Oh it is because the post is in Part1_V3 group and you don’t have access to. Sorry
I quote it here:
I haven’t played with tabular module yet in fastaiV1 but I guess it has similar function as add_test_df ?
Oh it is because the post is in Part1_V3 group and you don’t have access to. Sorry
I quote it here:
I haven’t played with tabular module yet in fastaiV1 but I guess it has similar function as add_test_df ?
It’s going to be add_test in this case, where you can put your TabularList.from_df(...) for the test dataframe.
Edit: the inference tutorial had been update to show this.
In the case of a tabular learner on a regression problem with a test set added during data bunch creation, what are the values in the tuples returned? The code says:
"Tuple of predictions and targets, and optional losses (if `loss_func`) using `dl`, max batches `n_batch`."
So, using Rosmann as an example, what are the tensors returned by get_preds
preds = learn.get_preds(ds_type=DatasetType.Test)
preds
[tensor([[ 8.3814],
[ 8.9268],
[ 9.1673],
...,
[ 8.7692],
[10.0370],
[ 8.8672]]),
tensor([2.1998, 2.1998, 2.1998, ..., 2.1998, 2.1998, 2.1998])]
The first tensor contains your predictions, the second your targets (dummy targets since you’re using the test set, which is why you have the same thing all the time).
TabularList does not have the load_empty method. Don’t know how to add_test the data without creating the whole dataset from scratch.
LabelList has the load_empty method, but does not have the add_test method, conversly LabelListS has the add_test but not the load_empty.
I am confused…
My bad, it has been fixed. Now both have both methods.
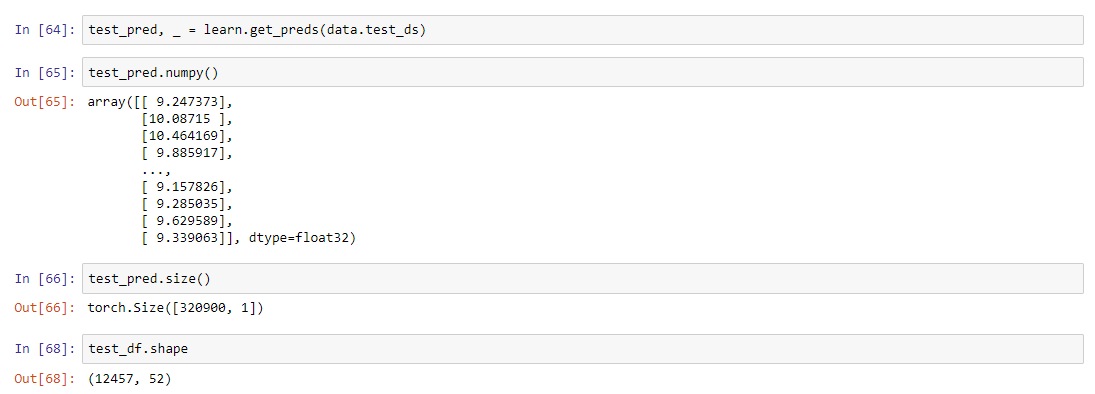
Following up on your answer to shaun1, I tried to make predictions on the bulldozers dataset using the rossmann code. However, the first tensor (which contains the predictions) appears to have many more rows compared to the test dataframe i.e. expect 12457 rows but got 320900 instead. Am I interpreting it wrongly or does my mistake lie somewhere else?
Normally get_preds takes a DatasetType now, not a dataset directly. Which version of fastai are you using?
I am using 1.0.38. It seems like I have given it an invalid input, how should I get the predictions instead? I could not figure it out from the documentation. Thanks in advance!
Like I said, pass a DatasetType, like DatasetType.Test for test.
I created a language model using custom data and saved the model to disk. I was able to call learn.predict() in the same session and get predicted words/sentences. However, in a new session, after initializing the learning and loading my saved model, when I call learn.predict(), I got the following error:
learn.predict('New computer keyboard', n_words=50)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-9-6b0b245e79d0> in <module>
----> 1 learn.predict('New computer keyboard')
~/fastai/fastai/text/learner.py in predict(self, text, n_words, no_unk, temperature, min_p)
93 self.model.reset()
94 for _ in progress_bar(range(n_words), leave=False):
---> 95 xb, yb = self.data.one_item(text)
96 xb = xb.view(-1,1)
97 res = self.pred_batch(batch=(xb,yb))[0][-1]
~/fastai/fastai/basic_data.py in one_item(self, item, detach, denorm)
153 "Get `item` into a batch. Optionally `detach` and `denorm`."
