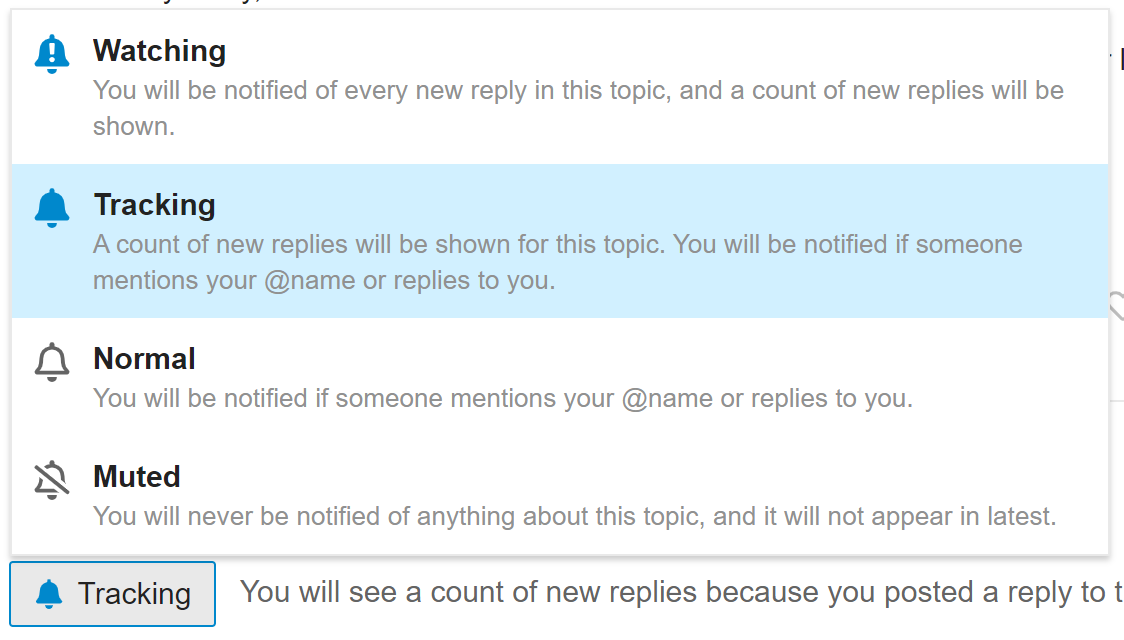
There are major changes coming so I figured I should send you all a message to let you know to keep an eye out for them. I’ll update this thread with updates, so please watch this thread, by clicking the “Normal” button at the bottom of the thread, and selecting “Watch”:
fastai v2 will be released in the next few weeks, and it is not API-compatible with fastai v1 (it’s a from-scratch rewrite). It’s much easier to use, more powerful, and better documented than v1, and there’s even a book (624 pages!) about it. The book is also available for free as Jupyter notebooks. If you’re interested in experimenting with the pre-release version of fastai v2, you can get it here: http://dev.fast.ai/ .
fastai v2 only works with the upcoming 2020 version of the course. It won’t work with any previous version. The 2020 version of the course will be available at the same time that fastai v2 is officially released. If you’re currently working through one of the existing courses, keep going!  The basic concepts you’re learning will be just as useful for fastai v2. There is no 2020 version of part 2 of the course recorded yet, and we don’t have a date for when that might happen.
The basic concepts you’re learning will be just as useful for fastai v2. There is no 2020 version of part 2 of the course recorded yet, and we don’t have a date for when that might happen.
The 2020 version of the course includes material covering both machine learning and deep learning. So there won’t be a separate “Introduction to Machine Learning” (although the old one will still be available).
fastai v1 will continue to be available, and we’ll continue to provide bug fixes (and accept pull requests for it). To pin your fastai version to v1 (i.e., to avoid it upgrading automatically to v2), run the following command (assuming you use conda):
echo 'fastai 1.*' >> $CONDA_PREFIX/conda-meta/pinned
Then, when you’re ready to upgrade to v2, remove the $CONDA_PREFIX/conda-meta/pinned file.
The github repo for fastai v1 will shortly be renamed to fastai/fastai1, and the repo for v2 will shortly be renamed from fastai/fastai2 to fastai/fastai.
If you’re interested in getting involved in fastai2 development, or just watching my live coding sessions (which I do most days), connect to our Discord server, which is where I stream my live coding, and there’s some real-time fastai2 development discussion:
I’ll be moving all fastai development forum discussion into #fastai-users:fastai-dev. The forums are the best place to ask questions.