Posting a link to this here since Jeremy mentioned it briefly during Lesson 6.
Very interested in hearing people’s experience and ideas around the very exciting topic of text data augmentation!
Posting a link to this here since Jeremy mentioned it briefly during Lesson 6.
Very interested in hearing people’s experience and ideas around the very exciting topic of text data augmentation!
@Taka, following on from this point, at pymetrics we developed this python library called audit-AI. The purpose of it is to measure and mitigate the effects of discriminatory patterns in training data and the predictions made by machine learning algorithms trained for the purposes of socially sensitive decision processes.
We originally built this tool for internal use but the fundamental notion is so important (as Jeremy discussed in the ethics topic) that we decided to open-source the package to promote awareness and help others create models responsibly.
Feel free to take a look.
Re: Ethics
Thanks Rachel and Jeremy for highlighting these very important issues as we venture out onto the bleeding edge of data science.
One thing I’ve pondered is how we might address the issue of “fake news” that, at this point in time, continues to perpetuate and feedback loop as a result of the algorithms on Facebook and YouTube.
Off the top of my head, I wonder if this is a necessary use case for blockchains, i.e., cryptographic identity. It seems to me that otherwise literate people are not trained to spot the difference between algorithmically-generated news and information from humans, and the entire point of such news is to defeat that level of discrimination anyway. It would seem to me that we would need to move towards cryptographically-verified identity and propagate some form of news-flagging that verifies information sources as either definitely a person or possibly a bot. So far as I understand it, companies like Facebook and YouTube are not yet taking responsibility for the effects of their algorithms, in which case this seems like a possible solution.
Aside from this, and at the individual or small group level, I wonder if it’s prudent to create some sort of license that dictates that users of our data or source code must include disclaimers or links to information about ethics issues in data science. I’m not sure how effective this would be without some prosecutorial teeth, but there’s that.
Just leaving thoughts here as I haven’t found a dedicated category for this topic. Open to discussion and possibly separating this topic into its own category.
It’s possible i missed writing this down from a previous lecture, but what is the pct_start option in fit_one_cycle?
Check this out:
Having trouble with pip install isoweek. It’s saying my requirement is already satisfied in both the terminal and the notebook, but when I attempt to import it it’s saying there isn’t a module named isoweek:
ModuleNotFoundError: No module named ‘isoweek’
Any ideas? I’ve tried restarting the kernel and even shutting it down.
Inspired by Porto Seguro Winning Solution, I have created (mostly copied) a denoised autoencoder thanks to fast.ai lesson 6 about hooks!
ps. I am not sure if my solution is correct because It is kinda weird when the encoder and decoder aren’t symmetric.
Hi All,
I am having a bit difficulties with the following code:
data = (TabularList.from_df(df, path=PATH, cat_names=cat_vars, cont_names=cont_vars, procs=procs)
.split_by_idx(valid_idx)
.label_from_df(cols=dep_var, label_cls=FloatList, log=True)
.add_test(TabularList.from_df(test_df, path=PATH, cat_names=cat_vars, cont_names=cont_vars))
.databunch())
For some odd reason, the code above returns the following ValueError:
I haven’t been able to figure out the solution. Any help would be greatly appreciated!
Thanks!
Is it just me, the sound is missing at the start of every few sentences? Any chance of fixing this in future lectures? (great content by the way).
Hi all,
I had a question about the batch_norm layer described in the lecture. Why is this layer only applied to the continuous variables and not the embeddings created from the categorical variables (this is essentially a continuous representation of these variables if I understand correctly)
Thanks!
Hii All,
I started working on mitosis detection in breast histopathology Image using MITOS dataset. How should I make progress? Any help will be appreciable.
I am having the same issue with isoweek. Did you solve this?
Riley
I never did figure it out. I just removed that feature. I still got very similar prediction without it, although it wasn’t quite as good.