154 ds = self.single_ds
--> 155 with ds.set_item(item):
156 return self.one_batch(ds_type=DatasetType.Single, detach=detach, denorm=denorm)
157
/net/vaosl01/opt/NFS/su0/anaconda3/envs/mer/lib/python3.7/contextlib.py in __enter__(self)
110 del self.args, self.kwds, self.func
111 try:
--> 112 return next(self.gen)
113 except StopIteration:
114 raise RuntimeError("generator didn't yield") from None
~/fastai/fastai/data_block.py in set_item(self, item)
493 def set_item(self,item):
494 "For inference, will briefly replace the dataset with one that only contains `item`."
--> 495 self.item = self.x.process_one(item)
496 yield None
497 self.item = None
~/fastai/fastai/data_block.py in process_one(self, item, processor)
73 if processor is not None: self.processor = processor
74 self.processor = listify(self.processor)
---> 75 for p in self.processor: item = p.process_one(item)
76 return item
77
~/fastai/fastai/text/data.py in process_one(self, item)
249 self.vocab,self.max_vocab,self.min_freq = vocab,max_vocab,min_freq
250
--> 251 def process_one(self,item): return np.array(self.vocab.numericalize(item), dtype=np.int64)
252 def process(self, ds):
253 if self.vocab is None: self.vocab = Vocab.create(ds.items, self.max_vocab, self.min_freq)
AttributeError: 'NoneType' object has no attribute 'numericalize'
Is this expected behavior? In other words, can we only predict language model sentences in the same session where we create the language model?
After loading the data, I was able to confirm that the data for the LM has a vocab class associated with it (i.e., not None). These are the steps that lead to the above error:
custom_toks = ['rrname', 'rrdocln', 'rrln', 'rrdocfn', 'rrfn', 'rrinits', 'rrhosp', 'rrwork', 'rrloc', 'rrcntry', 'rrstate', 'rraddr',\
'rrdate', 'rrmmdd', 'rryear', 'rrmnth', 'rrhols', 'rrdtrange', 'rrpager', 'rrradclip', 'rrssn', 'rrmrno', 'rrage90',\
'rrsno', 'rrunitno', 'rrmdno', 'rrph', 'rrpno', 'rrjobno', 'rrdicinfo', 'rrcontinfo', 'rrattinfo', 'rr3digit', 'rr2digit',\
'rr1digit', 'rrhour', 'rrmidngt', 'rrdawn', 'rrfore', 'rrafter', 'rrdusk', 'rrngt']
tok_proc = TokenizeProcessor(tokenizer=Tokenizer(special_cases=custom_toks, n_cpus=1), mark_fields=True)
num_proc = NumericalizeProcessor(max_vocab=60_091, min_freq=2)
data_lm = TextLMDataBunch.load(path, 'lm-toknum', processor=[tok_proc, num_proc])
data_lm.show_batch()
data_lm.vocab.numericalize is not None
True
However, when I run the debug magic and get to the step def process_one(self,item): return np.array(self.vocab.numericalize(item), dtype=np.int64), self.vocab is indeed None. I’m not sure why though.
I must be missing something, and have spent a good few hours trying to work this out.
Using: 1.0.39.dev0
I have a TabularDataBunch created like this:
data = TabularDataBunch.from_df(path, df=df, dep_var=dep_var, valid_idx=valid_idx, procs=procs, cat_names=cat_vars, cont_names=cont_vars, test_df=df_test)
and a learner created as per below:
learn = tabular_learner(data, layers=[1000,500], ps=[0.001,0.01], emb_drop=0.04, metrics=accuracy)
I can create a single prediction ok using:
learn.predict(df_test.iloc[0])
Category the_predicted_category,
tensor(249),
tensor([2.6166e-04, 7.0190e-05, 1.6028e-05, 5.5844e-06, 1.7006e-03, 1.3622e-04,
4.4630e-04, 5.3242e-05, 5.2404e-06, 8.1808e-04, 1.8185e-05...
