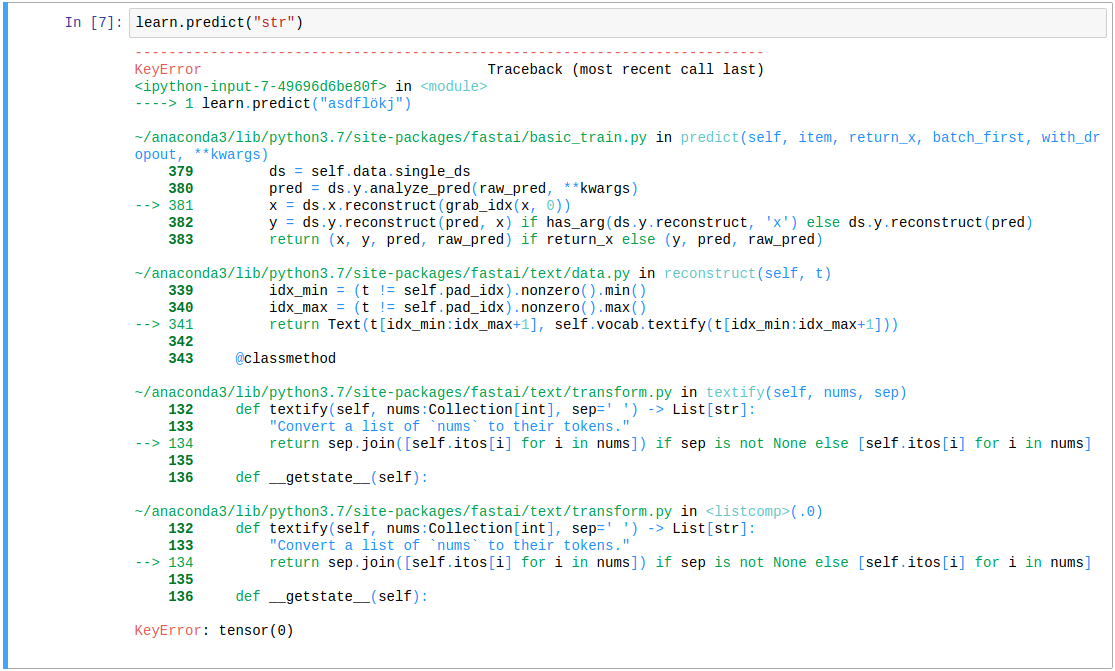
Hello,
I followed this project to fine-tune an existing german model: GitHub - jfilter/ulmfit-for-german: 👩🏫 Pre-trained German Language Model with sub-word tokenization for ULMFIT .text_classifier_learner I cann’t predict data. Everytime I call learn.predict(str) I get this error:
What I did so far:language_model_learner like this (it is a model trained befor 1.0.53 Major new changes and features - #8 by sgugger ):
config = awd_lstm_lm_config.copy()
I fine-tune it and save it with learn_lm.save_encoder('enc').
Then I load it with the text_classifier_learner:
config = awd_lstm_clas_config.copy()
and learnd the classifier on existing data.
Everything works fine (accuracy (while learning) looks ok), however I cann’t predict anything with learn.predict("str") because of the already stated error.
Do anybody of you have an idea what the problem could be?
Yours,
sgugger
February 12, 2020, 3:15am
2
No one can answer without knowing how you assembled your data. Learn.predict expect it in the same way.
Unfortunately, I do not know what you mean with “assembly”.word-embedding layer like this:
bpemb_de = BPEmb(lang=“de”, vs=25000, dim=300)
But I think I know what you mean… I just wrote this Method for prediction:
def con(x):
learn.predict(con(“str”))
But now I get the error:
ValueError: only one element tensors can be converted to Python scalars
Do I get still something wrong?
Basically, I followed the instructions in this notebook.
dkay
October 8, 2020, 12:09am
4
I did exacly the same and have the same error…
did you solve it ?
dkay
October 8, 2020, 12:24am
5
I found out what it is.
The itos has to be converted to a list
chris3
October 13, 2020, 2:34pm
6
Could someone provide a notebook with a working example?
I also try to implement a german model, but the code on https://github.com/jfilter/ulmfit-for-german
Especially, i do not know how to use the following lines:
TextClasDataBunch.from_ids(...)
I think the class should be now TextDataLoaders., but there is no longer a ‘from_ids’ method.
Vocab(itos)
I can not find this class. Is this based on ’ torchtext.vocab. Vocab'?
Thanks for any hints.