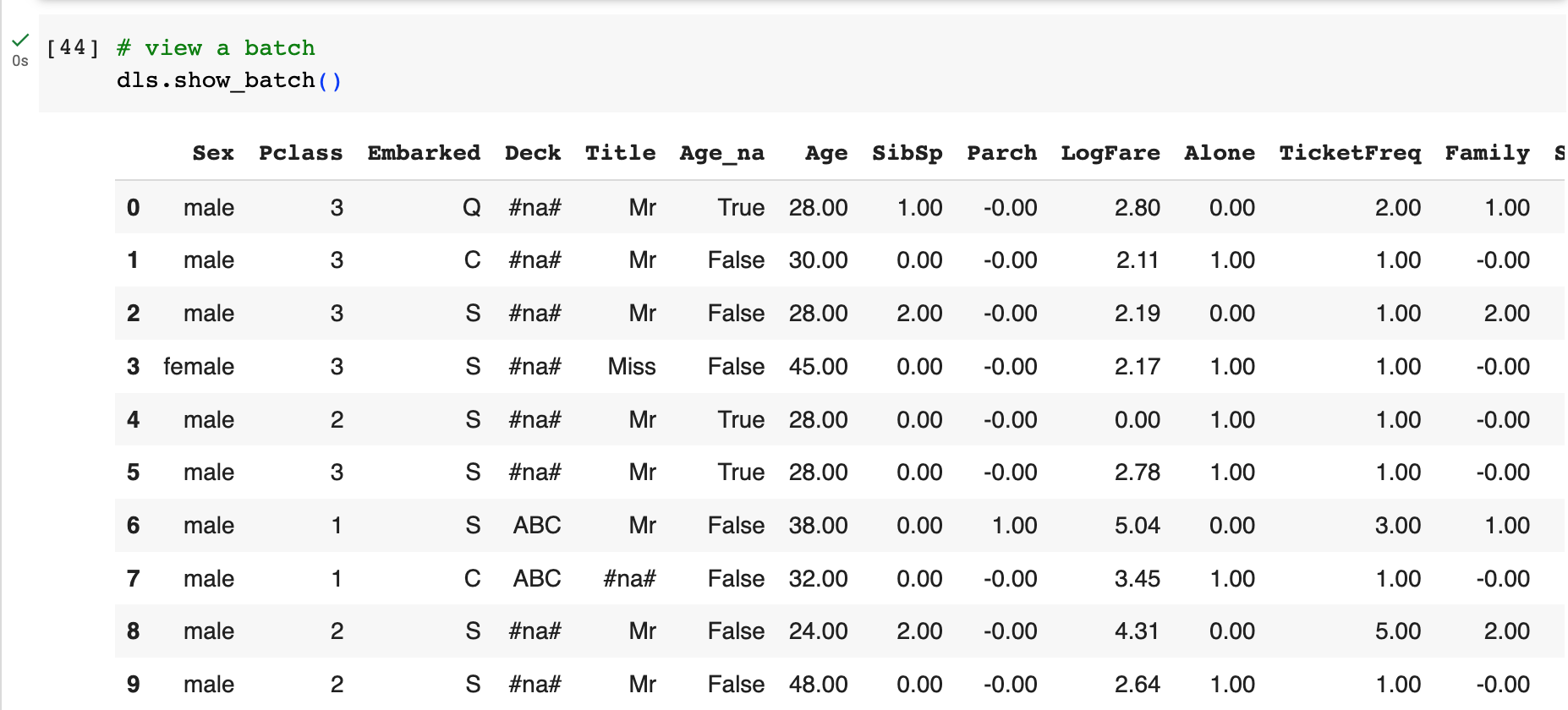
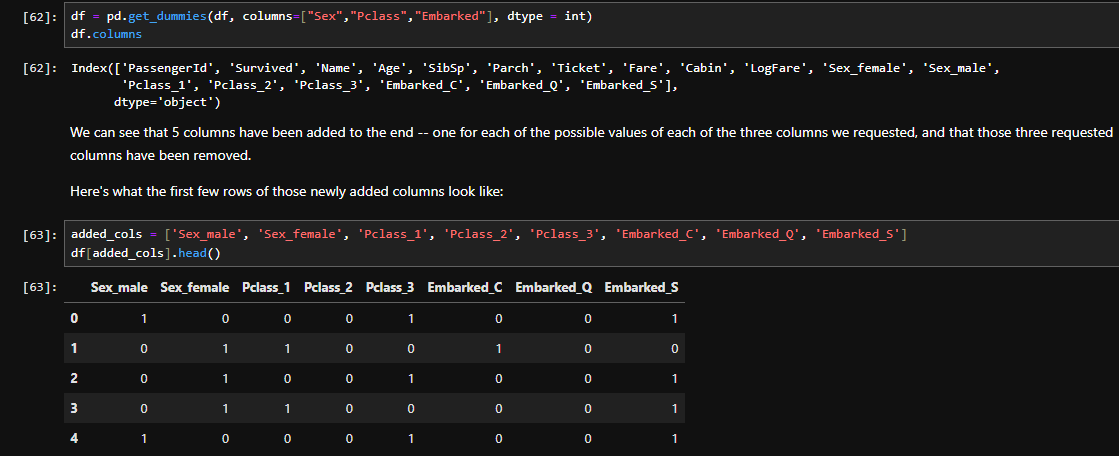
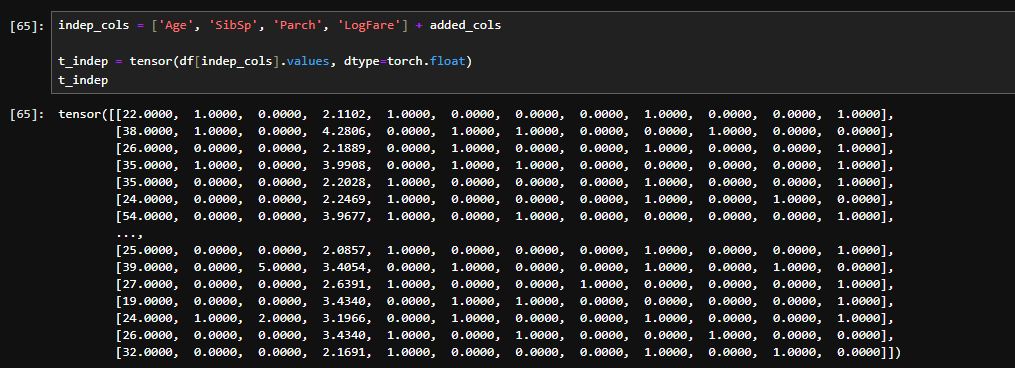
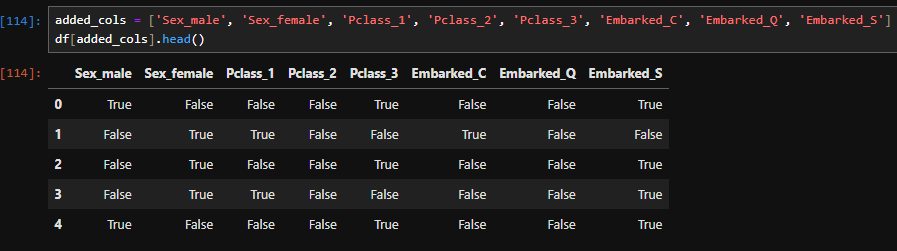
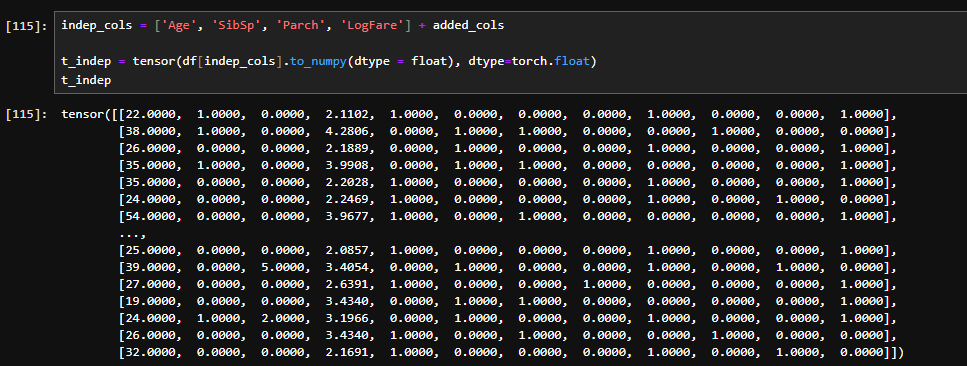
