All caught up. Great job @TomB! I definitely need to finish working on the Matrix Calculus so I can better understand the math behind what you’re successfully doing. But again great job!!!
wow @TomB, amazing work!
I looked at the derivatives notebook.
I love how the derivatives could allow you to reuse intermediate outputs through (1-tsp^2) and (1-exp(-sp). Though I’m not sure why you can’t stash Softplus(inp) and avoid recalculating it.
Otherwise, does it help that (1 - 1/(1+exp(x))) = 1/(1+exp(-x)) ?
You could therefore use 1+exp(x) or 1+exp(-x) depending on the sign of x, maybe it would be more stable???
Can you explain why you need the second derivative?
1 Like
I could. In part I was just wanting to get a baseline implementation to verify and to profile against (the CUDA profiler supports baselines). One slight issue with collecting intermediates is that it will involve extra memory allocations and extra writes by the CUDA kernel. The allocations likely won’t matter, though the writes may actually slow things down overall. In general GPU programming is memory bound due to the relatively slow memory (the relative being key there, it’s very fast, much faster than normal CPU memory, but there’s even more compute power, I’ve seen a figure of 10 FLOPS to every Memory OP used).
Ah, yes, it probably does. That might be what PyTorch is using to do the 1-exp(-Y) trick I was unsure about. Or at least another such trick.
I did consider stashing softplus for the initial implementation, but I was a bit stuck then on how to get the exp(x)+1 needed in the final derivative. But that was when I was just calculating the whole derivative, I hadn’t figured out how to get sympy to do the partial derivatives of functions yet, or read some more calculus. So with that knowledge I might be able to avoid that as it was coming from sympy’s softplus derivative of 1/exp(x)+1. That equality certainly might help me there, thanks.
I’ll definitely look at trying such things, but ideal performance is actually more of a balance between compute and memory on GPUs so it may not actually help. Certainly the current way where in the backwards I go through the whole calculation forward to then go back through it seems unlikely to be the best way, it was just easy, not need to store an intermediate, and wasn’t sure I could do it all from the output which would be just as easy as input (and allow inplace forward)…
I was quite surprised how well it performed. Though that might link back to the memory vs. compute thing. The other side of it being that if too many of your (many parallel) threads are waiting for memory then cores will sit idle, so having enough compute work to be scheduled while other blocks are awaiting data is important (blocks being the logical division of data, you say how many blocks will run and use the current block index to do the right piece of work and the GPU schedules parallel threads as needed to process all blocks, sort of, a little more complex than that but that’s the general idea, and the other complexities are more for optimisation).
If people can see better ways to calculate but don’t want to dive in to the C++ then by all means modify the Derivatives notebook and I’ll look to implement. You should run into all the same stability issues using basic torch ops (e.g. exp as oppossed to softplus which is stabilised). The C++ side took me a lot less time than the derivatives side. Think all the pieces to work off intermediates and try it out through Autograd functions should be in there.
I’m limited to only 4 tensor parameters (due to the methods I use to run it, a lot of work to change that). So 2 spare parameters in forward but only one in backward. Though I could do inplace operations. I think this is not an option for the input in certain networks where the input gradient is used elsewhere, hence it’s optional in e.g. RelU (I’ll look to implement the same inplace option). The same might also apply to grad_out in backward. PyTorch should show these errors in the autograd functions if you modify them to overwrite something you shouldn’t and use in a network. But otherwise I should be able to take an intermediate and use it for the result. So I could have two intermediates, but it may not perform great. Using an intermediate in place of the input in backward though seems a definite possibility (though it may slow down forward a bit having to record it)
Not really, no. I’m pretty sure in general you don’t. Standard training works fine without it, but for certain more advanced methods you use it. On top of normal backprop with the first derivative you can set your gradients to themselves collect gradients (setting requires_grad on the gradients you put through the backward). I think it’s for things like intelligent hyper-parameter control across training based on the changes in the loss gradients through training.
Oh, and looks like I edited the overall dervative out of that notebook, I’ve added it back in locally, but I’ll probably wait to figure notebook stripping out before updating that (at least for a minor thing). I posted it somewhere above but here it is again:
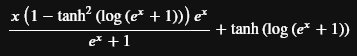
(The exp(x)+1 in the denominator being the thing I had issues with, log(exp(x)+1) I can deal with through the linear approximation above a threshold, but can’t apply that to just exp(x), but that equality above might help me use that 1-exp(-Y) trick here).
