Now I have a more clear view of what I tried to experiment.
First of all, Jeremy used graddesc.xlsx file to demonstrate the following things for us:
- how are weights updated using SGD?
- how better techniques like Momentum, Adam etc can speed up the training with SGD?
- all these techniques can be implemented with a linear model with 2 weights.
To better appreciate Jeremy’s teaching above, I want to do the same above with a slightly more complex model. To be more specific, I want to train a 2-neuron (4 weights) model or a model of two linear functions (one on top of the other) to find the simple linear function y = 2x + 30. In Jeremy’s spreadsheet, he used a linear model y = ax+b to find y=2x+30. So, my model is slightly more complex.
Is my model smarter and faster than a simple linear model?
At first, I expected my model to be smarter may even be faster as it is slightly more complex. However, it’s error exploded without finishing one epch of training, not mentioning it is so much worse than the 1-neuron model by Jeremy.

Jeremy’s 1-neuron model has error of 151 after 1 epoch
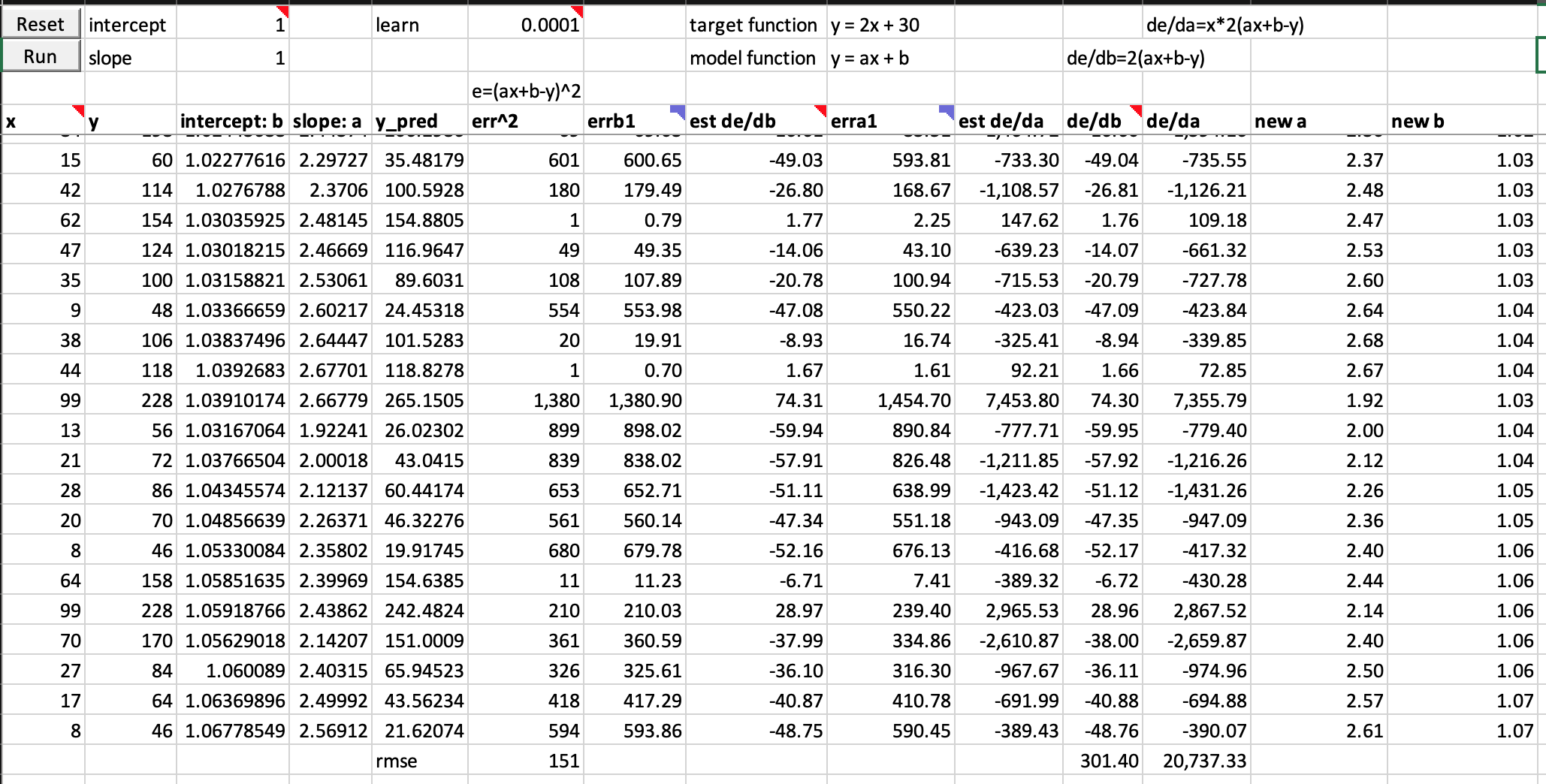
Question: Why and how do my errors get exploded? I have not get my mind around on this. I guess I need to find a way to visualize it.