I can get the predictions like this:
preds, y = learn.get_preds(DatasetType.Test)
which returns:
tensor([9.1703e-08, 2.5174e-07, 1.0606e-07, 3.4502e-08, 3.1051e-07, 4.4129e-07,
1.0235e-06, 2.3513e-07, 3.2420e-08, 6.2728e-07, 3.2848e-07, 7.2376e-07,
4.3272e-07, 4.3480e-07, 7.6543e-07, 4.0239e-07, 1.6350e-07, 2.8251e-07,
3.4620e-07, 2.1245e-07, 1.3313e-07, 4.1516e-07...
Then from the index of the most likely in the tensor above, how do I get get the actual class it corresponds to?
Things I have tried:
My predicted tensor has dimension torch.Size([632])
If I get a CategoryList from the test dataset:
data.test_ds.y
It has a length of 8 and is non-unique - I presume this is giving me a batch of y data (same for data.test_dl.dataset.y)
Then if I look at:
data.train_ds.classes
the dep_var that I want to reconstruct the category name out of is not in the classes, even though it was included:
df = train_df[cat_vars + cont_vars + [dep_var]].copy()
Then when I look at TabularDataBunch.from_df() during execution:
src = (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(valid_idx)
.label_from_df(cols=dep_var, classes=classes))
data.train_dl.c
returns 632 - which looks to be the number of categories in my dep_var…
Testing the assumption that fastai just uses something similar to below to generate the categories from which test predictions are made (I couldnt find anything like this in the code), and then indexing into ‘categories_to_index_into’ to get the predicted category :
categories_to_index_into=set(train_df['Target_Column'].values)
does not give the same predicted categories as per:
for idx, row in df_test.iterrows():
pred = learn.predict(row)
Iterating though the entire dataframe row by row is unfeasible as it contains several million rows. Has anyone managed to work this out?
It looks like your test set wasn’t properly loaded here.
Note that a test set is always unlabelled, so this is fake data you’re going to see when looking at data.test_ds.y. Still, it should have the right length (which doesn’t seem to be 8 since you were talking about several millions lines). Make sure that data.test_ds.x has something that makes sense with your data.
I followed the instructions in LM inference here:
vocab = Vocab(pickle.load(open(path/'lm-toknum'/'itos.pkl', 'rb')))
empty_data = TextLMDataBunch.load_empty(path, fname='lm-meta-db.pkl')
learn = language_model_learner(empty_data)
learn.unfreeze()
learn.load('lm-acc-583', with_opt=False)
I got an error of dimension mismatch:
--------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-7-f04e66109460> in <module>
2 learn = language_model_learner(empty_data)
3 learn.unfreeze()
----> 4 learn.load('lm-acc-583', with_opt=False)
~/fastai/fastai/basic_train.py in load(self, name, device, strict, with_opt)
213 state = torch.load(self.path/self.model_dir/f'{name}.pth', map_location=device)
214 if set(state.keys()) == {'model', 'opt'}:
--> 215 get_model(self.model).load_state_dict(state['model'], strict=strict)
216 if ifnone(with_opt,True):
217 if not hasattr(self, 'opt'): opt = self.create_opt(defaults.lr, self.wd)
/net/vaosl01/opt/NFS/su0/anaconda3/envs/mer/lib/python3.7/site-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
767 if len(error_msgs) > 0:
768 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
--> 769 self.__class__.__name__, "\n\t".join(error_msgs)))
770
771 def _named_members(self, get_members_fn, prefix='', recurse=True):
RuntimeError: Error(s) in loading state_dict for SequentialRNN:
size mismatch for 0.encoder.weight: copying a param with shape torch.Size([60093, 400]) from checkpoint, the shape in current model is torch.Size([8, 400]).
size mismatch for 0.encoder_dp.emb.weight: copying a param with shape torch.Size([60093, 400]) from checkpoint, the shape in current model is torch.Size([8, 400]).
size mismatch for 1.decoder.weight: copying a param with shape torch.Size([60093, 400]) from checkpoint, the shape in current model is torch.Size([8, 400]).
size mismatch for 1.decoder.bias: copying a param with shape torch.Size([60093]) from checkpoint, the shape in current model is torch.Size([8]).
Ok, the problem is that empty_data = TextLMDataBunch.load_empty(path) loads with a vocab of size 8:
empty_data.vocab.itos
['xxunk', 'xxpad', 'xxbos', 'xxfld', 'xxmaj', 'xxup', 'xxrep', 'xxwrep']
even though, I did a data_lm.export() after creating my original databunch. Hence, I’m getting the mismatch error.
