Quick question about the learning rate number:
I was under the impression that the learning rate had to be a relatively small number, usually 0.1 or smaller, and certainly less than 1, as of course you want to gradually descend the gradient and not jump to the other side of any minimums, however towards the end of the linear network set up the learning rate jumps up to 100. Any reason for this?
1 Like
I am working on the Titanic dataset and wanted to calculate the coefficients instead of generating random ones. I noticed inconsistencies with the results, so I created a notebook on Kaggle that I could share that demonstrates my problem. If I run the notebook, as is, the numbers seem to be consistent, but if I restart the kernel, then run it I get different numbers than before. I also demonstrate in this notebook that pandas, numpy, and pytorch each perform the same action differently. Who can I trust and why is there such diversity in answers?
notebook - Linear model and neural net from scratch
section - deep learning
code:
def calc_preds(coeffs, indeps):
layers,consts = coeffs
n = len(layers)
res = indeps
for i,l in enumerate(layers):
res = res@l + consts[i]
if i!=n-1: res = F.relu(res)
return torch.sigmoid(res)
Observation - it seems in calculating the predictions we are adding constant to each layer compared to the earlier parts in the notebook where we skipped adding constants to the first layer. As per jeremy it is not needed in the first layer (or leaner model) because we have dummy variables for each feature value.
Question - is this a mistake or there is a reason why we are adding constant to each layer including first in deep learning? or in bigger schema of things it doesn’t matter if we add constant to each layer for simplicity. you just don’t have to add it for first layer if we don’t want to.
1 Like
Here’s my Pytorch Titanic workbook for anyone else trying to reproduce it.
I learnt quite a lot going through this, although I couldn’t quite get the final deep learning section working which dropped to <60% accuracy.
Procs in TabularPandas function:
Can someone tell me functions in procs other than [Categorify, FillMissing, Normalize]. & by default FillMissing uses median replace NA values how can change it other like mean.
Exactly same question from me as maritanap.
Interested in any insights regarding the change from the single hidden layer in the Neural Network section not having the const added versus the two hidden layers in the Deep Learning section having the consts added.
I copied verbatim the code from the Titanic “frameworks” notebook and tried to apply it to the “Spaceship Titanic” Kaggle competition, but my neural net won’t train. Am I missing something?
If you try to run the lesson5 notebook locally on your computer (like I did), the latest version of pandas API has changed the default values of the get_dummies call from integers to bools dtype, which causes later steps to fail when creating a tensor:
pd.get_dummies(df, columns=["Sex","Pclass","Embarked"])
Change this to:
pd.get_dummies(df, columns=["Sex","Pclass","Embarked"], dtype=np.uint8)
I’m trying to understand Jeremy’s approach to scoring the binary split outputs
def _side_score(side, y):
tot = side.sum()
if tot<=1: return 0
return y[side].std()*tot
He mentioned that the lower score is better and that the score is not really valuable if the “side” is small, that’s why we multiply by tot.
But, if I understand correctly, small group with small standard deviation will actually get really small score, hence will be considered as “better” than a larger group with the same standard deviation.
Am I missing something? Shouldn’t we actually divide by tot instead of multiplying by it?
I think I was confused on the same point you have mentioned in this lesson but I think what resolved my confusion was that he defines score as the average of both sides:
def score(col, y, split):
lhs = col<=split
return (_side_score(lhs,y) + _side_score(~lhs,y))/len(y)
And so if a particular split causes one side (let’s say the left-hand side lhs) to be very small with a small standard deviation you are correct that it will have a small _side_score but then the right hand size being much larger will have a much larger _side_score. Taking the average of the two _side_scores takes into account such imbalances (from what I understood).
1 Like
In the ‘why you should use a framework’ notebook in the ensembling section
ens_preds = torch.stack(learns).mean(0)
The first five elements in the ens_preds gives
tensor([[0.8843, 0.1157],
[0.5729, 0.4271],
[0.9334, 0.0666],
[0.8949, 0.1051],
[0.2978, 0.7022]]))
I thought the predictions are for the classes [survived, not_survived]. but from the code:
tst_df[‘Survived’] = (ens_preds[:,1]>0.5).int()
It seems it’s rather [not_survived, survived], how can I confirm what it actually is.
I tried looking at the documentation for get_preds but didn’t understand it.