Thanks Nick,
Yeah, I wrote a method using datetime that did the same thing.Other than that i didn’t change anything, and ended up with slightly better accuracy metric
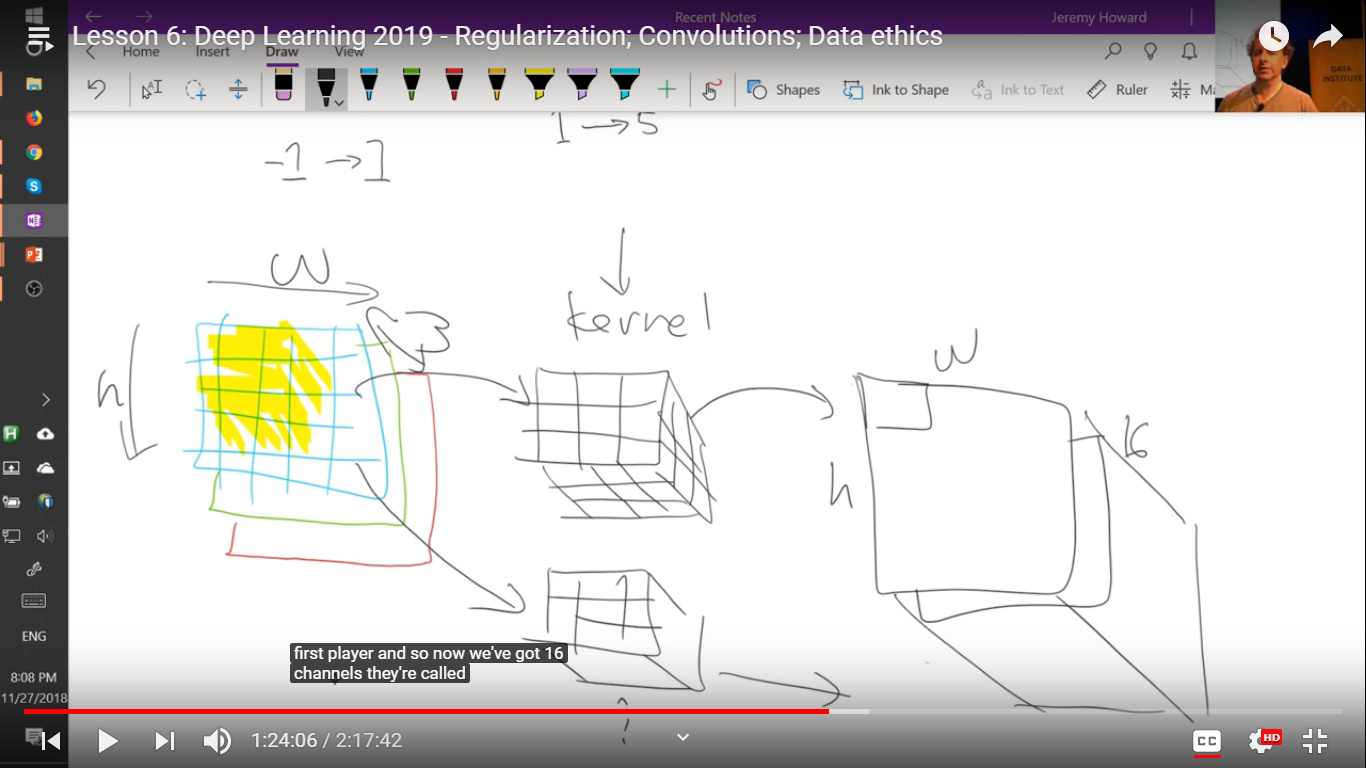
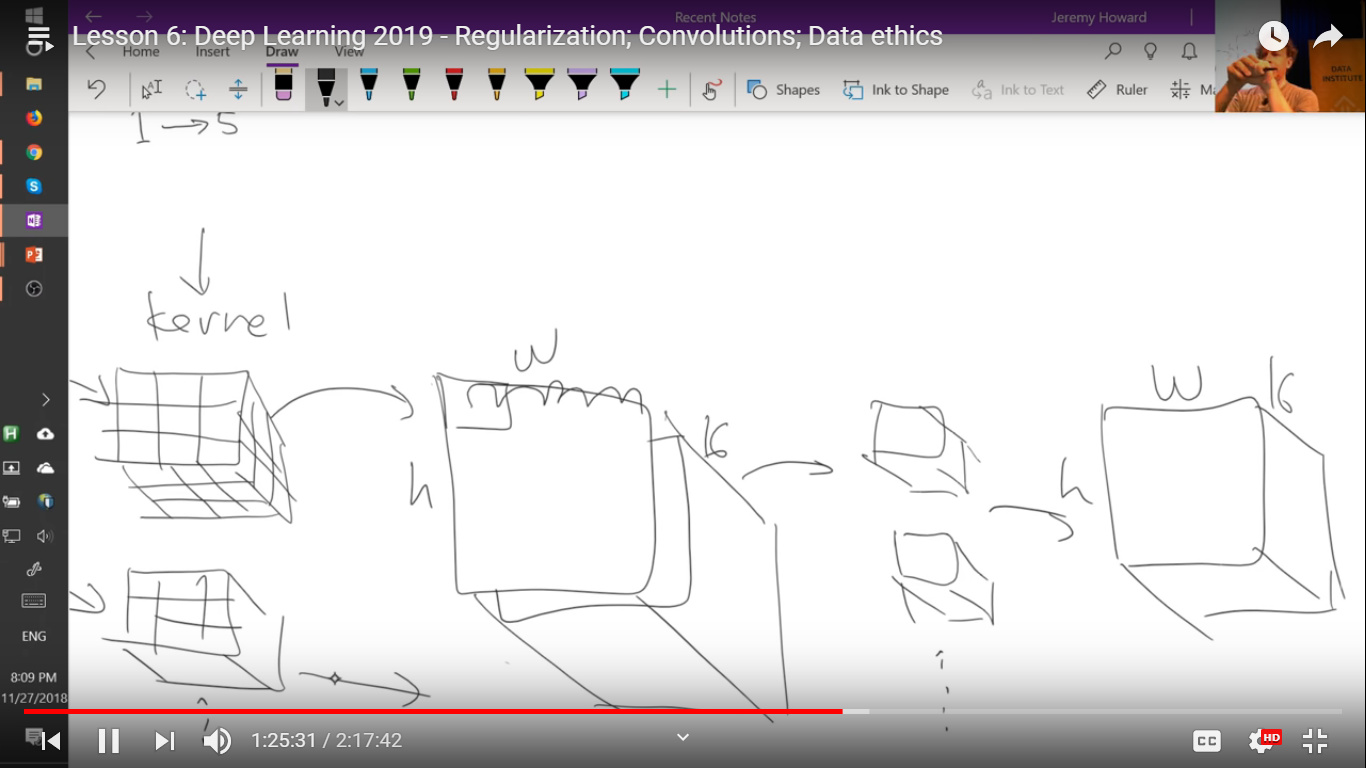
confusion regarding CNN layers. at the 1:26 mark in the video, the 2nd layer (h x w x 16) has 16 channels (as the 1st layer(h x w x 3) was multiplied by 16 image kernels(3 x 3 x 3) to produce 16 channels) . right?
Now, shouldn’t the 2nd layer (h x w x 16) be multiplied by image kernels of size 3 x 3 x 16 ( or i guess, X x Y x 16) so that we get from 1 image kernel we get 1 channel? I am asking because it wasn’t mentioned explicitly in the lecture.
t[None].shape
I don’t quite understand what he’s doing, Jeremy says:
I need to create a range 4 tensor where the first axis is 1. In other words, it’s a mini lot size 1, because that’s what PyTorch expects.
However, I still don’t understand it, what does this ‘axis 1’ do, and why do we need it ?
Any ideas? , thanks
The output of the convnet was a 37x1 vector, which was the result of a dot product between a 512x1 vector and a matrix 512x37. How did we get a 37x1 vector if the dimensions doesnt match?
Quick question.
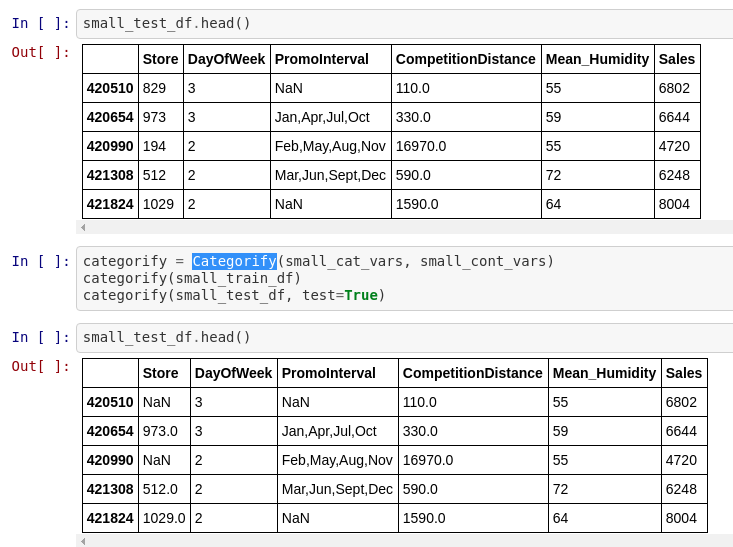
In https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson6-rossmann.ipynb how come the Store values change after running Categorify? Some become floats and others become NaNs
For anyone searching for where to find Jeremy’s detailed explanation of how the data for Rossmann competition is engineered in the rossman_data_clean.ipynb, here is a link for that: