optimizers to you guys
Good to hear that you’re making progress with AutoOpt! (I wonder if we should try the autoLR that’s floating on the forums… AutoLRFinder - #41 by aychang ) some more FFT!
Thanks a bunch @fgfm! I don’t have the notebook public right now, but I’m going to try and rewrite from scratch tomorrow anyway to integrate both your and @rwightman’s impl and maybe the issue will go away as part of that.
well, the lr finder didn’t really help.
In general it was suggesting way too aggressive, though I can’t fault the auto aspect. I think it’s more that our setup doesn’t go well with the lr finder concept in general.
I tried running the finder after each epoch, thinking it might let us tune epoch by epoch…but just ended up with .11 accuracy b/c it was nearly blowing it up.
The only time it did alright was on the very first analysis (i.e. clean network) as it suggested .005, which isn’t too far from our .004.
Otherwise, way too aggressive. As noted, that’s not a chart reading issue but rather I think Ranger, etc. doesn’t work that well with the lr find concept as well.
Anyway, thanks for the link to this - always good to keep trying new things and we’ll hit some winners from it.
Related - I read a paper last night on KSAC (Kernel Something Atrous Convolution). The concept was very cool and reminded me a bit of SSA. Basically in each layer, instead of having the kernel just run one pass (i.e. 3x3, step 1)…it goes 3x3, step 1, step 4, step 8) as an example.
So basically it’s scanning at a tight density and then a wider and wider perspective.
As a result it captures more long range interdependencies and they set a new SOTA for segmentation with it.
The code isn’t out yet and it will be in TF, but I think it’s worth checking out as it is similar in spirit to @Sebs SSA.
Hi @LessW2020, writer of the the auto lr finder here. Gotta say your Mish activation function looks very promising and results seem great!
I wanted to comment about the aggressive LR that you’re getting. Usually when the LR you’re getting from the finder is too high, it may be a good idea to increase the lr_diff param when running the model (increments of 5 might be good to try). This should generalize a little depending on the model and hopefully give some better results through out training.
It would also be interesting see the loss and learning rate plots to see why such aggressive learning rates were given in the first place.
Please let me know if you have any questions or suggestions/feedback on any of this!
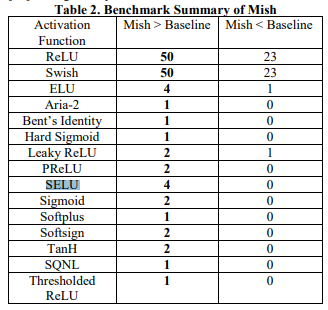
@Jumonji this is taken from page 4 of the Mish paper, where baseline is the activation function :
In total, at the time of this paper publication, Mish
activation function has been validated on more than 70
benchmarks in problems ranging from Image
Classification, Image Segmentation and Generative
Models against a total of 15 activation functions on
challenging datasets including CIFAR-10, CIFAR-100,
CalTech-256 and ASL to name a few. Table 2 provides a
summary of these results.
Actually that chart is the only data presented regarding SELU and it’s very unclear to me what it’s actually saying and what the significance is. I’m a fan of SELU because if its self-normalizing properties, and I wonder how Mish compares in that regard. https://towardsdatascience.com/gentle-introduction-to-selus-b19943068cd9
I hate this trend of binary comparisons against “baseline” where you get zero information about how the test was run, whether other meta parameters were optimized or were just the best ones for the target function that are forced onto the baselines, etc. Either sloppy research, or sloppy writing.
Hi all,
I wrote a new article detailing our experience with the ImageWoof 5 epoch beat in a medium article here:
On other news, the researcher behind AutoOpt (Selcuk) fixed the GPU/CPU conflict bug I found and is working on one other bug I entered now.
Thus, I’m hopeful we may have a testable AutoOpt as early as next week!
Hi @aychang - thanks very much for the post and info!
one quick comment - Mish is @Diganta invention, I’m just a big proponent of it after having tested a lot of activation functions this entire year
Thanks for the info on using the lr_diff option. I did test from 5 - 25 and found that around 20 it started getting a lot closer. However, ultimately it’s still too aggressive but while eating lunch, I think I understand why.