You can see the dependent (y) variable categories using dls.vocab like so:
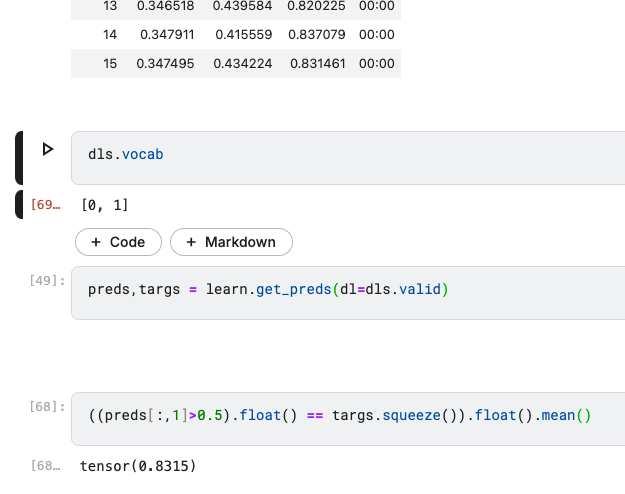
Thank you
1 Like
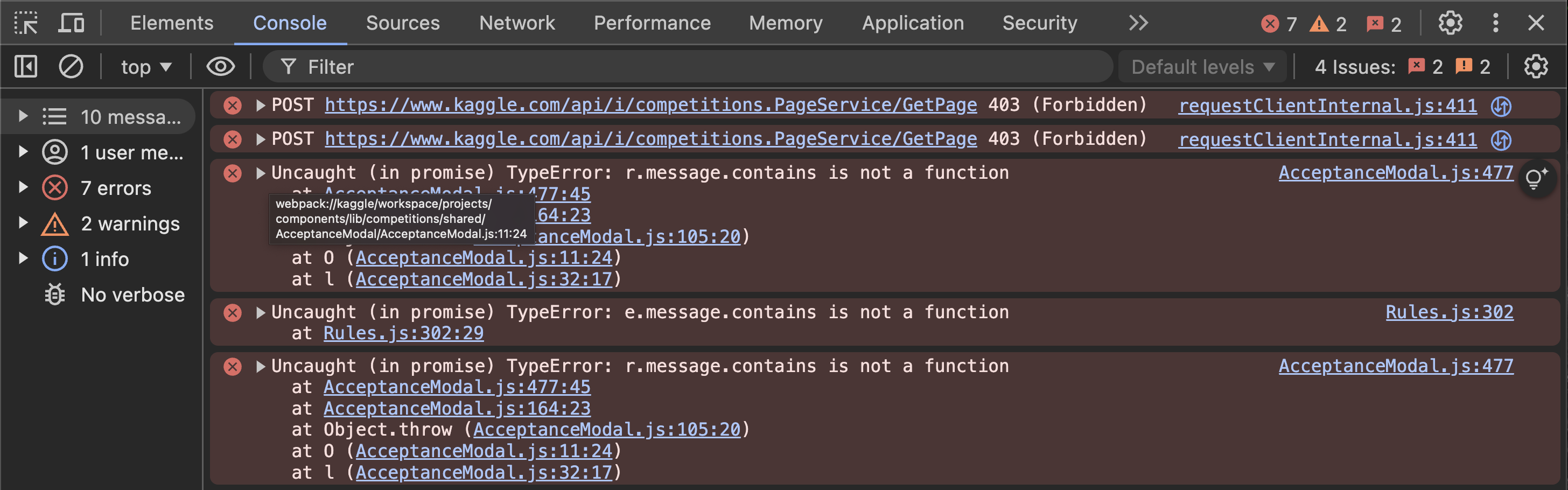
I know that others have had this problem, but I think it’s evolved over the years. I’m having trouble downloading ‘Blue Book for Bulldozers’ data. When I go to accept the rules of the competition at Blue Book for Bulldozers | Kaggle, nothing shows up. I shared the error I get in my console below (across browsers).
Is there any other way to access this data? Does someone have it saved somewhere?
I verified my phone number and identity on kaggle, so that’s not the issue.
1 Like
Hi, I wanted to let you know I have had the same issue. Were you able to solve your issue?
