I think I figured what is up : I need to point ImageDataBunch to ‘datasets/dogs-vs-cats’, not ‘datasets/dogs-vs-cats/train’. Otherwise ‘test1’ is not resolved (likely it is just one level up). So perhaps should have been
data = ImageDataBunch.from_name_re(path='datasets/dogs-vs-cats',
fnames=fnames,
pat=r"/(dog|cat)\.\d+\.jpg$",
ds_tfms=get_transforms(),
size=224,
bs=BATCH_SIZE,
test='test1')
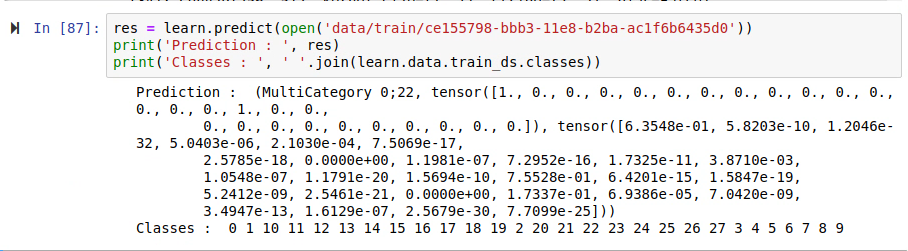
I am working on same problem as you were and was confused by the label ordering as well for couple of days and since the Id of the image is not persisted in the ImageDataBunch(only the image is) there was no easy way to correlate the Id, image and the prediction. Because of that I was starting to predict the images one by one, at that time I realized my assumption of the target classes being in sequential order is wrong(confirming what @sgugger hinted to ). Even though our target classes(0-27) are numeric they are categorized and the order of the classes is not in numeric order. Below is a specific example. Hope it helps to clarify things.
@sgugger
Are there any news regarding that? I’m also struggling with trying to get predictions on a DataFrame after loading a saved Learner.
The problem with learn.model(x) is that it doesn’t run all the added logic of get_preds (_loss_func2activ etc.)
I’m talking about predicting more than one item, using a loaded Learner.
Currently, data is empty (loaded with load_empty()) as in the tutorials.
All the examples and tutorials talk about predicting one item only, is there any way to get predictions on multiple objects without calling .predict()n times or implementing get_preds() on my own?
Thanks
The message I replied to is:
For now there is no script for this, but you can apply your model to a new object by calling learn.model(x) (just make sure x is on a the same device as the model).
Both Learner.get_preds and basic_train.get_preds expect to get a DatasetType (train, validation or test) or DataLoader and it works with losses etc. .
I’m not in the training phase, I’m after training and I no longer have a Learner with train, validation and test datasets. I saved the model to the disk.
Now I’m loading the model from scratch, as described in the tutorials, and I have only 1 DataFrame:
How do I proceed from here to predict the rows in df?
I can’t create a DataBunch as I don’t have train, valid or test data. I don’t have any labels in this stage too so all the label_from methods won’t work either.
The only two ways I found to work are:
call Learner.predict() for each row in df
Duplicate the code in get_preds, remove all the validation code and all loss related code.
But why don’t you put all your data in an TabularItemList.from_df(...), no splitting and a constant label like the ones you had on your training, then create a dataloader from this and put it inside your empty data.test_dl?
That way you’ll be able to call learn.get_preds
Will try that, thanks.
Just sharing my opinion, It still feels like a workaround.
Creating fake labels means I need to somewhere save how my labels looked like, and then create fake ones according to that, when in reality I don’t have a reason to create fake labels as I’m not training (Learn.predict() works without labels).
In addition, changing the empty databunch’s test_dl to a new one after it was already created also feels weird, but there is no option to do it otherwise as when loading the model it requires a DataBunch while I have no data to evaluate yet.
If you are interested in changing it, and/or have a possible plan to change this behaviour for the better, I can assist with the PR
I believe that it is very necessary to run prediction on multiple inputs rather than just one. I’m facing the same problem (on computer vision) and found several similar topics.
@sgugger
Tried your suggestion, can’t get this to work as well.
There is some private member called codes appearing half magically after applying the TabularProcessor, which I can’t understand when and why is it applied.
This causes codes to be not defined on the TabularList when get() is called.
This is my code:
constant_label = np.zeros(clf.data.c) if is_multilabel else 1
data = TabularList.from_df(x_test, cat_vars, cont_vars).label_const(constant_label)
data_loader = DataLoader(data, batch_size=64, num_workers=defaults.cpus) # have to duplicate code from DataBunch.create because of the workaround
clf.data.test_dl = data_loader
res = clf.get_preds(DatasetType.Test)
Stacktrace:
AttributeError: Traceback (most recent call last):
File "/home/ronyl/project/venv/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 138, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "/home/ronyl/project/venv/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 138, in <listcomp>
samples = collate_fn([dataset[i] for i in batch_indices])
File "/home/ronyl/project/venv/lib/python3.6/site-packages/fastai/data_block.py", line 480, in __getitem__
if self.item is None: x,y = self.x[idxs],self.y[idxs]
File "/home/ronyl/project/venv/lib/python3.6/site-packages/fastai/data_block.py", line 92, in __getitem__
if isinstance(try_int(idxs), int): return self.get(idxs)
File "/home/ronyl/project/venv/lib/python3.6/site-packages/fastai/tabular/data.py", line 120, in get
codes = [] if self.codes is None else self.codes[o]
AttributeError: 'TabularList' object has no attribute 'codes'
How should I do that?
What do you mean load the DataBunch so that it has the state of the processors?
It’s really unclear, the process I talked about is in the TabluarList level and not the bunch’s level.
If you have a working example for that workaround, I think it will benefit all of us
Use the tutorial on inference mode to know how to save the inner state of your DataBunch (from your training set) and then load it again with no data. Than add to that object your test_dl before running get_preds and you should be good.
@sgugger
I was using it all along, it doesn’t work the way you say it should work.
My DataBunch has the processors, I even use the same DataBunch I trained with (without saving and loading, right after training) and it doesn’t work.
The problem, from what I can see, is that the TabularList object I create, as I said, has the get() method which uses the self.codes member (line 120 @ tabular/data.py).
This member is never set because processor.process() is never called for the test TabularList I create, if I’m not wrong.
I created a sample code we can work with that illustrates the problem, here it goes:
import numpy as np
import pandas as pd
from fastai import Learner, DatasetType, DataLoader, defaults
from fastai.tabular import *
from fastai.metrics import *
from fastai.callbacks import EarlyStoppingCallback, SaveModelCallback
x = np.random.rand(1000,10)
y = np.random.rand(1000, 4).argmax(1)
columns = ['cont{}'.format(i) for i in range(10)]
x_df = pd.DataFrame(x, columns=columns)
# let's train a classifier
data :TabularDataBunch = (TabularList.from_df(x_df, cat_names=[], cont_names=columns)
.random_split_by_pct(valid_pct=0.2)
.label_from_list(y)
.databunch())
clf = tabular_learner(data=data, emb_drop=0, layers=[50], ps=[0.4], use_bn=True, metrics=[accuracy])
clf.fit_one_cycle(cyc_len=25, max_lr=0.1, div_factor=25)
# now let's get predictions for multiple rows
x_test = x_df.copy()
constant_label = 1
data = TabularList.from_df(x_test, [], columns).label_const(constant_label)
test_data_loader = DataLoader(data, batch_size=64, num_workers=defaults.cpus)
clf.data.test_dl = test_data_loader
res = clf.get_preds(DatasetType.Test) # same attribute error with self.codes here