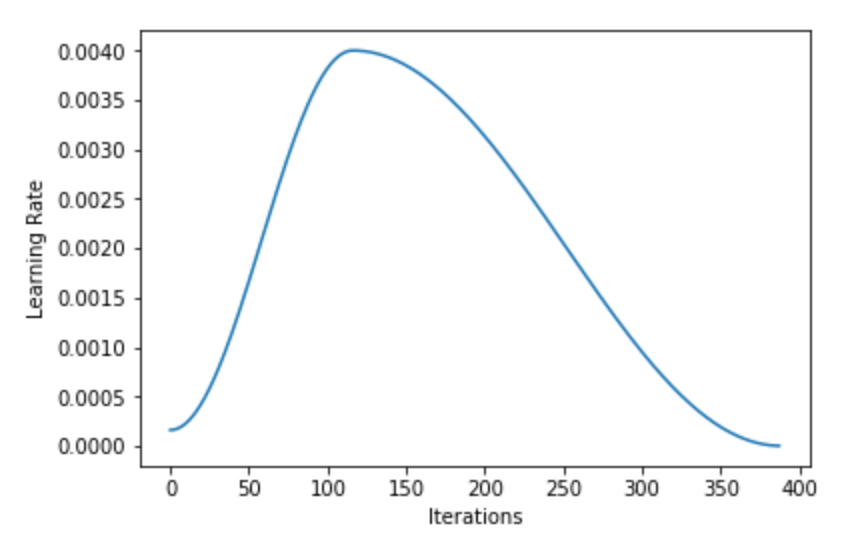
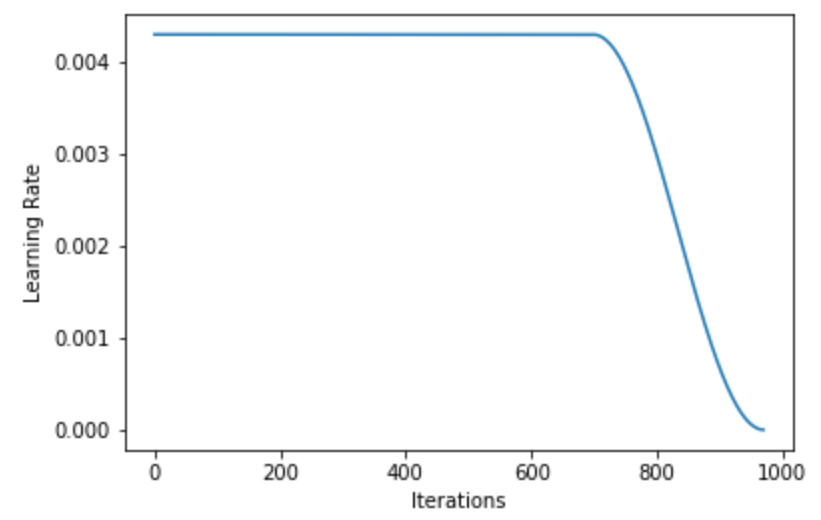
Basically, the lr finder as we use it with Fit_One_Cycle is really providing the max learning rate. The actual average rate used is arguably half of that, and it only runs with the actual suggested rate for maybe 2-3% of the entire training set?
By contrast, with our setup of flat line for 72%…we are running that LR most of the training.
Thus, a better comparison might be to take the suggest lr and cut it in half or so to get it somewhat in range.
I think viewing the lr curves drives the difference home at how little time the lr suggested is actually run in normal style one_cycle training versus look how long during our flat+
We’re probably running 20x, 40x+ longer at the suggested rate vs one cycle.
Anyway, I think that’s likely the root issue here. I think your finder is performing great in terms of picking the lr based on the graph, the issue I think is just the massive difference between one cycle time spent at the lr vs flat cosine.
I suppose mathematically computing the true differerence and then multiplying that by the suggested learning rate could result in an optimal compute for it?
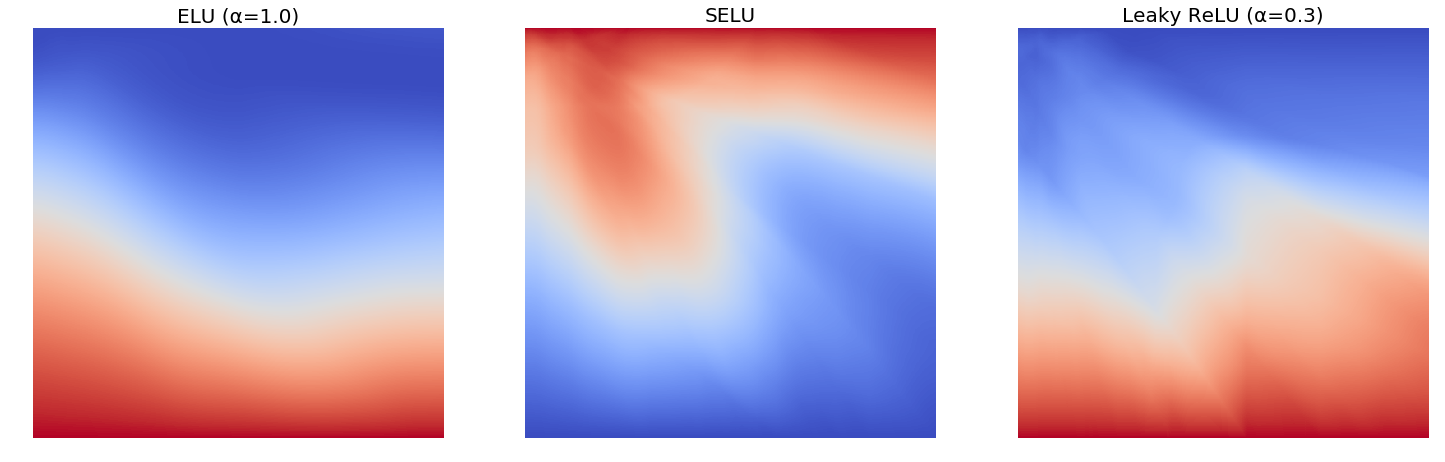
@Jumonji I really appreciate your comments and I take them as constructive feedback, but just to point out, the paper of Mish is just the seminal version 1, I haven’t added all the analysis results to it yet which includes Edge of Chaos Analysis, Rate of Convergence of Covariance analysis and additional benchmarks. Also just an insight into comparison of Mish to SELU, these are the output landscapes that a randomly initialized 5 layered network generated. As you can see SELU has sharp transitions in the landscape as compared to Mish. Smoother landscapes result in easier optimization and thus better generalization.
 (Or you may choose to wait for AutoOpt)
(Or you may choose to wait for AutoOpt)