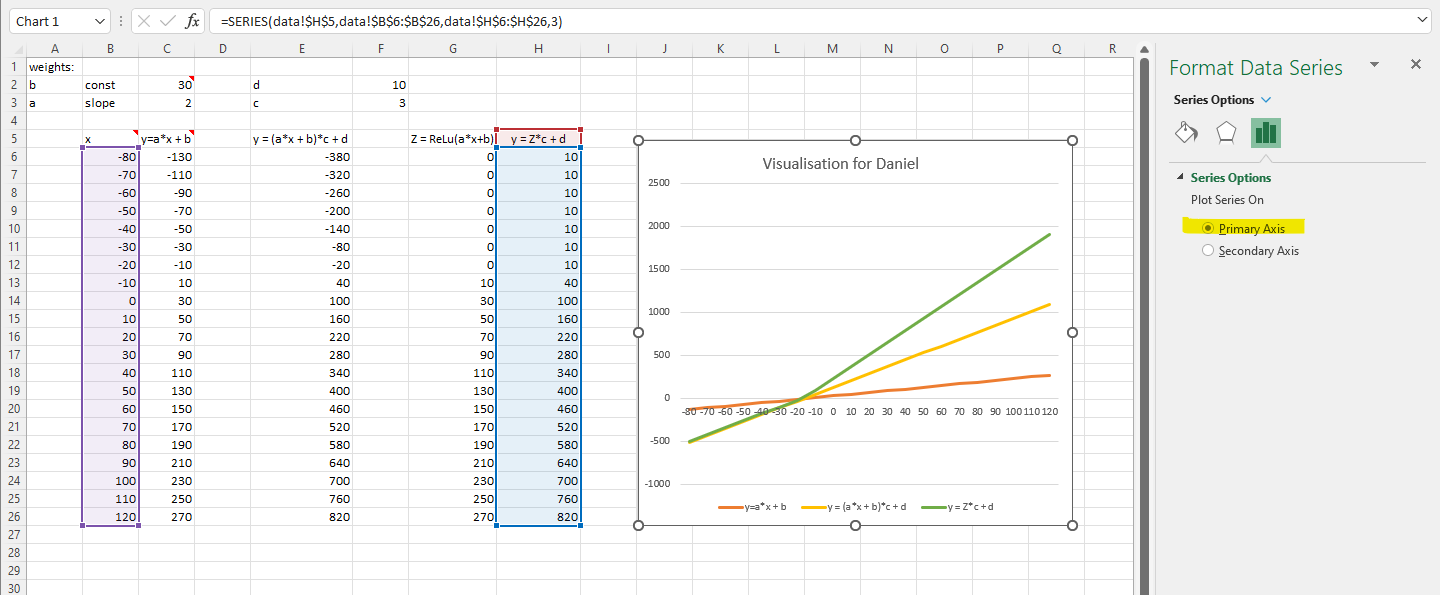
Hi @Daniel Thank for pointing it out. It seems the problem is at my end. I set the workbook calculation as “Automatic” so I did not check the y-axis values. My bad.
For some reasons, the auto/manual calculation options are grey out.
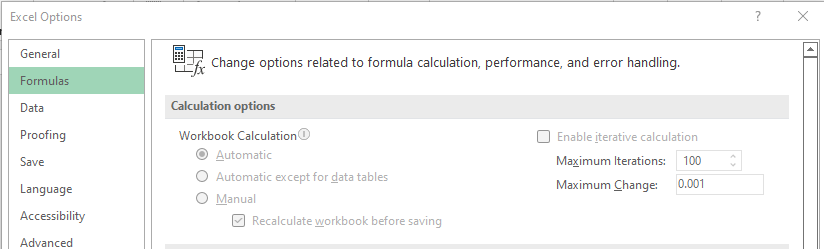
Interestingly, the same dataset (green line) changed values if I switched from Primary Axis to Secondary Axis (with the corrected y-axis value shown at the right-hand side). I think there is a ![]() .
. ![]()