3 Likes
3 Likes
I added performance tests for all data types and got:
Profiling over 100 runs after 10 warmup runs.
Profiling on GeForce RTX 2070
Testing on torch.float16:
relu_fwd: 223.6µs ± 1.967µs (221.6µs - 241.3µs)
relu_bwd: 313.6µs ± 1.739µs (310.4µs - 316.7µs)
softplus_fwd: 294.4µs ± 977.4ns (293.0µs - 301.1µs)
softplus_bwd: 420.5µs ± 653.6ns (418.6µs - 421.6µs)
mish_pt_fwd: 663.5µs ± 7.623µs (655.7µs - 682.9µs)
mish_pt_bwd: 1.140ms ± 11.39µs (1.128ms - 1.171ms)
mish_cuda_fwd: 267.5µs ± 660.7ns (266.0µs - 269.4µs)
mish_cuda_bwd: 344.6µs ± 1.204µs (342.6µs - 346.8µs)
Testing on torch.float32:
relu_fwd: 234.9µs ± 518.5ns (234.0µs - 237.3µs)
relu_bwd: 420.1µs ± 702.7ns (418.9µs - 425.6µs)
softplus_fwd: 255.1µs ± 870.0ns (253.7µs - 260.2µs)
softplus_bwd: 420.6µs ± 853.0ns (419.1µs - 426.8µs)
mish_pt_fwd: 797.2µs ± 1.305µs (795.0µs - 804.8µs)
mish_pt_bwd: 1.691ms ± 1.219µs (1.688ms - 1.694ms)
mish_cuda_fwd: 281.9µs ± 687.5ns (280.2µs - 283.4µs)
mish_cuda_bwd: 494.8µs ± 1.159µs (492.7µs - 499.7µs)
Testing on torch.float64:
relu_fwd: 450.5µs ± 1.052µs (449.1µs - 455.3µs)
relu_bwd: 834.6µs ± 772.8ns (833.0µs - 839.8µs)
softplus_fwd: 6.334ms ± 840.8ns (6.333ms - 6.341ms)
softplus_bwd: 2.344ms ± 877.0ns (2.342ms - 2.349ms)
mish_pt_fwd: 10.06ms ± 717.7ns (10.06ms - 10.07ms)
mish_pt_bwd: 4.884ms ± 1.365µs (4.882ms - 4.890ms)
mish_cuda_fwd: 8.941ms ± 590.5ns (8.940ms - 8.944ms)
mish_cuda_bwd: 10.86ms ± 847.8ns (10.86ms - 10.86ms)
So performs well on half-precision but float64 is not good. Softplus similarly drops a lot in performance on float64. I’d guess relu is so good here as it doesn’t actually do any maths, it’s just a inp.where(inp<0, 0). It could also be that relu is from nVidia libs while softplus is from PyTorch and PyTorch doesn’t do float64 well. Though I think that double precision maths is a lot slower on GPUs.
Interesting that it seems to be faster than softplus on float16. Guess it might be using an older, less optimised PyTorch method to calculate (there’s a lot of stuff that hasn’t been updated much).
I also tried using the softplus as an intermediate (it’s in the deriv2 branch of the repo). However, I can’t see how to do the derivative without the input, as the derviative depends on it due to the multplication by the input. So I need both the input and the intermediate for the backward. The performance is:
Testing on torch.float16:
mish_cuda_fwd: 285.8µs ± 811.9ns (284.2µs - 288.4µs)
mish_cuda_bwd: 323.8µs ± 2.162µs (320.2µs - 328.3µs)
Testing on torch.float32:
mish_cuda_fwd: 357.5µs ± 1.218µs (355.5µs - 363.6µs)
mish_cuda_bwd: 530.2µs ± 1.845µs (527.7µs - 538.5µs)
Testing on torch.float64:
mish_cuda_fwd: 8.943ms ± 826.8ns (8.942ms - 8.947ms)
mish_cuda_bwd: 5.121ms ± 964.3ns (5.119ms - 5.127ms)
So on float32 it’s a fair bit slower for both forward and backward, while for float16 it’s slower on forward and the same or maybe a bit faster on backward (would want more runs to confirm). On float64 it’s a lot faster on backward. This would support the maths performance on float64 being the issue and I’d guess half does better because there’s less memory pressure.
I could perhaps optimise the memory access and improve these results, but then I’d presumably be able to optimise the memory access of the non-intermediate version as well.
