Ah thank you for this. It sort of answers my implicit question from our study group discussion this morning around the encoders and how much (if anything) is lost during the encoding process. I’m wondering what the implications of this data loss are.
Questions from Lesson 9A Stable Diffusion Deep Dive
Are the terms “training” & “sampling” below equivalent to “encoding” & “decoding”

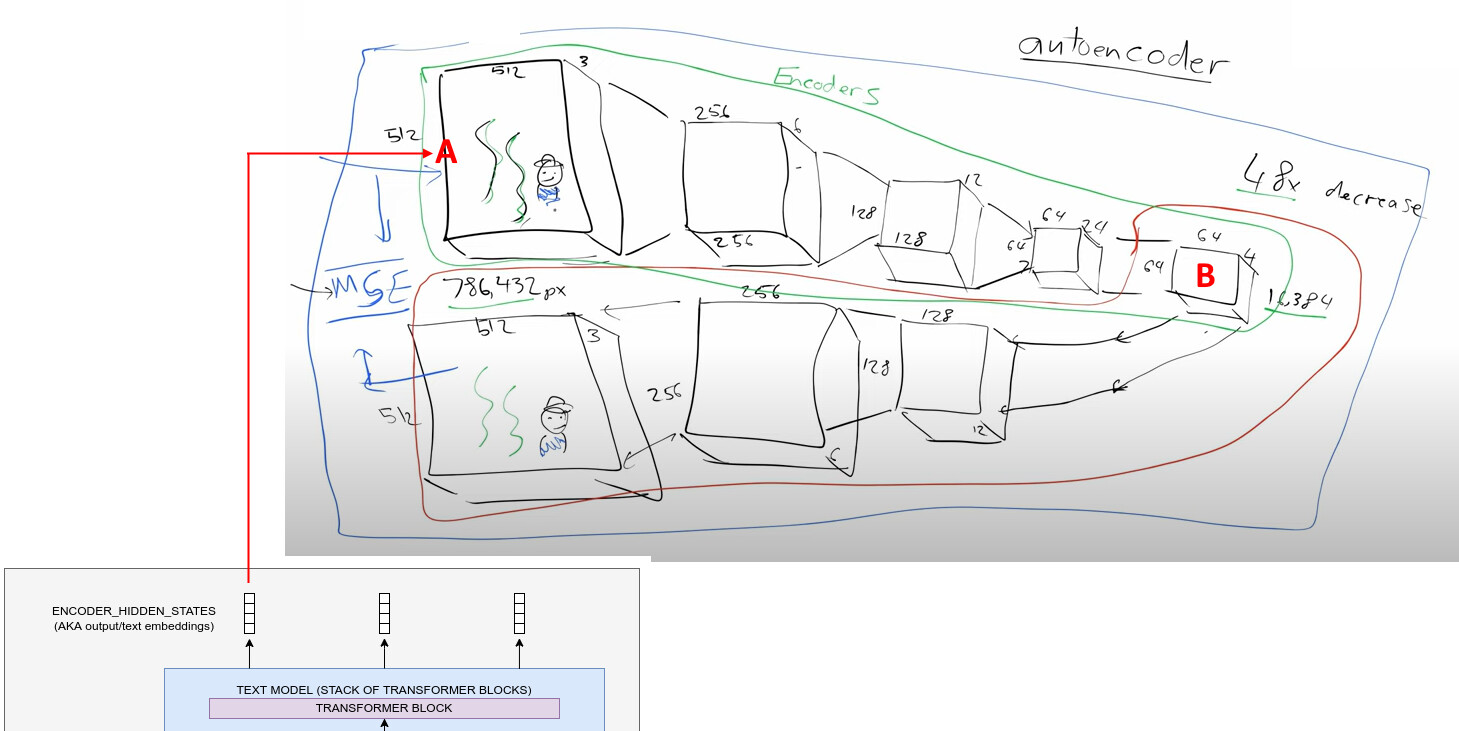
Also, Lesson 9A at 12:39 says the “Final hidden States” aka “Encoder Hidden States” aka “Output Embeddings” are what is “fed to the unit to make its predictions.”
Is that fed into Point-A of the sketch from Lesson 9, or perhaps into Point-B ?
For machine learning, I’d guess its EASILY good enough to have no practical no implication, e.g. for pattern matching / decision making.
For most photographic archiving, if you can’t see a visual difference, that is sufficient. The question would be how resistant is it against corner case aberations. It would be interesting to compare “latent compression” against JPEG, which is typcially 10:1 compression. Best to start with a RAW image encoded directly by both “latent compression” and JPEG compression.