Can I get the training easier for my model by giving it better initial weights?
By giving a better weights initialization, yes, I can only finish 1 epoch and then exploding errors. The error is better but still much worse than 1-neuron model.
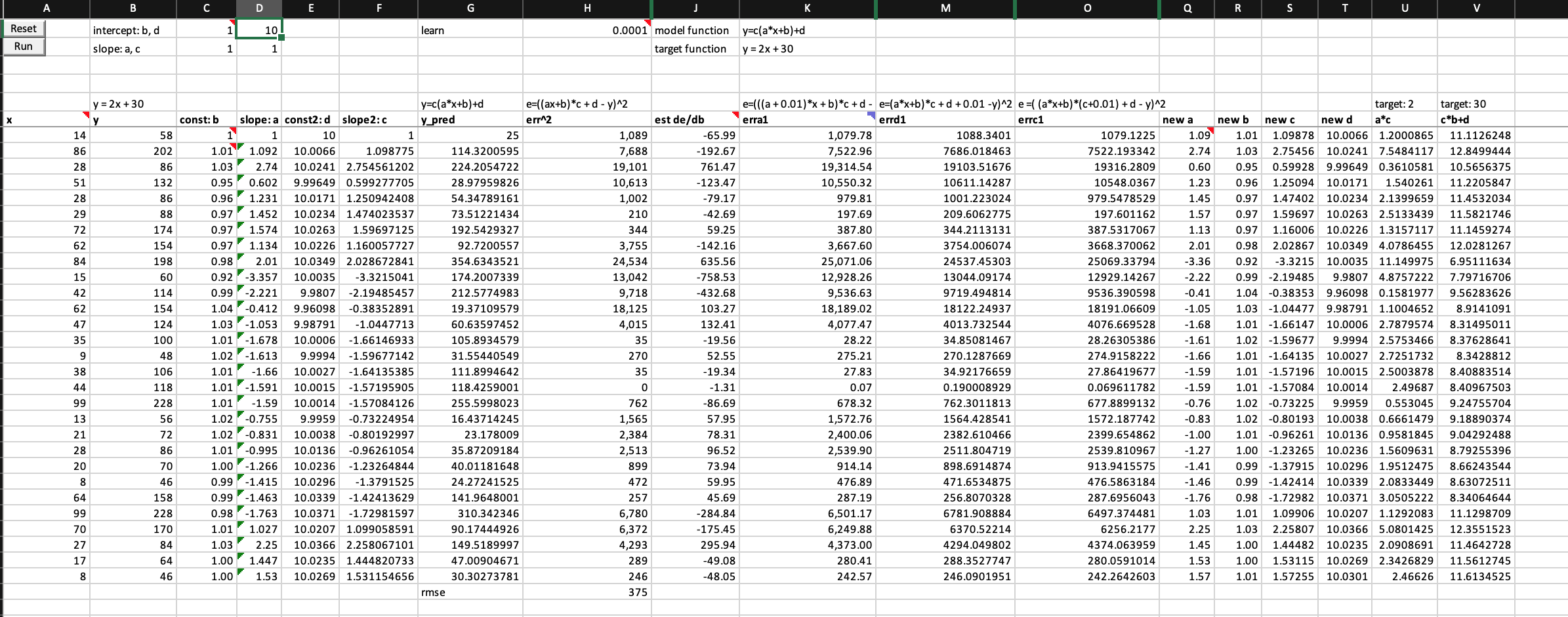
What if adding a single ReLU to the first neuron of my 2-neuron model?