So seems like the current method of recaclulating the entire forward in the backward is best overall. Though intermediates do help with double I don’t think it’s ever really used due to the performance so not sure this justifies multiple variants. Thouigh maybe if the half improvement is real as well, though it’s fairly small. The intermediates method also means holding another tensor around between forward and backward that will likely increase memory usage (depending if it’s at peak usage times).
Needing the input for the derivative also means I can’t see how to work from the output alone and so allow the op to be inplace, which would be nice. Unless someone can see something I’m missing, which is entirely possible.
2 Likes
Nice article. Looks to be coming from a statisticians perspective. perhaps over-emphasing technical matters compared to actual scientific practice in places. But looks like a great, detailed treatment of it.
Oh, when looking to calculate CIs I did note that scipy.stats.bayes_mvs does Bayesian confidence intervals, no need to specify a distribution or anything, just data and confidence level. Could be interesting.
1 Like
Hi all,
I finally had some time to do some deep learning stuff this afternoon and was able to write setup and test a new Ranger modification, RangerQH.
For at least one 80 epoch run I hit 87.4% with it vs the 86.2% current leaderboard (RangerQH + Res2NetPlus)…I got 87% with our MXresNet.
That’s only one run each of course, but the training on it is very stable and I’m still learning how to best tune it.
It also almost tied for the 20 epoch…so it’s a bit slower than Ranger but the stability epoch to epoch is much better.
QH = This is Quasi-Hyperbolic Momentum, introduced in this paper.
Summary:
Quasi Hyperbolic Momentum introduces an “immediate discount factor” v, or nus in the param tuple nus = (.7, 1.0).
This v decouples the momentum buffers discount factor (Beta) from the current gradients contribution (1-vBeta).
By comparison, momentum tightly binds the discount factor and the current gradients contribution.
Effectively, QHM up-weights the current unbiased gradient vs regular Adam momemtum.
I’ve put the RangerQH in the Ranger repository:
More to come as I have time, but looks like we’ll be able to beat the 80 epoch record in the near future 
9 Likes
Wow you just keep going!
1 Like
lol and thanks for the kind words @ilovescience
one update - 88.20% on first 80 epoch run with Cutmix and RangerQH (was using mixup and none before). (vs 86.2% leaderboard).
(these 80 epochs take forever so pls no comments about why not 5 runs yet lol). Still tuning but I’m really impressed with RangerQH so far.
2 Likes
I actually had a question about these leaderboards.
I have found a published optimizer and I want to test it. What would be the appropriate leaderboards and settings to test?
Right now, I tested it on Imagenette 5-epoch 5-runs with flat_and_anneal but it didn’t do so well compared to Ranger. However, I realize that the flat_and_anneal settings were more specific to Ranger so now I am going to compare the two optimizers with default one_cycle settings. I am using mxresnet.
Any comments on whether this would be the correct way of doing this and how I should report my results?
Also a separate note. I tried using Ranger in two Kaggle competitions without success. However, I was using pretrained EfficientNets. This makes me wonder if your results are specific to ResNet-like architectures. This would be something to look into, and something I would be interesting in playing around with.
Also, in general, developing an optimizer that works nicely with EfficientNets and maybe even makes it easier to train them would be amazing. EfficientNets are somewhat hard to train compared to ResNets but they are small in size but you can still get a lot of performance out of them.
You can just do 5 runs and record each run. Average them for the final score and compute the std deviation and post ![]()
Re: flat and anneal - you can try any variation of annealing. We didn’t see good results with Ranger or most of the other optimizers with fit one cycle - Adam seems to do the best on that though.
Re: efficientnet - what impl are youu running? I’ll try and set it up and see how it does with RangerQH.
For reference, with Ranger, you may have to experiment with learning rates for that architecture. Generally each architecture requires some lr tuning in general with a new optimizer.
Good luck and look forward to any results you get!
1 Like
Thanks for the information.
For the EfficientNets I have used B0 and B4. I would start with B0 because it’s the smallest and therefore probably faster to train.
Is this for Imagewoof? Because I am getting decent results on Imagenette with Ranger (one 5-epoch run got 87.4% accuracy)
Hi - yes I’m talking about ImageWoof and 80 epochs above.
87 is pretty good start for 5 epoch nette though.