2 Likes
An interesting observation when using pipe to generate multiple images. I guess it does it in parallel in case if multiple prompts provided, right?
The second snipped raised a memory error as it tried to allocate x4 MiB of VRAM, while the first one completed successfully.
imgs = [pipe(prompt).images[0] for _ in range(4)] # works fine
imgs = pipe([prompt] * 4).images # allocates x4 memory and fails on my machine
2 Likes
Argghhh I always do that! I even gave myself a little reminder before the lesson to get it the right way around! ![]()
4 Likes
It was the right way around! The issue here is simply that “the gradient of F with respect to x” (where F is a multivariable function) is usually written \nabla_x F, not \nabla F / \nabla x (even though you would in fact write a derivative approximation of a single-variable function as \Delta f/\Delta x).
The reason for this is that although \Delta f means “a small change in f” (and thus it makes sense to divide it by a small change in x), \nabla F does not mean “a small change in F”; rather, it refers to a vector pointing “uphill” on the surface defined by F; \nabla_x F is nothing more than the x-component of this vector (i.e. how far you have to go along the x-axis to go 1 unit in the “uphill” direction).
I meant to point this out at the preview lecture last Tuesday, but didn’t want to interrupt your flow (and I promptly forgot about it afterwards).
8 Likes
Ah right - very helpful thank you!
2 Likes
Hi! At the end of each fastaibook chapter, there is a questionnaire. I found that super helpful to test my understanding, so I wrote these questions for Lesson 9. Please add more if you have them!
Part 1: how to get started with stable diffusion.
Questionnaire
- Why is this called lesson 9?
- What does the strmr.com service do?
- Mention the four fastai contributors.
- Mention four computing services.
- What’s fastai/diffusion-nbs?
- What’s the content of suggested_tools.md file? Mention two tools.
- What is the main library used in the stable_diffusion.ipynb notebook? What’s the organization behind it?
- What’s the main idea of a Hugging Face pipeline, and which fastai tool is the most similar to it?
- What’s the from_pretrain method for?
- What extra feature Paperspace and Lambda labs have that makes them handier to use with pipelines than Google’s Colab
- Which method of the stable diffusion pipeline should you call to produce images from a prompt?
- Which torch method should you use to set the random seed?
- Why would you set the random seed manually?
- Why does the pipeline have many steps, and what does it do in each?
- Why do we used 50 steps and not 3? Are these values set in stone?
- What does the image_grid function do?
- What effect do you get when you change the value of the guidance_scale parameter?
- Roughly, how does the guidance_scale work?
- What’s the effect of a negative prompt?
- How does the image-to-image pipeline work?
- What’s the effect of the strength parameter?
- How can you use the image2image pipeline twice to produce an even better image?
- How was the text-to-pokemon model fine-tuned?
- What is “textual inversion”?
- What is “dreambooth”?
Part 2.
- How can you use a mode/function that outputs the probability that an image is an image of a handwritten digit to generate handwritten digit images?
- How can you generate a dataset of images of handwritten digits and non-handwritten digits and labels that indicate how much each image resembles a handwritten digit?
- Describe the main components of a neural network (disregard specifics about the architecture)
- Describe a network that can predict the noise added to each image in the dataset discussed in question 2.
- How can you use the network described in question 4 to generate images of handwritten digits?
- In practice, what’s the architecture of such a network?
- What’s a reasonable size for representing images of handwritten digits? And for beautiful realistic images? What problem will we face if we want to use the former approach to produce beautiful high-definition images?
- Is it possible to efficiently but lossy compress images? Which image format does this?
- How can we store high-definition images more efficiently using a neural network? What’s the name of these kinds of networks?
- What’s the name of the output of the encoder?
- How can you use the network from question 9 to speed up the training and inference of the network of question 4?
- How can you modify the network from question 4 to be guided by a particular digit?
- What’s the problem with this approach for a data set with images with arbitrary descriptions?
- How can we build a dataset of images and descriptions?
- Suppose you have the dataset from question 14, a randomly initialized network that produces embeddings from the descriptions and another network that produces embeddings form the images (both embedding types with the same shape). Which loss function could you use to train the networks, so they output similar embeddings for (image, description) pairs that appear in the dataset and different ones for pairs that do not appear in the dataset?
- What is the name of the pair of models described in 15?
- How can we use the model described in 15 to guide image generation?
- What is the name of the loss described in 15?
- What is the name of the gradients used in 1?
- What other greek letter is used for the standard deviation sigma of the noise?
- What is a noise schedule, and what are the time steps?
- When we generate an image from random noise, we multiply the noise by a small number before the subtraction instead of subtracting the predicted noise. Why?