I used both viz data and inference and it worked. Just keep track on object vars as they are reused and may cause problems. Looks like you are referring to two vocabs.
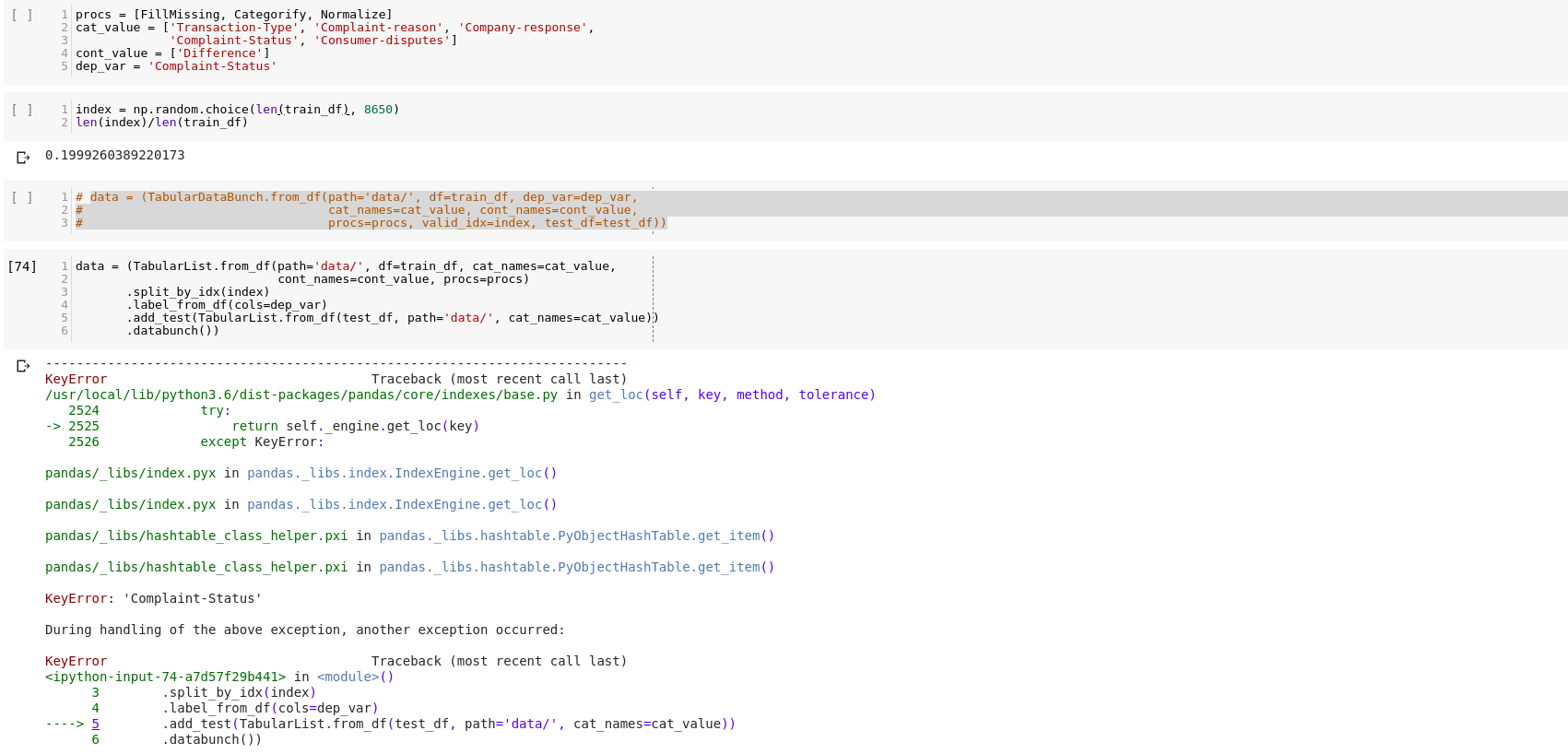
I am unable to add test dataset in TabularList.from_df as it raises some KeyError. Can someone tell me what I am doing wrong?
Edited : I narrowed down the problem, its happening because of Categorify
I’m using the same vocab that I saved when I created my databunch for language modeling. And I exported that which is used to creating the empty_data. I’m not sure why the empty_data has only 8 words in its vocab.
Just checked on master and this part is still working. If you use pickle to open the file path/‘export.pkl’, what do you see as vocab?