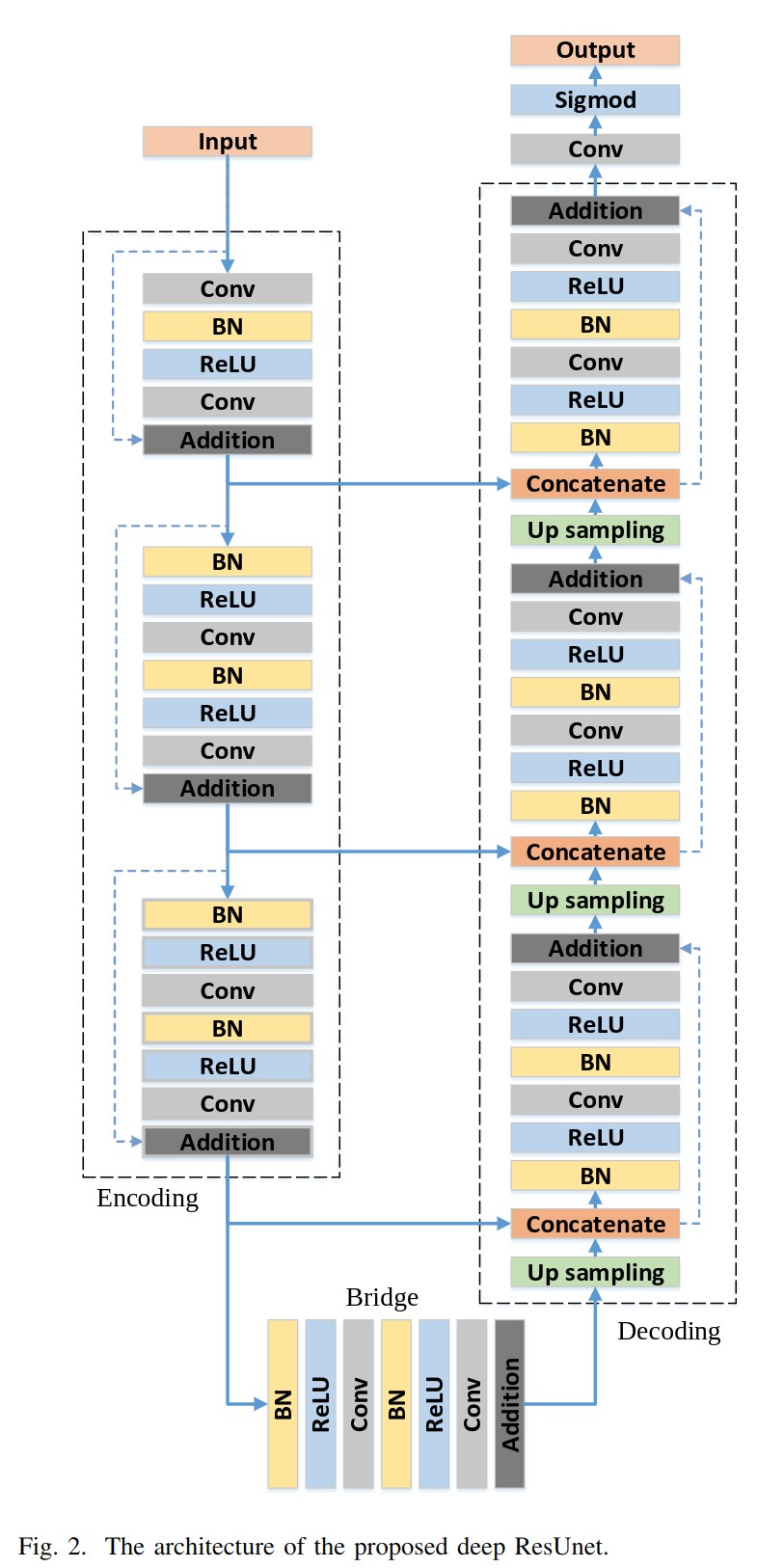
Did my first real run of Mish (hadn’t really tried it before writing the CUDA version). It’s a segmentation kaggle comp (so can’t share full code). Using my own implementation of a UNet with residuals based on road extraction paper, which uses the pre-activation BN-Act-Conv ordering suggested by He et al, so this architecture. Another key difference from the fastai unet is that it actually propagates gradients through the ‘cross connections’ (connections between down and up paths) whereas fastai detaches the hooked downward activations. Not really sure what the original Unet paper is proposing here (doesnt give much detail), and whether the difference in fastai from typical implementations which don’t detach is based on testing or what. Need to do some specific experiments here.
Not a clear win on model performance (compared with all the same but Relu and a bit lower LR based on lr_find diffs, just AdamW one-cycle). Validation loss (just using BCE, so not the best loss for it, need to look at incorporating a better loss):

Dice coefficient on positives only (i.e. excluding empty, so more discerning than standard dice where the negatives are all 0/1, on this comp predicting all empty gives a dice of ~0.85 due to negatives):

Overall dice:
![]()
These just being off a threshold of 0.5 rather than a tuned threshold (and probably some exclusion of predictions of just a few pixels) as you’d use for final predictions.
Notably though it matched RelU so seems like the implementation is OK and 40K batches in basically the same time.
And a comparison with a resnet18 based fastai unet with RelU on training loss:
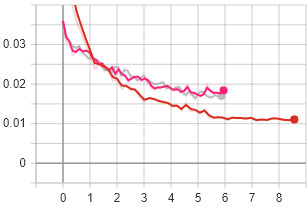
So, you can see the ResUnet doesn’t do as well as the pre-trained resnet but both trains faster (same number of epochs in 6 vs. 8.5 hrs) and learns much more quickly at the start. Also manages a batch size of 20 with the ResUnet vs. 16 with the resnet18 (even with the non-detached cross-connections).
1 Like
Which implementation are you using? Looking to try it out. I looked around your repos a bit and found the one based on the fastai v2 notebook stuff (but looks like no other v2 dependencies). Is that the one you currently use? Is it largely following the lukemelas PyTorch version, with a few tweaks (mostly from original google impl) where cited?
I see the lukemelas one is in fastai now too (just depending on the original package).
I have also been using the Luke Melas implementation.
1 Like
Ok looks like a new record for Woof 80 epoch, 128 px:

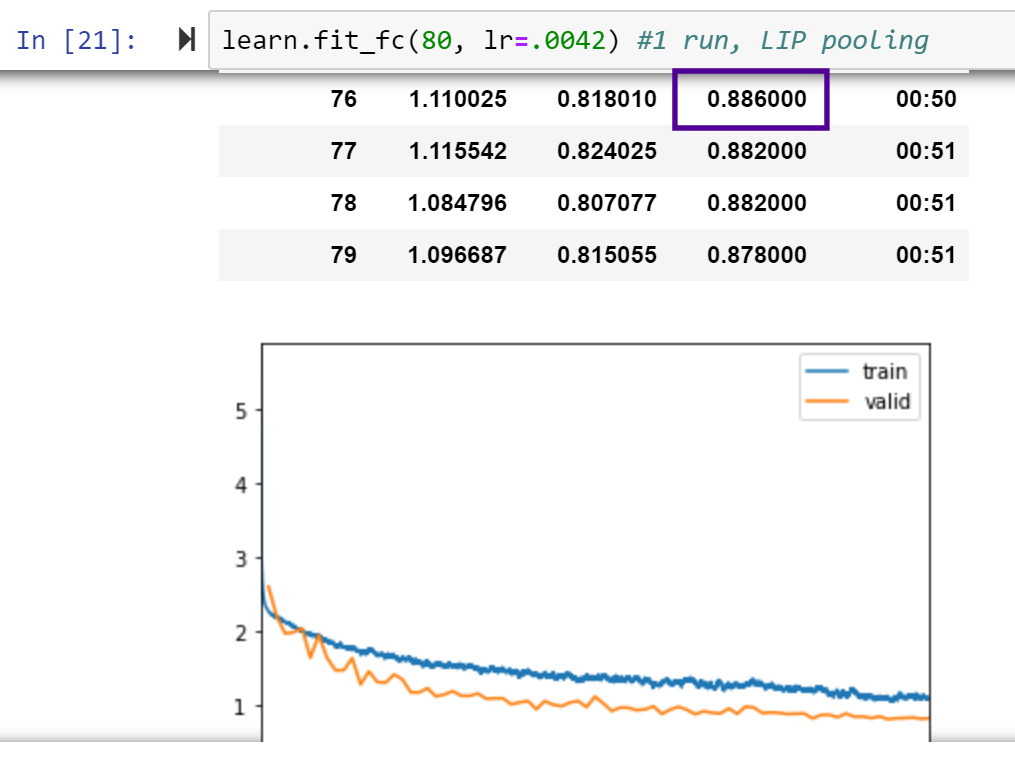
{kind=link}
I used RangerQH, Res2NetPlus (Mish, reversed BN/Mish order) with an initial LIP pooling layer, and … cutmix!
I tried to run our original MXResNet with the initial LIP pooling but it goes nan about 50% of the way in…
anyway, looks like another record - I’m going to continue working with RangerQH as I have time, b/c still feels like I haven’t fully tuned it.
8 Likes