- What is the role of the diffusion sampler?
- What other deep learning object is similar to the diffusion sampler?
- Apart from the noisy latent input and the embedding for guidance, what other input is used for the diffusion models? What is the area of math where this idea came from? Do you think this is a necessary input? Why?
- Instead of using MSE as the loss, what other loss could be used to better approximate if the resulting image looks real?
21 Likes
Nice! I’ll add a link to the wiki post at the top of this thread.
1 Like
Hi,
I have been trying to run the stable_diffusion Jupyter notebook locally, and cannot get past the imports.
The error is:
---> 6 from diffusers import StableDiffusionPipeline
---> 21 from .models import AutoencoderKL, UNet2DConditionModel, UNet2DModel, VQModel
---> 19 from .unet_2d import UNet2DModel
---> 24 from .unet_blocks import UNetMidBlock2D, get_down_block, get_up_block
--> 788 class AttnSkipDownBlock2D(nn.Module):
--> 802 output_scale_factor=np.sqrt(2.0),
AttributeError: module 'numpy' has no attribute 'sqrt'
numpy is installed with:
micromamba install -c conda-forge numpy
and shows, with micromamba list
numpy 1.22.3 py39h7a5d4dd_0
The huggingface software was installed with:
micromamba install -c huggingface transformers
micromamba install -c huggingface huggingface_hub
pip install diffusers
I am embarrassed to say I have already spent a whole day trying to solve this problem. Ubuntu 18.04.6.
Please help if you can.
![]()
After going through @ababino’s excellent set of questionnaires I decided to create a wiki post with the answers to the questions.
It’s currently incomplete; please feel free to edit it to add more answers.
Part 1:
- Lesson 9 is the continuation of the FastAI part 1 course which has 8 lessons.
- strmr.com offers a service to fine-tune diffusion models for subject generation based on DreamBooth.
- @ababino @muellerzr @ilovescience @init_27 and many more…
- Computing services:
- Lambda Labs
- Paperspace Gradient
- Jarvis Labs
- vast.ai
- It’s a repository containing notebooks to help you get started with stable diffusion.
- It contains notebooks and tools created by the AI art community to check out as a starting point.
-
stable_diffusion.ipynbnotebook uses the fantastic diffusers library by good folks at HuggingFace. - HuggingFace pipeline are end-to-end inference pipeline that allows you to get started with just a few lines of code.
- We use the
from_pretrainedto download the pre-trained weights. - Paperspace and Lambda Labs have persistent storage so no need to reinstall any libraries/dependencies every time you start your Notebook, as with Colab.
- We could
StableDiffusionPipelineto produce images from a prompt. - We can set random seed using the torch method
torch.manual_seed(seed) - We should set a random seed manually for the reproducibility of our results.
- Stable Diffusion is based on a progressive denoising algorithm; we start with pure random noise and remove some noise incrementally with each step to produce a convincing image.
- Currently the model doesn’t do a very good job with only a few denoising steps. The number of denoising steps is not fixed, but the model works well with more.
- The
image_gridfunction takes a set of images and displays them in a grid. - The adherence of the generated images to the prompt increases as the value of the guidance scale increases.
- For each prompt, two images are created, one with the prompt and another one with no prompt (some random image), and then an average of both images is taken as dictated by the
guidance_scaleparameter. - Negative prompting refers to using another prompt to generate an image and subtracting it from the image generated by the original prompt.
- The Image2Image pipeline starts with a noisy version of an initial image instead of pure noise and gradually denoises it to match the prompt.
- The
strengthparameter specifies to what degree to follow the original image. - We could take the Image2Image pipeline’s output image and feed it back into the pipeline with a different prompt to produce even better images.
- The Stable Diffusion model is fine-tuned on a dataset of pokemon images with respective captions.
- “textual inversion” is the idea of creating a new token for a particular concept and fine-tuning a single embedding to refer to a particular concept using example images.
- “dreambooth” refers to taking an existing token that is rarely used and fine-tuning the model to associate that token with the examples images we provide.
4 Likes
Based on my understanding so far, and I’m new to this too, I think the text/output embeddings are fed in at point B, as point B is where the Unet resides.