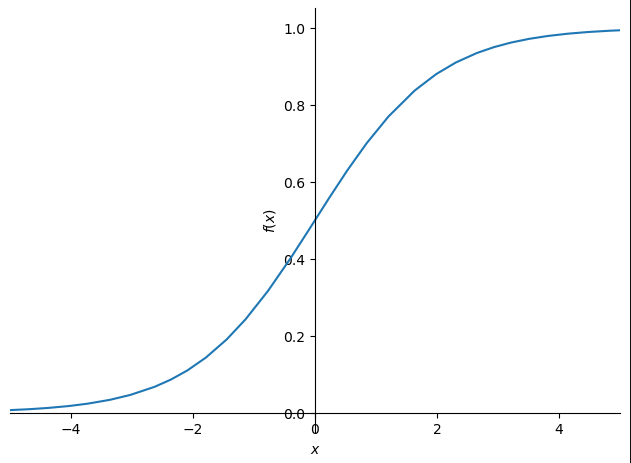
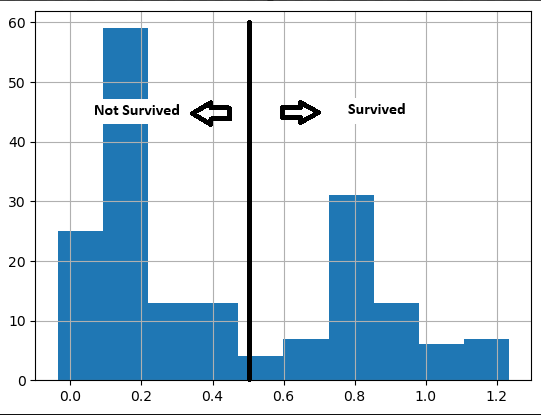
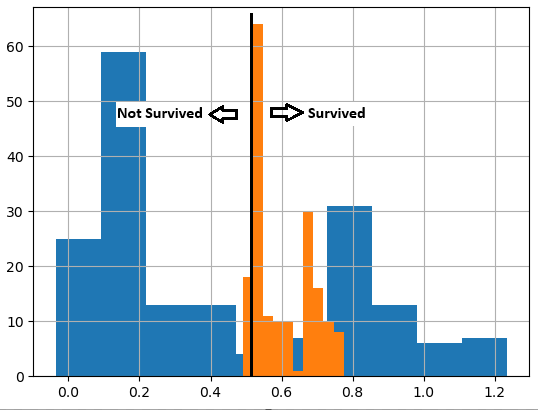
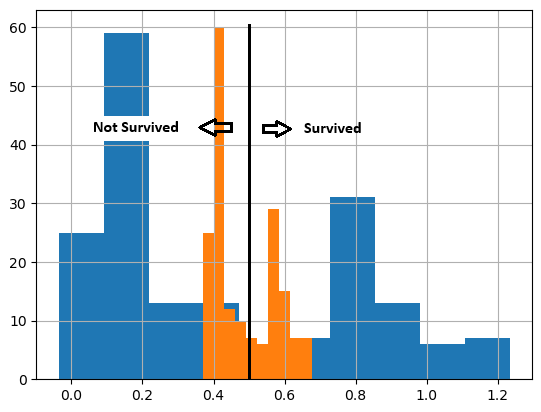
Think of it as a class being instantiated without storing it in a variable, and then you pass an argument directly to the instantiated class.
So instead of…
random_splitter = RandomSplitter(seed=42)
random_splitter(df)
…we’re doing…
RandomSplitter(seed=42)(df)