Yes, so, can we propose that the non-linear activation is the key to turning the ordinary linear layers/neurons into magical neuralnet? Is it true? I think the excel experiment below provide some support to this proposal. @Moody
The observations from the experiment:
- after adding a ReLU to the first neuron, the 2-neuron model can train freely without error exploding (it must have been magic of ReLU, right?)
- within the first epoch, 3 out of 4 weights found their optimal and stop updating themselves (Whereas, neither of the two weights of 1-neuron model’s are still updating without settling, it must have been magic of ReLU, right?)
- however, although improve steadily the error is far worse than the 1-neuron model. (Interesting!)
try the spreadsheet yourself
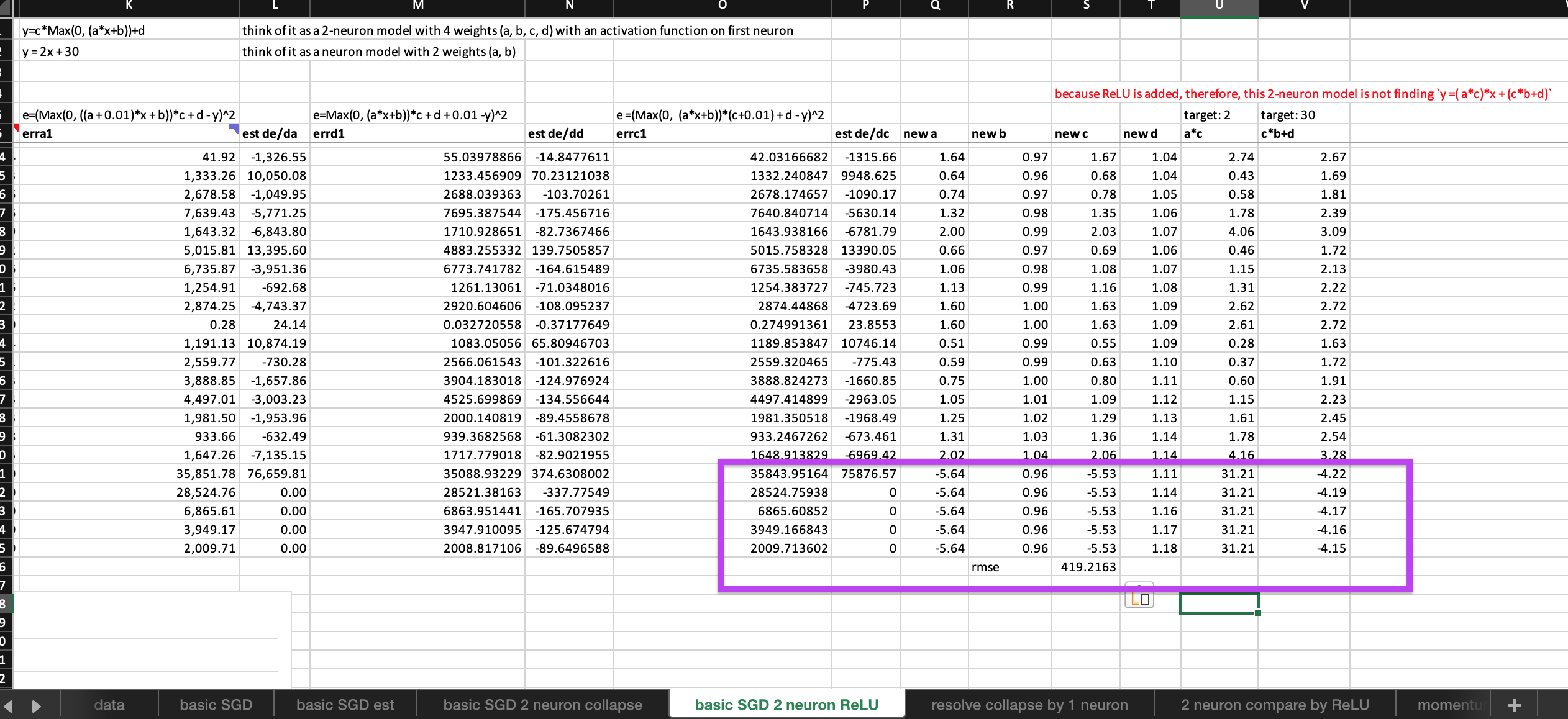
Then comes more questions:
- Why a more complex and smart model (4 neurons with ReLU) still can’t beat a single neuron model without activation function?
- Can such 2-neuron ReLU sandwich ever beat a simple linear neuron model on finding this simple
y=2x+30target? What can we do about it to achieve it?