My model can keep training without exploding errors. But my error is still much greater than 1-neuron model.
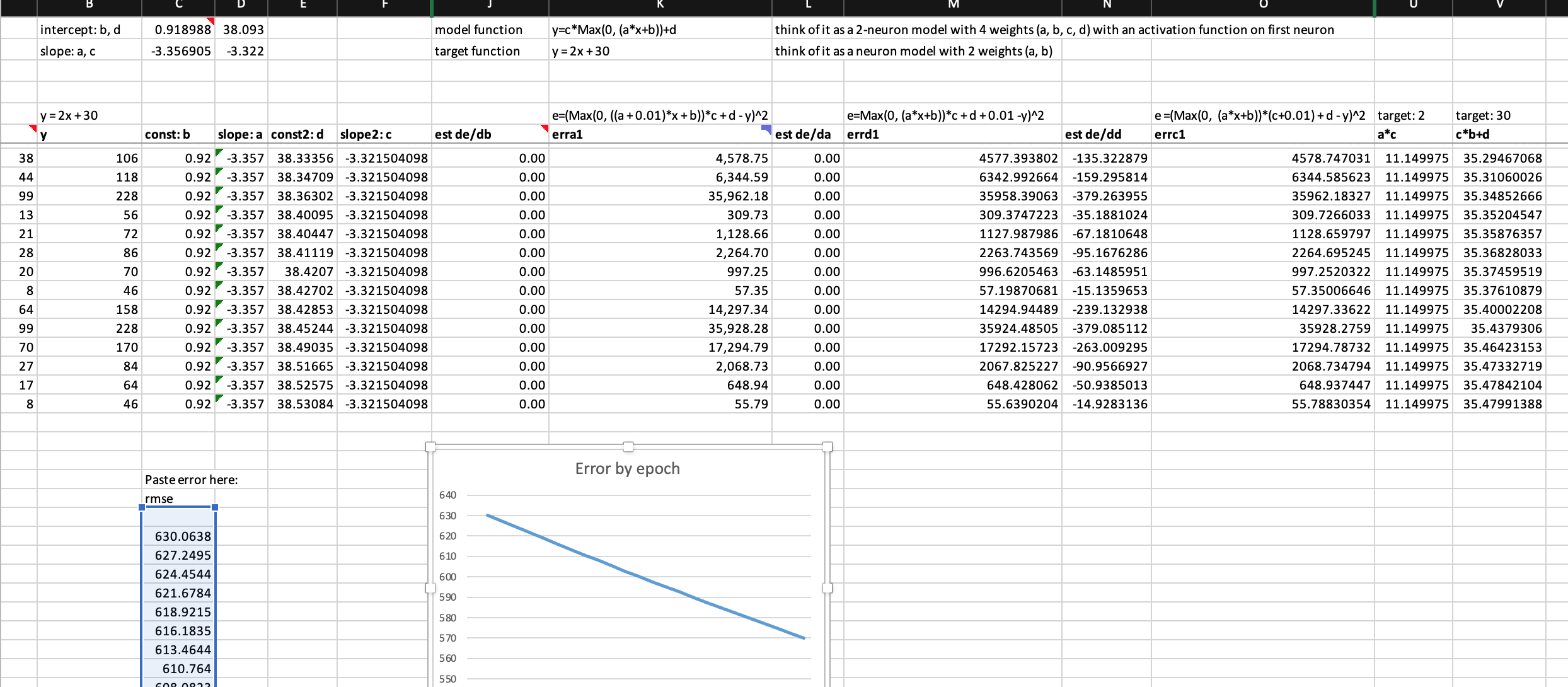
Here, I’d like to propose some interesting findings below. The updated spreadsheet can be downloaded here
When training to find a simple linear function y = 2x + 30:
- 2-neurons without activation or ReLU is not simply collapsed into a single neuron, because it can hardly train and when it finishes an epoch, the error is much much worse than a single neuron model.
- 2-neurons model with ReLU can train freely, so ReLu makes multi-neuron models working.
- but this 2-neurons with ReLU still train much slower than 1-neuron model
Those findings above are interesting, because I can’t explain why exactly. To find out why, I plan to try to visualize the experiment data to get a feel about how error get exploded, and read fastbook chap 4 and other related chapters.
Any advice on how should I explore and experiment on those questions above are very very welcome.