My best guess is that the “rules” of the competition are no longer able to be accepted. Kaggle requires accepting the rules of the competition to download data, but there does not seem to be an “accept rules” button on the rules page currently
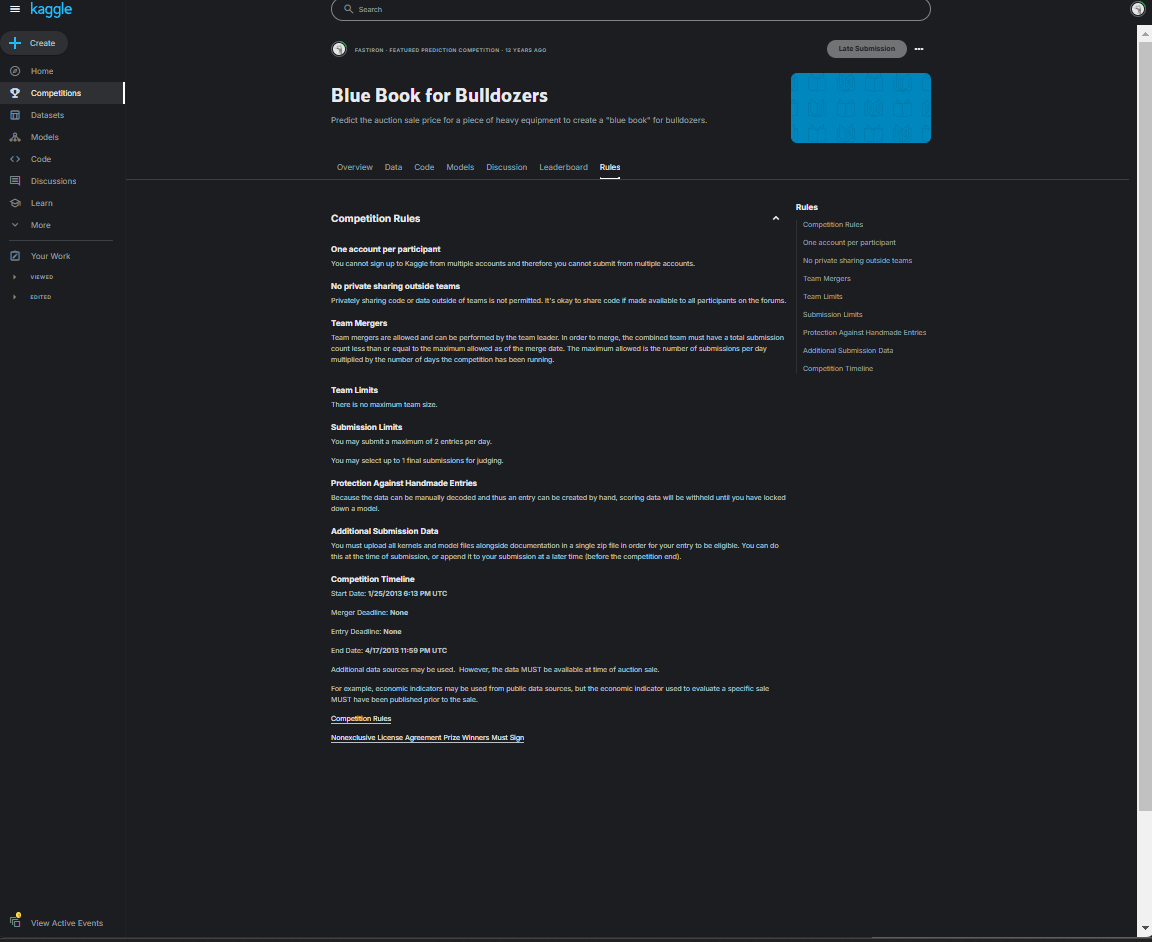
I am hoping someone can reply here with a solution, because it feels like the book chapter 9 is bricked if Kaggle’s data is inaccessible which feels a little inconvenient. Other issues I have come across on the forum seem to stem from API/Key issues, and I have verified that works on some other Kaggle pages (like the notebook from Lesson 4). I likewise confirmed my issue between Kaggle, CoLab, and a local jupyter notebook.
I may be missing something but my best guess is that by not being able to accept the rules, we don’t have permissions to download the data.
For anyone (and @leeps) also experiencing this issue with Kaggle for downloading the bulldozer data in chapter 9, this post contains a solution to the issue:
These are the instructions:
Really simple solution but really easy to overlook, especially when running the book digitally. I don’t know if anyone on the editorial team for the book follows up on these issues, but this may be one small thing to improve regarding the book experience.
My best guess as to why the code works in the video is that the default for get_dummies() dtype parameter was int at the time and that the default is now bool.
Your guess seems to be right! ![]() Source
Source