Using “Stable Diffusion Deep Dive notebook, The Autoencoder” as an example,
At point A, we convert the image to latent using the vae encoder
def pil_to_latent(input_im):
# Single image -> single latent in a batch (so size 1, 4, 64, 64)
with torch.no_grad():
latent = vae.encode(tfms.ToTensor()(input_im).unsqueeze(0).to(torch_device)*2-1) # Note scaling
return 0.18215 * latent.latent_dist.sample()
This will output the latent. Next, we feed the latent into the Unet residing at B. Here the latent goes into a for-loop to denoise for certain number of time-steps.
for i, t in tqdm(enumerate(scheduler.timesteps)):
and at each iteration, the latent is fed into the unet
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings)["sample"]
Inside the Unet, the text/output embeddings are fed repeatedly during the down-block, mid-block, and up-block (refer to huggingface diffuser UNet2DConditionModel codes here. I’ve annotated where the text embeddings are fed using three hashes ###
# 3. down
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states, ### text-embedding fed into down-block
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
down_block_res_samples += res_samples
# 4. mid
sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states) ### text-embedding fed into down-block
# 5. up
for i, upsample_block in enumerate(self.up_blocks):
is_final_block = i == len(self.up_blocks) - 1
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
# if we have not reached the final block and need to forward the
# upsample size, we do it here
if not is_final_block and forward_upsample_size:
upsample_size = down_block_res_samples[-1].shape[2:]
if hasattr(upsample_block, "attentions") and upsample_block.attentions is not None:
sample = upsample_block(
hidden_states=sample,
temb=emb,
res_hidden_states_tuple=res_samples,
encoder_hidden_states=encoder_hidden_states, ### text-embedding fed into down-block
upsample_size=upsample_size,
)
else:
sample = upsample_block(
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
The Unet will output a new latent, which we will feed back into the Unet until the for-loop ends. Everytime a new latent enters the Unet, the text-embedding is fed alongside again in the down-block, mid-block, and up-block.
Once the for-loop ends, we exit B, and feed the final latent to the decoder block (which is after point B).
def latents_to_pil(latents):
# bath of latents -> list of images
latents = (1 / 0.18215) * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
return pil_images
Finally, here we get our unique, fantastic, amazing, one-of-a-kind, new image.
2 Likes
Its hard to assist when you only show the error and not the code causing the error, or even better, the whole notebook (on of the downsides of running locally)
Sorry to here in consumed so much time. It would be useful for you to see a summary of what you’ve tried. (sidebar: also btw, my own experience is sometime while writing that summary I see something I missed that is the keystone of the problem)
Speaking very generally, it can be feel daunting to be troubleshooting a huge unfamiliar notebook. A useful approach is rather than troubleshooting the notebook as a whole, break out the thing you have a problem with. Even when the error is in the first few cells, the rest of the code is distracting. For example, considering your problem with a importing a particular numpy function, you could do the following…
-
Search for: numpy sqrt smallest example import
-
Find a small example like this…
import numpy as geek
arr1 = geek.sqrt([1, 4, 9, 16])
print("square-root of an array1 : ", arr1)
Now if that has problem, its easier to focus yourself and the community on a issue. Its a lot less code to post and for readers to parse.
My other advice is… an old engineering adage… if you can’t solve the problem, change the problem. Although you want to run it locally, try running it in another environment like a cloud server. If it works, you have a point of comparison to compare environments. If it fails, its more visible and easier for the community to assist.
3 Likes
The code that causes the error is the import shown at the top:
from diffusers import StableDiffusionPipeline
and after several layers ends with
AttributeError: module 'numpy' has no attribute 'sqrt'
Today I see that every function that is supposed to be in numpy gives this same attribute error. I can’t even display sys.path (gives Key error trying to print). So something must be very screwed up.
To change this problem I am going delete environments, micromamba, and start over.
1 Like
I don’t think I’ve ever used conda-forge as the channel for numpy. Maybe perhaps just omit that part? You’ll want to uninstall numpy first.
Edit Now that I think about it more, the fact that you’re installing it like this individually to begin with is a sign to me you may be making life more difficult than it needs to be. Here’s what works for me:
- Install fastai using the conda install described here: GitHub - fastai/fastai: The fastai deep learning library
- Use pip to install the requirements in requirements.txt here: GitHub - fastai/diffusion-nbs: Getting started with diffusion
My guess is you’d be best off creating a fresh conda environment for this at this point.
I ended up creating a video where I walk through the environment rather than a blog post. Would love to hear your thoughts! Fastai .devcontainer Environment Creation - YouTube
6 Likes
Hi Jason. I was able to get the notebook running by following your simplifying suggestions. Used conda in the end - micromamba and mamba kept reporting version conflicts.
Thank you! Now I’ll stay up all night making astonishing pictures.
4 Likes
Awesome!
I added a PR here Adding small section on enable attention slicing by kevinbird15 · Pull Request #12 · fastai/diffusion-nbs (github.com)
Is this the type of PR you were thinking? I added a section that explains enable_attention_slicing and a commented out line for somebody to use.
2 Likes