The log error log(y) - log(yhat), this is the same as log(y / yhat).
We use the trick of adding 0: y / yhat is the same as y / yhat + (1 - yhat/yhat) which is the same as 1 + (y - yhat) / yhat where the second term is the percent error (PE).
So log(y) - log(yhat) is the same as log(1 + PE), which is approximately PE when PE is small (as you can verify with a plot).
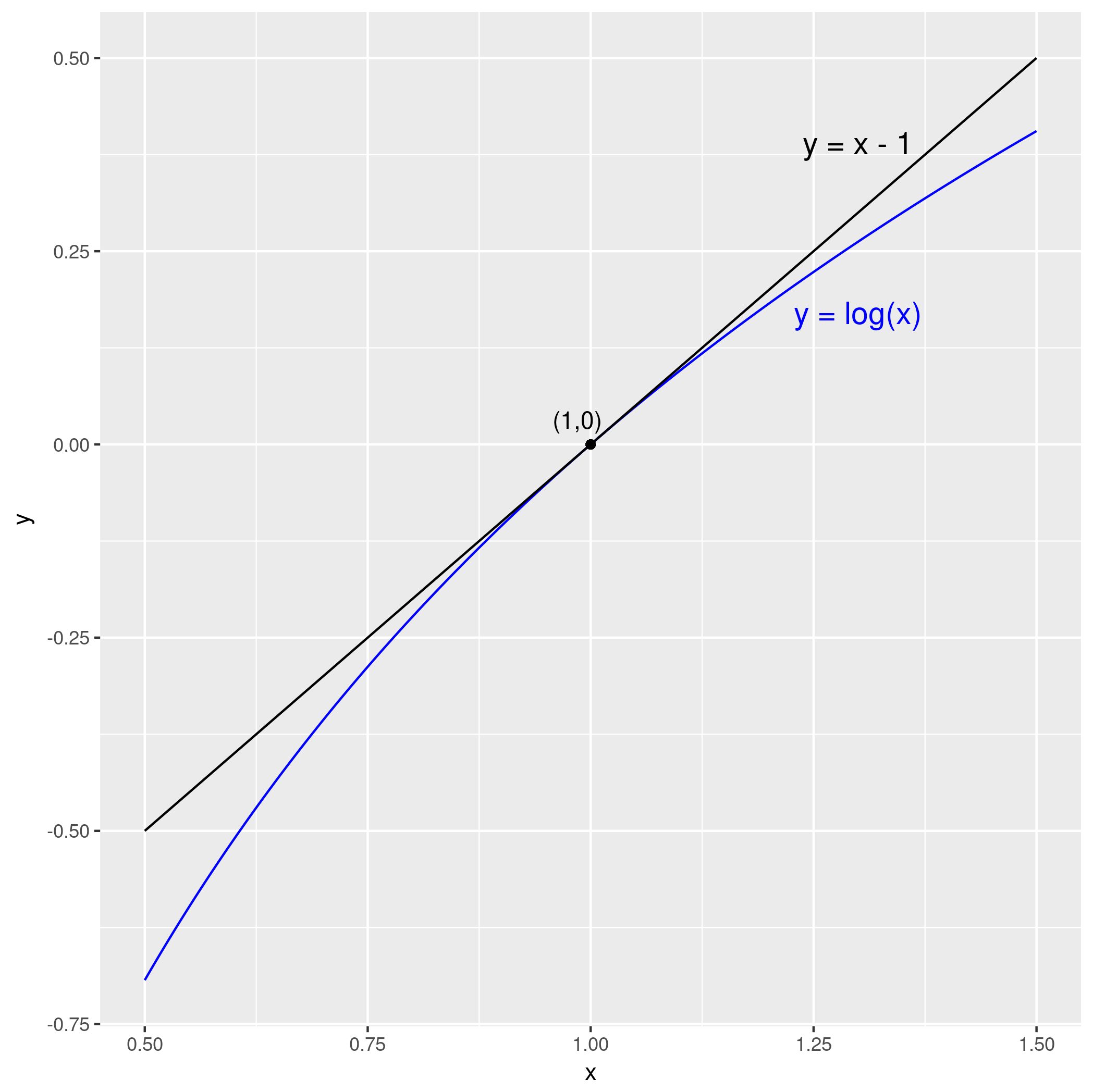
So log(y) - log(yhat) is approximately the same as (y - yhat) / yhat when either result is much smaller than 1.
So when your predictions are pretty good you get log error is almost the same as percent error, as you can verify experimentally, and you should get similar final model accuracy.